 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Reporter: Deep Research for Grounded Multimodal Long-Form Generation
Apr 12, 2026Recent agentic search frameworks enable deep research via iterative planning and retrieval, reducing hallucinations and enhancing factual grounding. However, they remain text-centric, overlooking the multimodal evidence that characterizes real-world expert reports. We introduce a pressing task: multimodal long-form generation. Accordingly, we propose Deep-Reporter, a unified agentic framework for grounded multimodal long-form generation. It orchestrates: (i) Agentic Multimodal Search and Filtering to retrieve and filter textual passages and information-dense visuals; (ii) Checklist-Guided Incremental Synthesis to ensure coherent image-text integration and optimal citation placement; and (iii) Recurrent Context Management to balance long-range coherence with local fluency. We develop a rigorous curation pipeline producing 8K high-quality agentic traces for model optimization. We further introduce M2LongBench, a comprehensive testbed comprising 247 research tasks across 9 domains and a stable multimodal sandbox. Extensive experiments demonstrate that long-form multimodal generation is a challenging task, especially in multimodal selection and integration, and effective post-training can bridge the gap.
Adaptor: Advancing Assistive Teleoperation with Few-Shot Learning and Cross-Operator Generalization
Apr 10, 2026Assistive teleoperation enhances efficiency via shared control, yet inter-operator variability, stemming from diverse habits and expertise, induces highly heterogeneous trajectory distributions that undermine intent recognition stability. We present Adaptor, a few-shot framework for robust cross-operator intent recognition. The Adaptor bridges the domain gap through two stages: (i) preprocessing, which models intent uncertainty by synthesizing trajectory perturbations via noise injection and performs geometry-aware keyframe extraction; and (ii) policy learning, which encodes the processed trajectories with an Intention Expert and fuses them with the pre-trained vision-language model context to condition an Action Expert for action generation. Experiments on real-world and simulated benchmarks demonstrate that Adaptor achieves state-of-the-art performance, improving success rates and efficiency over baselines. Moreover, the method exhibits low variance across operators with varying expertise, demonstrating robust cross-operator generalization.
AutoGCL: Automated Graph Contrastive Learning via Learnable View Generators
Sep 21, 2021
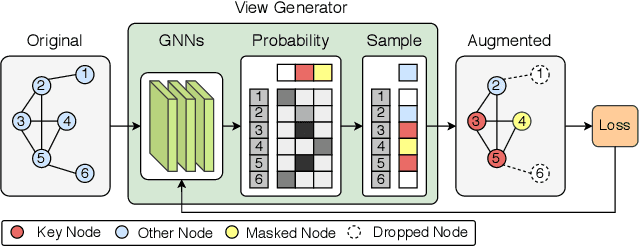
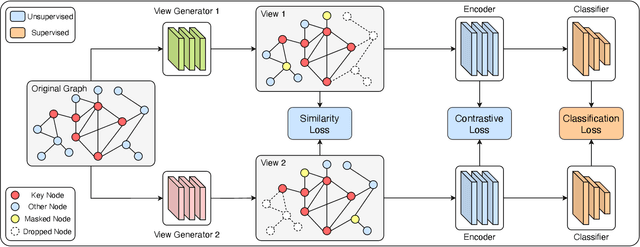
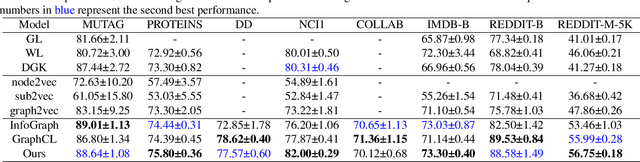
Contrastive learning has been widely applied to graph representation learning, where the view generators play a vital role in generating effective contrastive samples. Most of the existing contrastive learning methods employ pre-defined view generation methods, e.g., node drop or edge perturbation, which usually cannot adapt to input data or preserve the original semantic structures well. To address this issue, we propose a novel framework named Automated Graph Contrastive Learning (AutoGCL) in this paper. Specifically, AutoGCL employs a set of learnable graph view generators orchestrated by an auto augmentation strategy, where every graph view generator learns a probability distribution of graphs conditioned by the input. While the graph view generators in AutoGCL preserve the most representative structures of the original graph in generation of every contrastive sample, the auto augmentation learns policies to introduce adequate augmentation variances in the whole contrastive learning procedure. Furthermore, AutoGCL adopts a joint training strategy to train the learnable view generators, the graph encoder, and the classifier in an end-to-end manner, resulting in topological heterogeneity yet semantic similarity in the generation of contrastive samples. Extensive experiments on semi-supervised learning, unsupervised learning, and transfer learning demonstrate the superiority of our AutoGCL framework over the state-of-the-arts in graph contrastive learning. In addition, the visualization results further confirm that the learnable view generators can deliver more compact and semantically meaningful contrastive samples compared against the existing view generation methods.
BM-NAS: Bilevel Multimodal Neural Architecture Search
Apr 19, 2021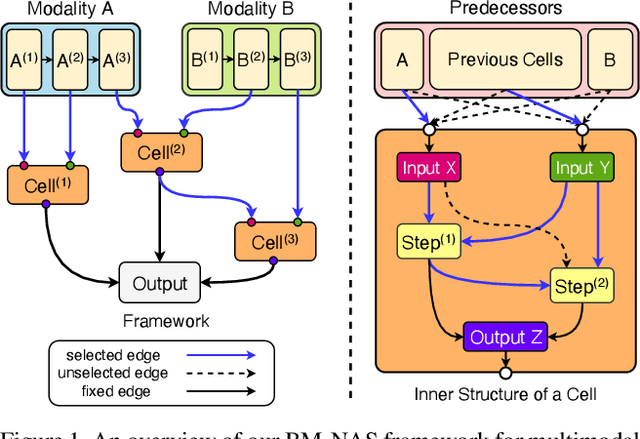
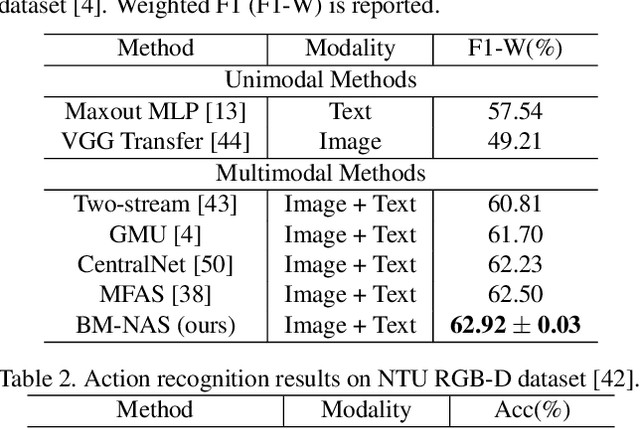
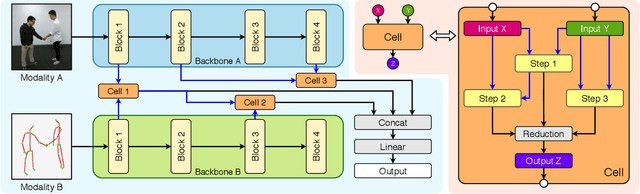
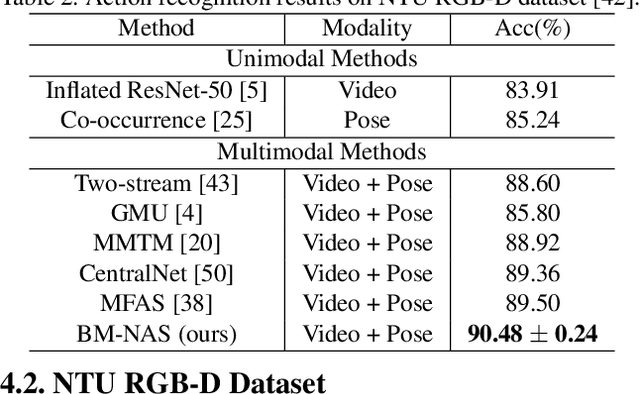
Deep neural networks (DNNs) have shown superior performances on various multimodal learning problems. However, it often requires huge efforts to adapt DNNs to individual multimodal tasks by manually engineering unimodal features and designing multimodal feature fusion strategies. This paper proposes Bilevel Multimodal Neural Architecture Search (BM-NAS) framework, which makes the architecture of multimodal fusion models fully searchable via a bilevel searching scheme. At the upper level, BM-NAS selects the inter/intra-modal feature pairs from the pretrained unimodal backbones. At the lower level, BM-NAS learns the fusion strategy for each feature pair, which is a combination of predefined primitive operations. The primitive operations are elaborately designed and they can be flexibly combined to accommodate various effective feature fusion modules such as multi-head attention (Transformer) and Attention on Attention (AoA). Experimental results on three multimodal tasks demonstrate the effectiveness and efficiency of the proposed BM-NAS framework. BM-NAS achieves competitive performances with much less search time and fewer model parameters in comparison with the existing generalized multimodal NAS methods.
Learning to Generate Diverse Dance Motions with Transformer
Aug 18, 2020
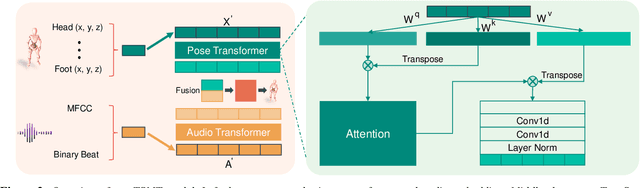

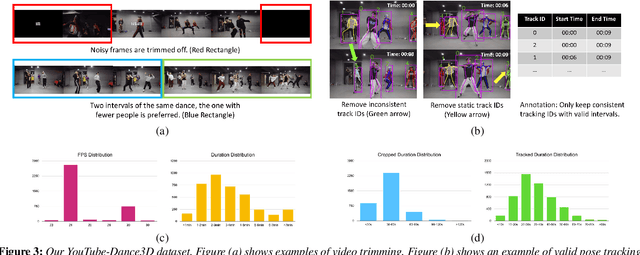
With the ongoing pandemic, virtual concerts and live events using digitized performances of musicians are getting traction on massive multiplayer online worlds. However, well choreographed dance movements are extremely complex to animate and would involve an expensive and tedious production process. In addition to the use of complex motion capture systems, it typically requires a collaborative effort between animators, dancers, and choreographers. We introduce a complete system for dance motion synthesis, which can generate complex and highly diverse dance sequences given an input music sequence. As motion capture data is limited for the range of dance motions and styles, we introduce a massive dance motion data set that is created from YouTube videos. We also present a novel two-stream motion transformer generative model, which can generate motion sequences with high flexibility. We also introduce new evaluation metrics for the quality of synthesized dance motions, and demonstrate that our system can outperform state-of-the-art methods. Our system provides high-quality animations suitable for large crowds for virtual concerts and can also be used as reference for professional animation pipelines. Most importantly, we show that vast online videos can be effective in training dance motion models.