 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
Towards Pixel-Level VLM Perception via Simple Points Prediction
Jan 27, 2026We present SimpleSeg, a strikingly simple yet highly effective approach to endow Multimodal Large Language Models (MLLMs) with native pixel-level perception. Our method reframes segmentation as a simple sequence generation problem: the model directly predicts sequences of points (textual coordinates) delineating object boundaries, entirely within its language space. To achieve high fidelity, we introduce a two-stage SF$\to$RL training pipeline, where Reinforcement Learning with an IoU-based reward refines the point sequences to accurately match ground-truth contours. We find that the standard MLLM architecture possesses a strong, inherent capacity for low-level perception that can be unlocked without any specialized architecture. On segmentation benchmarks, SimpleSeg achieves performance that is comparable to, and often surpasses, methods relying on complex, task-specific designs. This work lays out that precise spatial understanding can emerge from simple point prediction, challenging the prevailing need for auxiliary components and paving the way for more unified and capable VLMs. Homepage: https://simpleseg.github.io/
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
SoccerMaster: A Vision Foundation Model for Soccer Understanding
Dec 11, 2025Soccer understanding has recently garnered growing research interest due to its domain-specific complexity and unique challenges. Unlike prior works that typically rely on isolated, task-specific expert models, this work aims to propose a unified model to handle diverse soccer visual understanding tasks, ranging from fine-grained perception (e.g., athlete detection) to semantic reasoning (e.g., event classification). Specifically, our contributions are threefold: (i) we present SoccerMaster, the first soccer-specific vision foundation model that unifies diverse understanding tasks within a single framework via supervised multi-task pretraining; (ii) we develop an automated data curation pipeline to generate scalable spatial annotations, and integrate them with various existing soccer video datasets to construct SoccerFactory, a comprehensive pretraining data resource; and (iii) we conduct extensive evaluations demonstrating that SoccerMaster consistently outperforms task-specific expert models across diverse downstream tasks, highlighting its breadth and superiority. The data, code, and model will be publicly available.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
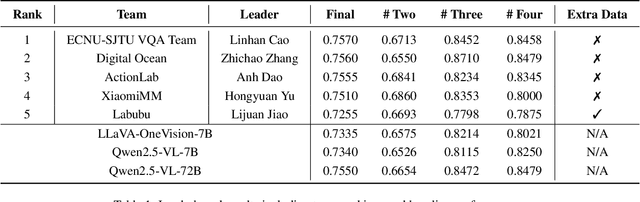
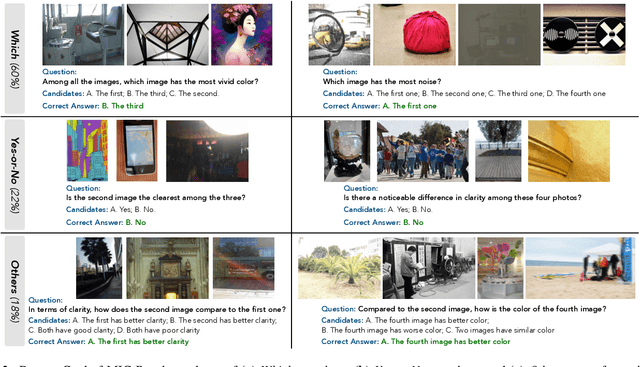
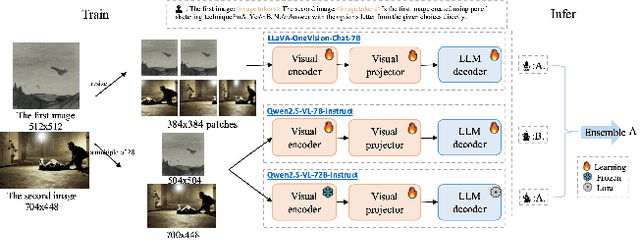
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?
May 29, 2025Recent studies have shown that long chain-of-thought (CoT) reasoning can significantly enhance the performance of large language models (LLMs) on complex tasks. However, this benefit is yet to be demonstrated in the domain of video understanding, since most existing benchmarks lack the reasoning depth required to demonstrate the advantages of extended CoT chains. While recent efforts have proposed benchmarks aimed at video reasoning, the tasks are often knowledge-driven and do not rely heavily on visual content. To bridge this gap, we introduce VideoReasonBench, a benchmark designed to evaluate vision-centric, complex video reasoning. To ensure visual richness and high reasoning complexity, each video in VideoReasonBench depicts a sequence of fine-grained operations on a latent state that is only visible in part of the video. The questions evaluate three escalating levels of video reasoning skills: recalling observed visual information, inferring the content of latent states, and predicting information beyond the video. Under such task setting, models have to precisely recall multiple operations in the video, and perform step-by-step reasoning to get correct final answers for these questions. Using VideoReasonBench, we comprehensively evaluate 18 state-of-the-art multimodal LLMs (MLLMs), finding that most perform poorly on complex video reasoning, e.g., GPT-4o achieves only 6.9% accuracy, while the thinking-enhanced Gemini-2.5-Pro significantly outperforms others with 56.0% accuracy. Our investigations on "test-time scaling" further reveal that extended thinking budget, while offering none or minimal benefits on existing video benchmarks, is essential for improving the performance on VideoReasonBench.
Scaling-up Perceptual Video Quality Assessment
May 28, 2025The data scaling law has been shown to significantly enhance the performance of large multi-modal models (LMMs) across various downstream tasks. However, in the domain of perceptual video quality assessment (VQA), the potential of scaling law remains unprecedented due to the scarcity of labeled resources and the insufficient scale of datasets. To address this, we propose \textbf{OmniVQA}, an efficient framework designed to efficiently build high-quality, human-in-the-loop VQA multi-modal instruction databases (MIDBs). We then scale up to create \textbf{OmniVQA-Chat-400K}, the largest MIDB in the VQA field concurrently. Our focus is on the technical and aesthetic quality dimensions, with abundant in-context instruction data to provide fine-grained VQA knowledge. Additionally, we have built the \textbf{OmniVQA-MOS-20K} dataset to enhance the model's quantitative quality rating capabilities. We then introduce a \textbf{complementary} training strategy that effectively leverages the knowledge from datasets for quality understanding and quality rating tasks. Furthermore, we propose the \textbf{OmniVQA-FG (fine-grain)-Benchmark} to evaluate the fine-grained performance of the models. Our results demonstrate that our models achieve state-of-the-art performance in both quality understanding and rating tasks.
SpatialScore: Towards Unified Evaluation for Multimodal Spatial Understanding
May 22, 2025Multimodal large language models (MLLMs) have achieved impressive success in question-answering tasks, yet their capabilities for spatial understanding are less explored. This work investigates a critical question: do existing MLLMs possess 3D spatial perception and understanding abilities? Concretely, we make the following contributions in this paper: (i) we introduce VGBench, a benchmark specifically designed to assess MLLMs for visual geometry perception, e.g., camera pose and motion estimation; (ii) we propose SpatialScore, the most comprehensive and diverse multimodal spatial understanding benchmark to date, integrating VGBench with relevant data from the other 11 existing datasets. This benchmark comprises 28K samples across various spatial understanding tasks, modalities, and QA formats, along with a carefully curated challenging subset, SpatialScore-Hard; (iii) we develop SpatialAgent, a novel multi-agent system incorporating 9 specialized tools for spatial understanding, supporting both Plan-Execute and ReAct reasoning paradigms; (iv) we conduct extensive evaluations to reveal persistent challenges in spatial reasoning while demonstrating the effectiveness of SpatialAgent. We believe SpatialScore will offer valuable insights and serve as a rigorous benchmark for the next evolution of MLLMs.
Multi-Agent System for Comprehensive Soccer Understanding
May 06, 2025Recent advancements in AI-driven soccer understanding have demonstrated rapid progress, yet existing research predominantly focuses on isolated or narrow tasks. To bridge this gap, we propose a comprehensive framework for holistic soccer understanding. Specifically, we make the following contributions in this paper: (i) we construct SoccerWiki, the first large-scale multimodal soccer knowledge base, integrating rich domain knowledge about players, teams, referees, and venues to enable knowledge-driven reasoning; (ii) we present SoccerBench, the largest and most comprehensive soccer-specific benchmark, featuring around 10K standardized multimodal (text, image, video) multi-choice QA pairs across 13 distinct understanding tasks, curated through automated pipelines and manual verification; (iii) we introduce SoccerAgent, a novel multi-agent system that decomposes complex soccer questions via collaborative reasoning, leveraging domain expertise from SoccerWiki and achieving robust performance; (iv) extensive evaluations and ablations that benchmark state-of-the-art MLLMs on SoccerBench, highlighting the superiority of our proposed agentic system. All data and code are publicly available at: https://jyrao.github.io/SoccerAgent/.