 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
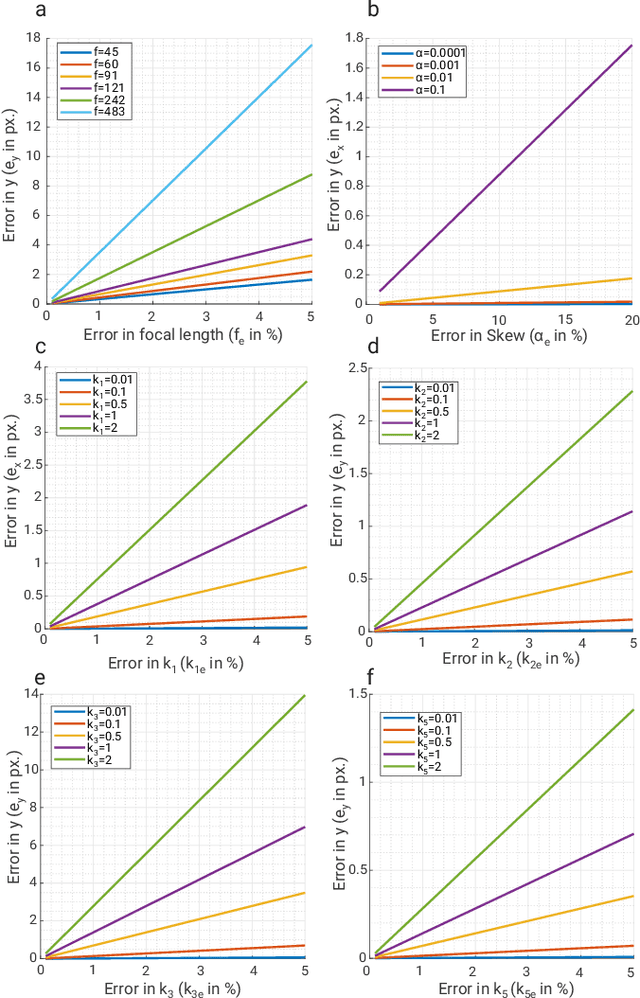
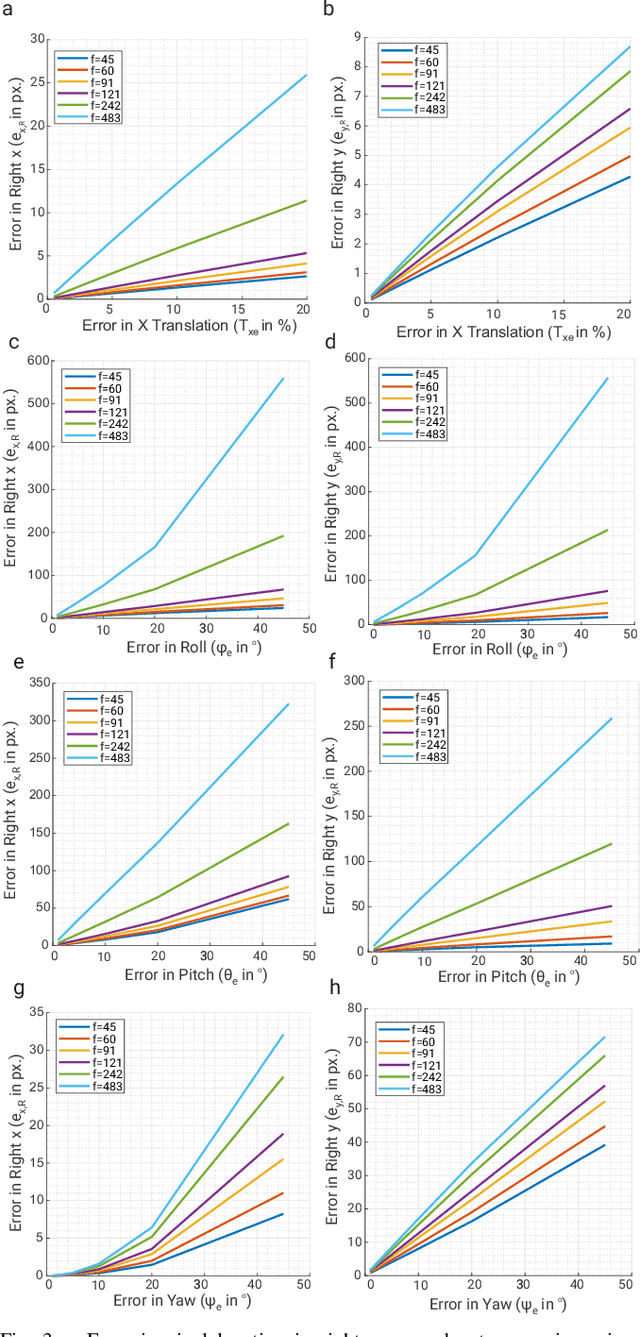
Add to EdgeCodedVO: Coded Visual Odometry
Jul 25, 2024



Autonomous robots often rely on monocular cameras for odometry estimation and navigation. However, the scale ambiguity problem presents a critical barrier to effective monocular visual odometry. In this paper, we present CodedVO, a novel monocular visual odometry method that overcomes the scale ambiguity problem by employing custom optics to physically encode metric depth information into imagery. By incorporating this information into our odometry pipeline, we achieve state-of-the-art performance in monocular visual odometry with a known scale. We evaluate our method in diverse indoor environments and demonstrate its robustness and adaptability. We achieve a 0.08m average trajectory error in odometry evaluation on the ICL-NUIM indoor odometry dataset.
* 7 pages, 4 figures, IEEE ROBOTICS AND AUTOMATION LETTERS
Active Human Pose Estimation via an Autonomous UAV Agent
Jul 01, 2024



One of the core activities of an active observer involves moving to secure a "better" view of the scene, where the definition of "better" is task-dependent. This paper focuses on the task of human pose estimation from videos capturing a person's activity. Self-occlusions within the scene can complicate or even prevent accurate human pose estimation. To address this, relocating the camera to a new vantage point is necessary to clarify the view, thereby improving 2D human pose estimation. This paper formalizes the process of achieving an improved viewpoint. Our proposed solution to this challenge comprises three main components: a NeRF-based Drone-View Data Generation Framework, an On-Drone Network for Camera View Error Estimation, and a Combined Planner for devising a feasible motion plan to reposition the camera based on the predicted errors for camera views. The Data Generation Framework utilizes NeRF-based methods to generate a comprehensive dataset of human poses and activities, enhancing the drone's adaptability in various scenarios. The Camera View Error Estimation Network is designed to evaluate the current human pose and identify the most promising next viewing angles for the drone, ensuring a reliable and precise pose estimation from those angles. Finally, the combined planner incorporates these angles while considering the drone's physical and environmental limitations, employing efficient algorithms to navigate safe and effective flight paths. This system represents a significant advancement in active 2D human pose estimation for an autonomous UAV agent, offering substantial potential for applications in aerial cinematography by improving the performance of autonomous human pose estimation and maintaining the operational safety and efficiency of UAVs.
CodedEvents: Optimal Point-Spread-Function Engineering for 3D-Tracking with Event Cameras
Jun 13, 2024



Point-spread-function (PSF) engineering is a well-established computational imaging technique that uses phase masks and other optical elements to embed extra information (e.g., depth) into the images captured by conventional CMOS image sensors. To date, however, PSF-engineering has not been applied to neuromorphic event cameras; a powerful new image sensing technology that responds to changes in the log-intensity of light. This paper establishes theoretical limits (Cram\'er Rao bounds) on 3D point localization and tracking with PSF-engineered event cameras. Using these bounds, we first demonstrate that existing Fisher phase masks are already near-optimal for localizing static flashing point sources (e.g., blinking fluorescent molecules). We then demonstrate that existing designs are sub-optimal for tracking moving point sources and proceed to use our theory to design optimal phase masks and binary amplitude masks for this task. To overcome the non-convexity of the design problem, we leverage novel implicit neural representation based parameterizations of the phase and amplitude masks. We demonstrate the efficacy of our designs through extensive simulations. We also validate our method with a simple prototype.
Microsaccade-inspired Event Camera for Robotics
May 28, 2024Neuromorphic vision sensors or event cameras have made the visual perception of extremely low reaction time possible, opening new avenues for high-dynamic robotics applications. These event cameras' output is dependent on both motion and texture. However, the event camera fails to capture object edges that are parallel to the camera motion. This is a problem intrinsic to the sensor and therefore challenging to solve algorithmically. Human vision deals with perceptual fading using the active mechanism of small involuntary eye movements, the most prominent ones called microsaccades. By moving the eyes constantly and slightly during fixation, microsaccades can substantially maintain texture stability and persistence. Inspired by microsaccades, we designed an event-based perception system capable of simultaneously maintaining low reaction time and stable texture. In this design, a rotating wedge prism was mounted in front of the aperture of an event camera to redirect light and trigger events. The geometrical optics of the rotating wedge prism allows for algorithmic compensation of the additional rotational motion, resulting in a stable texture appearance and high informational output independent of external motion. The hardware device and software solution are integrated into a system, which we call Artificial MIcrosaccade-enhanced EVent camera (AMI-EV). Benchmark comparisons validate the superior data quality of AMI-EV recordings in scenarios where both standard cameras and event cameras fail to deliver. Various real-world experiments demonstrate the potential of the system to facilitate robotics perception both for low-level and high-level vision tasks.
AcTExplore: Active Tactile Exploration on Unknown Objects
Oct 18, 2023


Tactile exploration plays a crucial role in understanding object structures for fundamental robotics tasks such as grasping and manipulation. However, efficiently exploring such objects using tactile sensors is challenging, primarily due to the large-scale unknown environments and limited sensing coverage of these sensors. To this end, we present AcTExplore, an active tactile exploration method driven by reinforcement learning for object reconstruction at scales that automatically explores the object surfaces in a limited number of steps. Through sufficient exploration, our algorithm incrementally collects tactile data and reconstructs 3D shapes of the objects as well, which can serve as a representation for higher-level downstream tasks. Our method achieves an average of 95.97% IoU coverage on unseen YCB objects while just being trained on primitive shapes. Project Webpage: https://prg.cs.umd$.$edu/AcTExplore
WorldGen: A Large Scale Generative Simulator
Oct 03, 2022
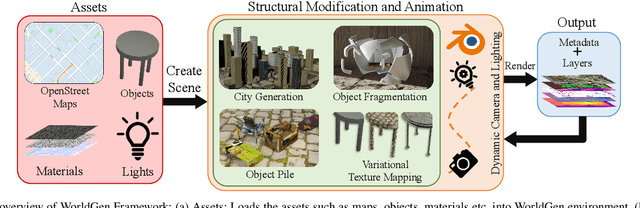
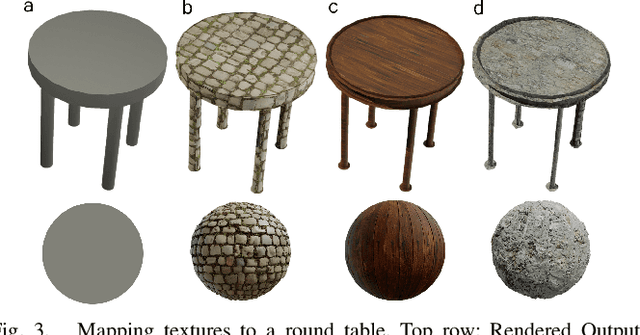
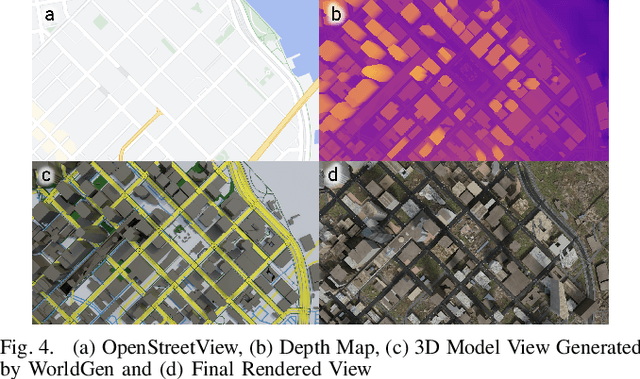
In the era of deep learning, data is the critical determining factor in the performance of neural network models. Generating large datasets suffers from various difficulties such as scalability, cost efficiency and photorealism. To avoid expensive and strenuous dataset collection and annotations, researchers have inclined towards computer-generated datasets. Although, a lack of photorealism and a limited amount of computer-aided data, has bounded the accuracy of network predictions. To this end, we present WorldGen -- an open source framework to autonomously generate countless structured and unstructured 3D photorealistic scenes such as city view, object collection, and object fragmentation along with its rich ground truth annotation data. WorldGen being a generative model gives the user full access and control to features such as texture, object structure, motion, camera and lens properties for better generalizability by diminishing the data bias in the network. We demonstrate the effectiveness of WorldGen by presenting an evaluation on deep optical flow. We hope such a tool can open doors for future research in a myriad of domains related to robotics and computer vision by reducing manual labor and the cost of acquiring rich and high-quality data.
NudgeSeg: Zero-Shot Object Segmentation by Repeated Physical Interaction
Sep 22, 2021
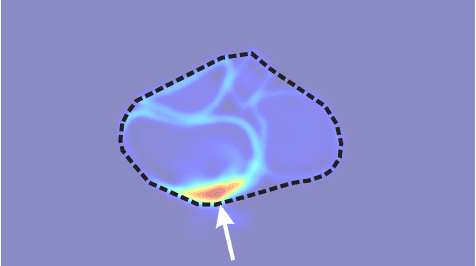
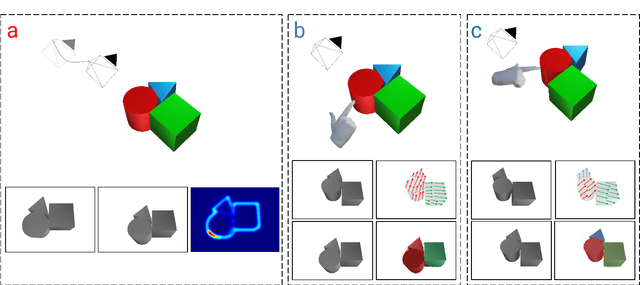

Recent advances in object segmentation have demonstrated that deep neural networks excel at object segmentation for specific classes in color and depth images. However, their performance is dictated by the number of classes and objects used for training, thereby hindering generalization to never seen objects or zero-shot samples. To exacerbate the problem further, object segmentation using image frames rely on recognition and pattern matching cues. Instead, we utilize the 'active' nature of a robot and their ability to 'interact' with the environment to induce additional geometric constraints for segmenting zero-shot samples. In this paper, we present the first framework to segment unknown objects in a cluttered scene by repeatedly 'nudging' at the objects and moving them to obtain additional motion cues at every step using only a monochrome monocular camera. We call our framework NudgeSeg. These motion cues are used to refine the segmentation masks. We successfully test our approach to segment novel objects in various cluttered scenes and provide an extensive study with image and motion segmentation methods. We show an impressive average detection rate of over 86% on zero-shot objects.
* 8 Pages, 7 Figures, 3 Tables
EVPropNet: Detecting Drones By Finding Propellers For Mid-Air Landing And Following
Jun 29, 2021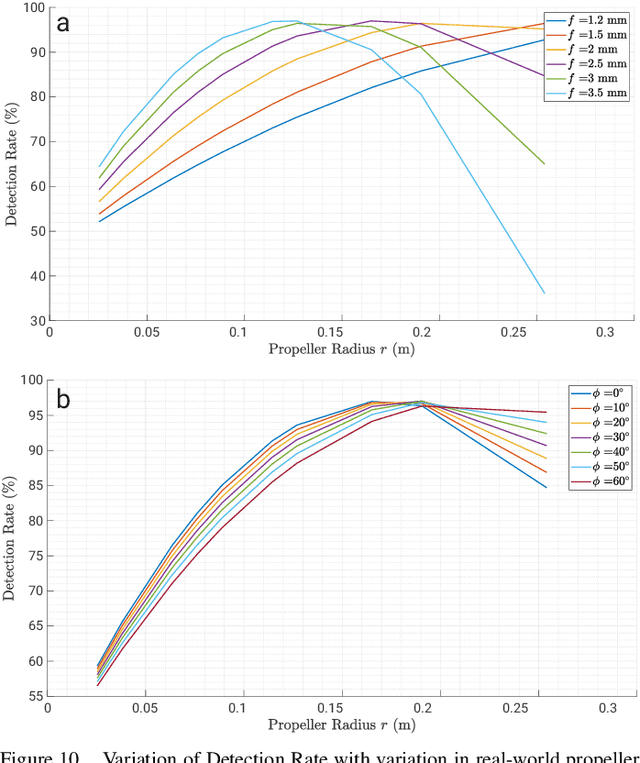
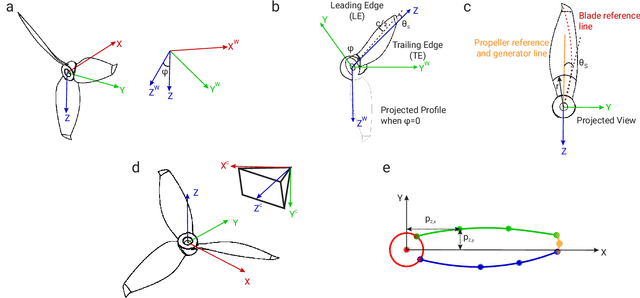
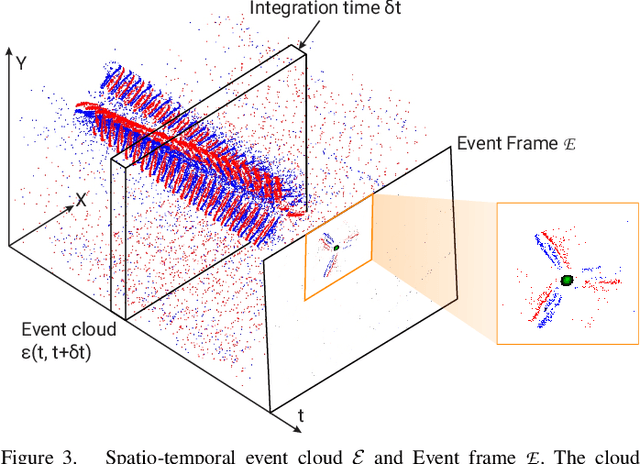
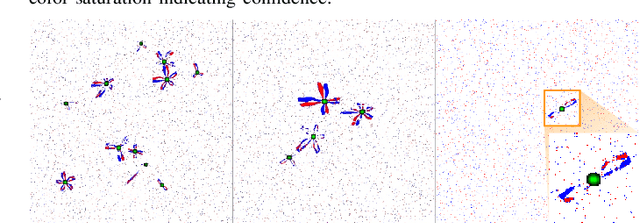
The rapid rise of accessibility of unmanned aerial vehicles or drones pose a threat to general security and confidentiality. Most of the commercially available or custom-built drones are multi-rotors and are comprised of multiple propellers. Since these propellers rotate at a high-speed, they are generally the fastest moving parts of an image and cannot be directly "seen" by a classical camera without severe motion blur. We utilize a class of sensors that are particularly suitable for such scenarios called event cameras, which have a high temporal resolution, low-latency, and high dynamic range. In this paper, we model the geometry of a propeller and use it to generate simulated events which are used to train a deep neural network called EVPropNet to detect propellers from the data of an event camera. EVPropNet directly transfers to the real world without any fine-tuning or retraining. We present two applications of our network: (a) tracking and following an unmarked drone and (b) landing on a near-hover drone. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with different propeller shapes and sizes. Our network can detect propellers at a rate of 85.1% even when 60% of the propeller is occluded and can run at upto 35Hz on a 2W power budget. To our knowledge, this is the first deep learning-based solution for detecting propellers (to detect drones). Finally, our applications also show an impressive success rate of 92% and 90% for the tracking and landing tasks respectively.
MorphEyes: Variable Baseline Stereo For Quadrotor Navigation
Nov 05, 2020
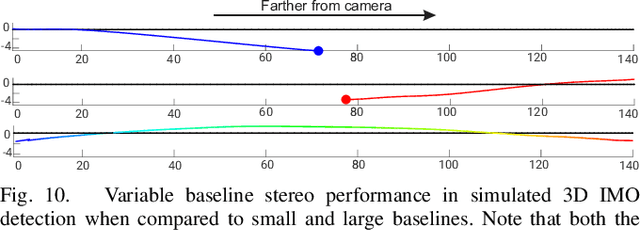
Morphable design and depth-based visual control are two upcoming trends leading to advancements in the field of quadrotor autonomy. Stereo-cameras have struck the perfect balance of weight and accuracy of depth estimation but suffer from the problem of depth range being limited and dictated by the baseline chosen at design time. In this paper, we present a framework for quadrotor navigation based on a stereo camera system whose baseline can be adapted on-the-fly. We present a method to calibrate the system at a small number of discrete baselines and interpolate the parameters for the entire baseline range. We present an extensive theoretical analysis of calibration and synchronization errors. We showcase three different applications of such a system for quadrotor navigation: (a) flying through a forest, (b) flying through an unknown shaped/location static/dynamic gap, and (c) accurate 3D pose detection of an independently moving object. We show that our variable baseline system is more accurate and robust in all three scenarios. To our knowledge, this is the first work that applies the concept of morphable design to achieve a variable baseline stereo vision system on a quadrotor.
PRGFlow: Benchmarking SWAP-Aware Unified Deep Visual Inertial Odometry
Jun 11, 2020
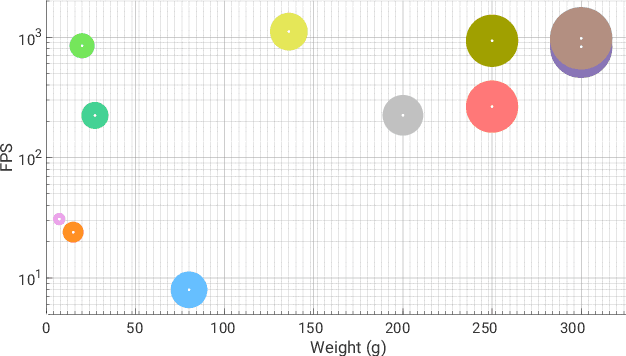
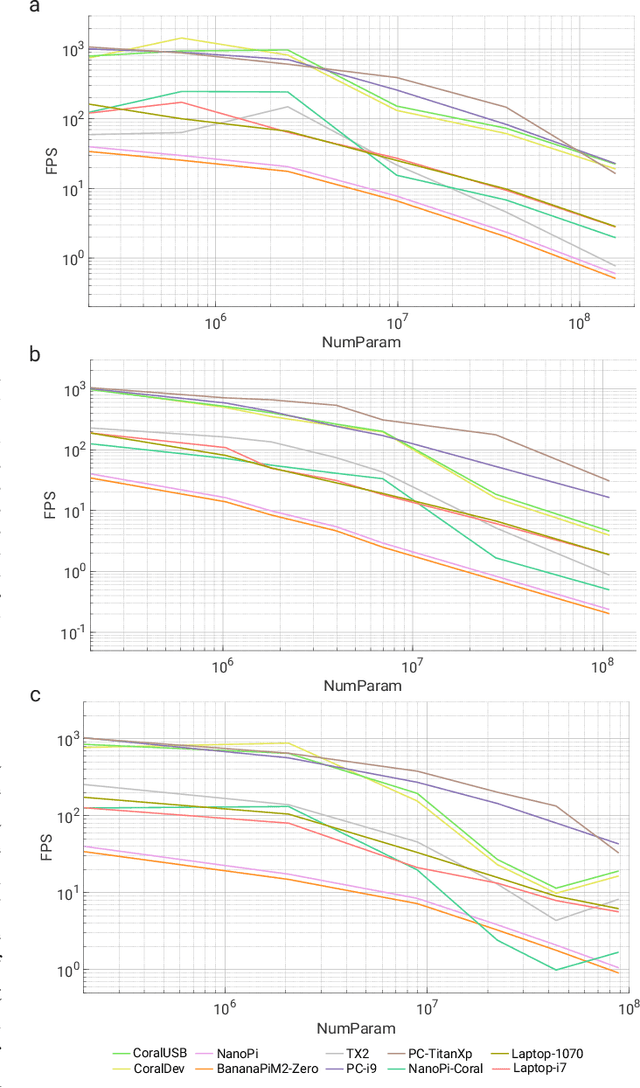
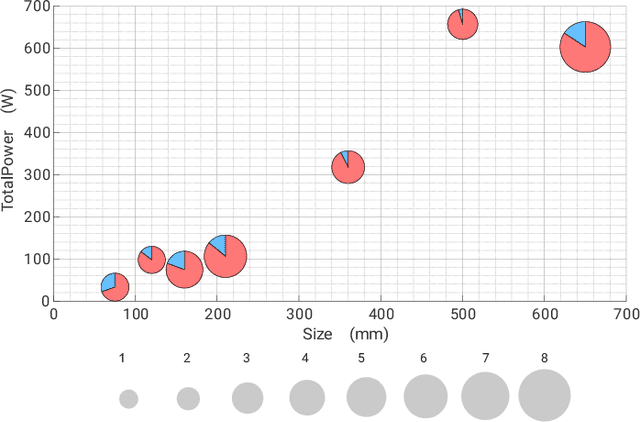
Odometry on aerial robots has to be of low latency and high robustness whilst also respecting the Size, Weight, Area and Power (SWAP) constraints as demanded by the size of the robot. A combination of visual sensors coupled with Inertial Measurement Units (IMUs) has proven to be the best combination to obtain robust and low latency odometry on resource-constrained aerial robots. Recently, deep learning approaches for Visual Inertial fusion have gained momentum due to their high accuracy and robustness. However, the remarkable advantages of these techniques are their inherent scalability (adaptation to different sized aerial robots) and unification (same method works on different sized aerial robots) by utilizing compression methods and hardware acceleration, which have been lacking from previous approaches. To this end, we present a deep learning approach for visual translation estimation and loosely fuse it with an Inertial sensor for full 6DoF odometry estimation. We also present a detailed benchmark comparing different architectures, loss functions and compression methods to enable scalability. We evaluate our network on the MSCOCO dataset and evaluate the VI fusion on multiple real-flight trajectories.