 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISE: An Execution-Grounded Recipe for Multi-Turn OS-Agent Trajectories
Jun 09, 2026Training capable OS agents requires data that simultaneously captures structured user intents, multi-turn task delegation, and grounded tool execution--properties absent from existing datasets. We propose ISE (Intent -> Simulate -> Execute), a three-stage synthesis paradigm that addresses these gaps jointly. Stage 1 constructs roughly 50000 structured intents via a 4D framework (Persona x Domain x Task x Complexity); after deduplication the pool contains 43956 unique intents and attains a Vendi Score of 61.57 over the entire pool on mpnet-base-v2 embeddings (cosine kernel, q=1). Stage 2 drives multi-turn user-agent interaction through a role-locked user simulator that grounds each user turn in actual execution outcomes, producing 23132 complete trajectories averaging 8.12 user turns and 68.24 total dialogue turns. Stage 3 runs every tool call inside a live, isolated OS workspace, generating authentic failure-recovery dynamics instead of simulated responses. Fine-tuning on ISETrace improves ClawEval pass@1 from 19.3 to 37.7 using Qwen3-8B on agent tool-use tasks with a standard protocol. This result outperforms zero-shot GPT-4o and the larger Qwen3-32B base model which is four times bigger. An ablation on Stage 2 proves multi-turn simulation brings a large portion of the performance gain. We release all source code and dataset at https://github.com/Valiere01/ISE-Trace.
Exponentially Consistent Low-Complexity Outlier Hypothesis Testing for Continuous Sequences
Jan 27, 2026In this work, we revisit outlier hypothesis testing and propose exponentially consistent, low-complexity fixed-length tests that achieve a better tradeoff between detection performance and computational complexity than existing exhaustive-search methods. In this setting, the goal is to identify outlying sequences from a set of observed sequences, where most sequences are i.i.d. from a nominal distribution and outliers are i.i.d. from a different anomalous distribution. While prior work has primarily focused on discrete-valued sequences, we extend the results of Bu et al. (TSP 2019) to continuous-valued sequences and develop a distribution-free test based on the MMD metric. Our framework handles both known and unknown numbers of outliers. In the unknown-count case, we bound the detection performance and characterize the tradeoff among the exponential decay rates of three types of error probabilities. Finally, we quantify the performance penalty incurred when the number of outliers is unknown.
Large Deviations for Sequential Tests of Statistical Sequence Matching
Jun 04, 2025We revisit the problem of statistical sequence matching initiated by Unnikrishnan (TIT 2015) and derive theoretical performance guarantees for sequential tests that have bounded expected stopping times. Specifically, in this problem, one is given two databases of sequences and the task is to identify all matched pairs of sequences. In each database, each sequence is generated i.i.d. from a distinct distribution and a pair of sequences is said matched if they are generated from the same distribution. The generating distribution of each sequence is \emph{unknown}. We first consider the case where the number of matches is known and derive the exact exponential decay rate of the mismatch (error) probability, a.k.a. the mismatch exponent, under each hypothesis for optimal sequential tests. Our results reveal the benefit of sequentiality by showing that optimal sequential tests have larger mismatch exponent than fixed-length tests by Zhou \emph{et al.} (TIT 2024). Subsequently, we generalize our achievability result to the case of unknown number of matches. In this case, two additional error probabilities arise: false alarm and false reject probabilities. We propose a corresponding sequential test, show that the test has bounded expected stopping time under certain conditions, and characterize the tradeoff among the exponential decay rates of three error probabilities. Furthermore, we reveal the benefit of sequentiality over the two-step fixed-length test by Zhou \emph{et al.} (TIT 2024) and propose an one-step fixed-length test that has no worse performance than the fixed-length test by Zhou \emph{et al.} (TIT 2024). When specialized to the case where either database contains a single sequence, our results specialize to large deviations of sequential tests for statistical classification, the binary case of which was recently studied by Hsu, Li and Wang (ITW 2022).
OphCLIP: Hierarchical Retrieval-Augmented Learning for Ophthalmic Surgical Video-Language Pretraining
Nov 23, 2024



Surgical practice involves complex visual interpretation, procedural skills, and advanced medical knowledge, making surgical vision-language pretraining (VLP) particularly challenging due to this complexity and the limited availability of annotated data. To address the gap, we propose OphCLIP, a hierarchical retrieval-augmented vision-language pretraining framework specifically designed for ophthalmic surgical workflow understanding. OphCLIP leverages the OphVL dataset we constructed, a large-scale and comprehensive collection of over 375K hierarchically structured video-text pairs with tens of thousands of different combinations of attributes (surgeries, phases/operations/actions, instruments, medications, as well as more advanced aspects like the causes of eye diseases, surgical objectives, and postoperative recovery recommendations, etc). These hierarchical video-text correspondences enable OphCLIP to learn both fine-grained and long-term visual representations by aligning short video clips with detailed narrative descriptions and full videos with structured titles, capturing intricate surgical details and high-level procedural insights, respectively. Our OphCLIP also designs a retrieval-augmented pretraining framework to leverage the underexplored large-scale silent surgical procedure videos, automatically retrieving semantically relevant content to enhance the representation learning of narrative videos. Evaluation across 11 datasets for phase recognition and multi-instrument identification shows OphCLIP's robust generalization and superior performance.
Exponentially Consistent Statistical Classification of Continuous Sequences with Distribution Uncertainty
Oct 29, 2024In multiple classification, one aims to determine whether a testing sequence is generated from the same distribution as one of the M training sequences or not. Unlike most of existing studies that focus on discrete-valued sequences with perfect distribution match, we study multiple classification for continuous sequences with distribution uncertainty, where the generating distributions of the testing and training sequences deviate even under the true hypothesis. In particular, we propose distribution free tests and prove that the error probabilities of our tests decay exponentially fast for three different test designs: fixed-length, sequential, and two-phase tests. We first consider the simple case without the null hypothesis, where the testing sequence is known to be generated from a distribution close to the generating distribution of one of the training sequences. Subsequently, we generalize our results to a more general case with the null hypothesis by allowing the testing sequence to be generated from a distribution that is vastly different from the generating distributions of all training sequences.
A Multi-class Ride-hailing Service Subsidy System Utilizing Deep Causal Networks
Aug 04, 2024



In the ride-hailing industry, subsidies are predominantly employed to incentivize consumers to place more orders, thereby fostering market growth. Causal inference techniques are employed to estimate the consumer elasticity with different subsidy levels. However, the presence of confounding effects poses challenges in achieving an unbiased estimate of the uplift effect. We introduce a consumer subsidizing system to capture relationships between subsidy propensity and the treatment effect, which proves effective while maintaining a lightweight online environment.
Collaborative Secret and Covert Communications for Multi-User Multi-Antenna Uplink UAV Systems: Design and Optimization
Jul 08, 2024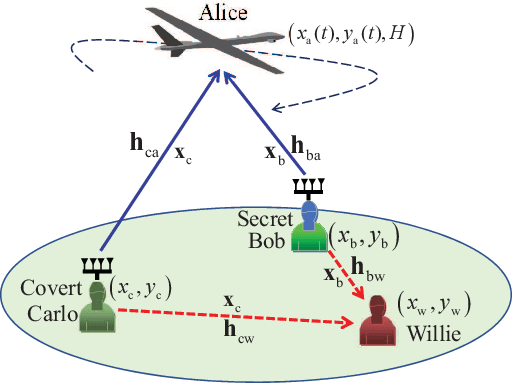
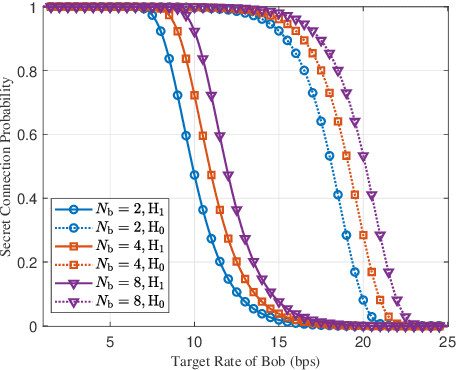
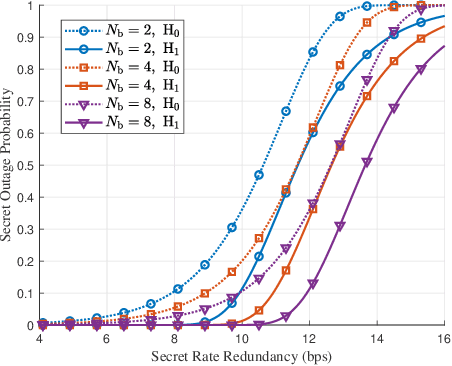
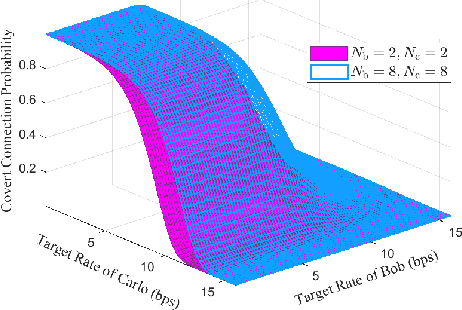
Motivated by diverse secure requirements of multi-user in UAV systems, we propose a collaborative secret and covert transmission method for multi-antenna ground users to unmanned aerial vehicle (UAV) communications. Specifically, based on the power domain non-orthogonal multiple access (NOMA), two ground users with distinct security requirements, named Bob and Carlo, superimpose their signals and transmit the combined signal to the UAV named Alice. An adversary Willie attempts to simultaneously eavesdrop Bob's confidential message and detect whether Carlo is transmitting or not. We derive close-form expressions of the secrecy connection probability (SCP) and the covert connection probability (CCP) to evaluate the link reliability for wiretap and covert transmissions, respectively. Furthermore, we bound the secrecy outage probability (SOP) from Bob to Alice and the detection error probability (DEP) of Willie to evaluate the link security for wiretap and covert transmissions, respectively. To characterize the theoretical benchmark of the above model, we formulate a weighted multi-objective optimization problem to maximize the average of secret and covert transmission rates subject to constraints SOP, DEP, the beamformers of Bob and Carlo, and UAV trajectory parameters. To solve the optimization problem, we propose an iterative optimization algorithm using successive convex approximation and block coordinate descent (SCA-BCD) methods. Our results reveal the influence of design parameters of the system on the wiretap and covert rates, analytically and numerically. In summary, our study fills the gaps in joint secret and covert transmission for multi-user multi-antenna uplink UAV communications and provides insights to construct such systems.
Large and Small Deviations for Statistical Sequence Matching
Jul 03, 2024



We revisit the problem of statistical sequence matching between two databases of sequences initiated by Unnikrishnan (TIT 2015) and derive theoretical performance guarantees for the generalized likelihood ratio test (GLRT). We first consider the case where the number of matched pairs of sequences between the databases is known. In this case, the task is to accurately find the matched pairs of sequences among all possible matches between the sequences in the two databases. We analyze the performance of the GLRT by Unnikrishnan and explicitly characterize the tradeoff between the mismatch and false reject probabilities under each hypothesis in both large and small deviations regimes. Furthermore, we demonstrate the optimality of Unnikrishnan's GLRT test under the generalized Neyman-Person criterion for both regimes and illustrate our theoretical results via numerical examples. Subsequently, we generalize our achievability analyses to the case where the number of matched pairs is unknown, and an additional error probability needs to be considered. When one of the two databases contains a single sequence, the problem of statistical sequence matching specializes to the problem of multiple classification introduced by Gutman (TIT 1989). For this special case, our result for the small deviations regime strengthens previous result of Zhou, Tan and Motani (Information and Inference 2020) by removing unnecessary conditions on the generating distributions.
Exponentially Consistent Outlier Hypothesis Testing for Continuous Sequences
May 02, 2024In outlier hypothesis testing, one aims to detect outlying sequences among a given set of sequences, where most sequences are generated i.i.d. from a nominal distribution while outlying sequences (outliers) are generated i.i.d. from a different anomalous distribution. Most existing studies focus on discrete-valued sequences, where each data sample takes values in a finite set. To account for practical scenarios where data sequences usually take real values, we study outlier hypothesis testing for continuous sequences when both the nominal and anomalous distributions are \emph{unknown}. Specifically, we propose distribution free tests and prove that the probabilities of misclassification error, false reject and false alarm decay exponentially fast for three different test designs: fixed-length test, sequential test, and two-phase test. In a fixed-length test, one fixes the sample size of each observed sequence; in a sequential test, one takes a sample sequentially from each sequence per unit time until a reliable decision can be made; in a two-phase test, one adapts the sample size from two different fixed values. Remarkably, the two-phase test achieves a good balance between test design complexity and theoretical performance. We first consider the case of at most one outlier, and then generalize our results to the case with multiple outliers where the number of outliers is unknown.
From OTFS to DD-ISAC: Integrating Sensing and Communications in the Delay Doppler Domain
Nov 26, 2023



Next-generation vehicular networks are expected to provide the capability of robust environmental sensing in addition to reliable communications to meet intelligence requirements. A promising solution is the integrated sensing and communication (ISAC) technology, which performs both functionalities using the same spectrum and hardware resources. Most existing works on ISAC consider the Orthogonal Frequency Division Multiplexing (OFDM) waveform. Nevertheless, vehicle motion introduces Doppler shift, which breaks the subcarrier orthogonality and leads to performance degradation. The recently proposed Orthogonal Time Frequency Space (OTFS) modulation, which exploits various advantages of Delay Doppler (DD) channels, has been shown to support reliable communication in high-mobility scenarios. Moreover, the DD waveform can directly interact with radar sensing parameters, which are actually delay and Doppler shifts. This paper investigates the advantages of applying the DD communication waveform to ISAC. Specifically, we first provide a comprehensive overview of implementing DD communications, based on which several advantages of DD-ISAC over OFDM-based ISAC are revealed, including transceiver designs and the ambiguity function. Furthermore, a detailed performance comparison are presented, where the target detection probability and the mean squared error (MSE) performance are also studied. Finally, some challenges and opportunities of DD-ISAC are also provided.