 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
CARE-Bench: A Benchmark of Diverse Client Simulations Guided by Expert Principles for Evaluating LLMs in Psychological Counseling
Nov 12, 2025The mismatch between the growing demand for psychological counseling and the limited availability of services has motivated research into the application of Large Language Models (LLMs) in this domain. Consequently, there is a need for a robust and unified benchmark to assess the counseling competence of various LLMs. Existing works, however, are limited by unprofessional client simulation, static question-and-answer evaluation formats, and unidimensional metrics. These limitations hinder their effectiveness in assessing a model's comprehensive ability to handle diverse and complex clients. To address this gap, we introduce \textbf{CARE-Bench}, a dynamic and interactive automated benchmark. It is built upon diverse client profiles derived from real-world counseling cases and simulated according to expert guidelines. CARE-Bench provides a multidimensional performance evaluation grounded in established psychological scales. Using CARE-Bench, we evaluate several general-purpose LLMs and specialized counseling models, revealing their current limitations. In collaboration with psychologists, we conduct a detailed analysis of the reasons for LLMs' failures when interacting with clients of different types, which provides directions for developing more comprehensive, universal, and effective counseling models.
What Makes Reasoning Invalid: Echo Reflection Mitigation for Large Language Models
Nov 09, 2025



Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of reasoning tasks. Recent methods have further improved LLM performance in complex mathematical reasoning. However, when extending these methods beyond the domain of mathematical reasoning to tasks involving complex domain-specific knowledge, we observe a consistent failure of LLMs to generate novel insights during the reflection stage. Instead of conducting genuine cognitive refinement, the model tends to mechanically reiterate earlier reasoning steps without introducing new information or perspectives, a phenomenon referred to as "Echo Reflection". We attribute this behavior to two key defects: (1) Uncontrollable information flow during response generation, which allows premature intermediate thoughts to propagate unchecked and distort final decisions; (2) Insufficient exploration of internal knowledge during reflection, leading to repeating earlier findings rather than generating new cognitive insights. Building on these findings, we proposed a novel reinforcement learning method termed Adaptive Entropy Policy Optimization (AEPO). Specifically, the AEPO framework consists of two major components: (1) Reflection-aware Information Filtration, which quantifies the cognitive information flow and prevents the final answer from being affected by earlier bad cognitive information; (2) Adaptive-Entropy Optimization, which dynamically balances exploration and exploitation across different reasoning stages, promoting both reflective diversity and answer correctness. Extensive experiments demonstrate that AEPO consistently achieves state-of-the-art performance over mainstream reinforcement learning baselines across diverse benchmarks.
Align-then-Slide: A complete evaluation framework for Ultra-Long Document-Level Machine Translation
Sep 04, 2025



Large language models (LLMs) have ushered in a new era for document-level machine translation (\textit{doc}-mt), yet their whole-document outputs challenge existing evaluation methods that assume sentence-by-sentence alignment. We introduce \textit{\textbf{Align-then-Slide}}, a complete evaluation framework for ultra-long doc-mt. In the Align stage, we automatically infer sentence-level source-target correspondences and rebuild the target to match the source sentence number, resolving omissions and many-to-one/one-to-many mappings. In the n-Chunk Sliding Evaluate stage, we calculate averaged metric scores under 1-, 2-, 3- and 4-chunk for multi-granularity assessment. Experiments on the WMT benchmark show a Pearson correlation of 0.929 between our method with expert MQM rankings. On a newly curated real-world test set, our method again aligns closely with human judgments. Furthermore, preference data produced by Align-then-Slide enables effective CPO training and its direct use as a reward model for GRPO, both yielding translations preferred over a vanilla SFT baseline. The results validate our framework as an accurate, robust, and actionable evaluation tool for doc-mt systems.
PointDGRWKV: Generalizing RWKV-like Architecture to Unseen Domains for Point Cloud Classification
Aug 29, 2025



Domain Generalization (DG) has been recently explored to enhance the generalizability of Point Cloud Classification (PCC) models toward unseen domains. Prior works are based on convolutional networks, Transformer or Mamba architectures, either suffering from limited receptive fields or high computational cost, or insufficient long-range dependency modeling. RWKV, as an emerging architecture, possesses superior linear complexity, global receptive fields, and long-range dependency. In this paper, we present the first work that studies the generalizability of RWKV models in DG PCC. We find that directly applying RWKV to DG PCC encounters two significant challenges: RWKV's fixed direction token shift methods, like Q-Shift, introduce spatial distortions when applied to unstructured point clouds, weakening local geometric modeling and reducing robustness. In addition, the Bi-WKV attention in RWKV amplifies slight cross-domain differences in key distributions through exponential weighting, leading to attention shifts and degraded generalization. To this end, we propose PointDGRWKV, the first RWKV-based framework tailored for DG PCC. It introduces two key modules to enhance spatial modeling and cross-domain robustness, while maintaining RWKV's linear efficiency. In particular, we present Adaptive Geometric Token Shift to model local neighborhood structures to improve geometric context awareness. In addition, Cross-Domain key feature Distribution Alignment is designed to mitigate attention drift by aligning key feature distributions across domains. Extensive experiments on multiple benchmarks demonstrate that PointDGRWKV achieves state-of-the-art performance on DG PCC.
Generative Annotation for ASR Named Entity Correction
Aug 28, 2025

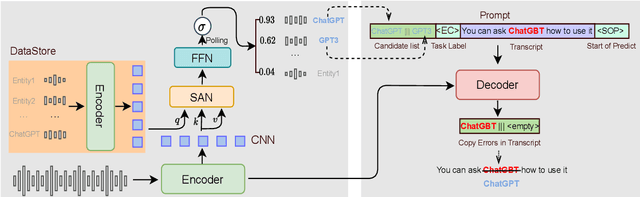
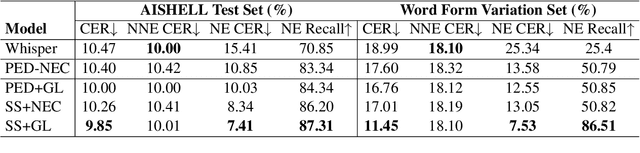
End-to-end automatic speech recognition systems often fail to transcribe domain-specific named entities, causing catastrophic failures in downstream tasks. Numerous fast and lightweight named entity correction (NEC) models have been proposed in recent years. These models, mainly leveraging phonetic-level edit distance algorithms, have shown impressive performances. However, when the forms of the wrongly-transcribed words(s) and the ground-truth entity are significantly different, these methods often fail to locate the wrongly transcribed words in hypothesis, thus limiting their usage. We propose a novel NEC method that utilizes speech sound features to retrieve candidate entities. With speech sound features and candidate entities, we inovatively design a generative method to annotate entity errors in ASR transcripts and replace the text with correct entities. This method is effective in scenarios of word form difference. We test our method using open-source and self-constructed test sets. The results demonstrate that our NEC method can bring significant improvement to entity accuracy. We will open source our self-constructed test set and training data.
How Chain-of-Thought Works? Tracing Information Flow from Decoding, Projection, and Activation
Jul 28, 2025Chain-of-Thought (CoT) prompting significantly enhances model reasoning, yet its internal mechanisms remain poorly understood. We analyze CoT's operational principles by reversely tracing information flow across decoding, projection, and activation phases. Our quantitative analysis suggests that CoT may serve as a decoding space pruner, leveraging answer templates to guide output generation, with higher template adherence strongly correlating with improved performance. Furthermore, we surprisingly find that CoT modulates neuron engagement in a task-dependent manner: reducing neuron activation in open-domain tasks, yet increasing it in closed-domain scenarios. These findings offer a novel mechanistic interpretability framework and critical insights for enabling targeted CoT interventions to design more efficient and robust prompts. We released our code and data at https://anonymous.4open.science/r/cot-D247.
Met$^2$Net: A Decoupled Two-Stage Spatio-Temporal Forecasting Model for Complex Meteorological Systems
Jul 23, 2025The increasing frequency of extreme weather events due to global climate change urges accurate weather prediction. Recently, great advances have been made by the \textbf{end-to-end methods}, thanks to deep learning techniques, but they face limitations of \textit{representation inconsistency} in multivariable integration and struggle to effectively capture the dependency between variables, which is required in complex weather systems. Treating different variables as distinct modalities and applying a \textbf{two-stage training approach} from multimodal models can partially alleviate this issue, but due to the inconformity in training tasks between the two stages, the results are often suboptimal. To address these challenges, we propose an implicit two-stage training method, configuring separate encoders and decoders for each variable. In detailed, in the first stage, the Translator is frozen while the Encoders and Decoders learn a shared latent space, in the second stage, the Encoders and Decoders are frozen, and the Translator captures inter-variable interactions for prediction. Besides, by introducing a self-attention mechanism for multivariable fusion in the latent space, the performance achieves further improvements. Empirically, extensive experiments show the state-of-the-art performance of our method. Specifically, it reduces the MSE for near-surface air temperature and relative humidity predictions by 28.82\% and 23.39\%, respectively. The source code is available at https://github.com/ShremG/Met2Net.
Omni-Video: Democratizing Unified Video Understanding and Generation
Jul 09, 2025Notable breakthroughs in unified understanding and generation modeling have led to remarkable advancements in image understanding, reasoning, production and editing, yet current foundational models predominantly focus on processing images, creating a gap in the development of unified models for video understanding and generation. This report presents Omni-Video, an efficient and effective unified framework for video understanding, generation, as well as instruction-based editing. Our key insight is to teach existing multimodal large language models (MLLMs) to produce continuous visual clues that are used as the input of diffusion decoders, which produce high-quality videos conditioned on these visual clues. To fully unlock the potential of our system for unified video modeling, we integrate several technical improvements: 1) a lightweight architectural design that respectively attaches a vision head on the top of MLLMs and a adapter before the input of diffusion decoders, the former produce visual tokens for the latter, which adapts these visual tokens to the conditional space of diffusion decoders; and 2) an efficient multi-stage training scheme that facilitates a fast connection between MLLMs and diffusion decoders with limited data and computational resources. We empirically demonstrate that our model exhibits satisfactory generalization abilities across video generation, editing and understanding tasks.
Symbolic identification of tensor equations in multidimensional physical fields
Jul 02, 2025Recently, data-driven methods have shown great promise for discovering governing equations from simulation or experimental data. However, most existing approaches are limited to scalar equations, with few capable of identifying tensor relationships. In this work, we propose a general data-driven framework for identifying tensor equations, referred to as Symbolic Identification of Tensor Equations (SITE). The core idea of SITE--representing tensor equations using a host-plasmid structure--is inspired by the multidimensional gene expression programming (M-GEP) approach. To improve the robustness of the evolutionary process, SITE adopts a genetic information retention strategy. Moreover, SITE introduces two key innovations beyond conventional evolutionary algorithms. First, it incorporates a dimensional homogeneity check to restrict the search space and eliminate physically invalid expressions. Second, it replaces traditional linear scaling with a tensor linear regression technique, greatly enhancing the efficiency of numerical coefficient optimization. We validate SITE using two benchmark scenarios, where it accurately recovers target equations from synthetic data, showing robustness to noise and small sample sizes. Furthermore, SITE is applied to identify constitutive relations directly from molecular simulation data, which are generated without reliance on macroscopic constitutive models. It adapts to both compressible and incompressible flow conditions and successfully identifies the corresponding macroscopic forms, highlighting its potential for data-driven discovery of tensor equation.