 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Wang
ManiCLIP: Multi-Attribute Face Manipulation from Text
Oct 02, 2022
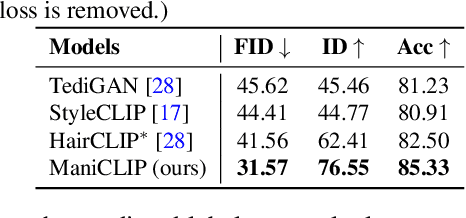


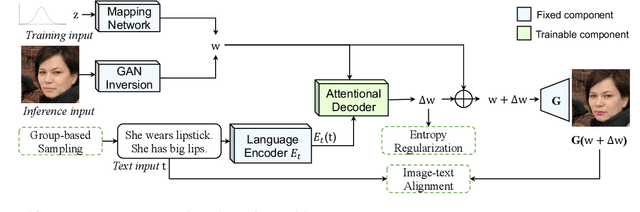
In this paper we present a novel multi-attribute face manipulation method based on textual descriptions. Previous text-based image editing methods either require test-time optimization for each individual image or are restricted to single attribute editing. Extending these methods to multi-attribute face image editing scenarios will introduce undesired excessive attribute change, e.g., text-relevant attributes are overly manipulated and text-irrelevant attributes are also changed. In order to address these challenges and achieve natural editing over multiple face attributes, we propose a new decoupling training scheme where we use group sampling to get text segments from same attribute categories, instead of whole complex sentences. Further, to preserve other existing face attributes, we encourage the model to edit the latent code of each attribute separately via a entropy constraint. During the inference phase, our model is able to edit new face images without any test-time optimization, even from complex textual prompts. We show extensive experiments and analysis to demonstrate the efficacy of our method, which generates natural manipulated faces with minimal text-irrelevant attribute editing. Code and pre-trained model will be released.
A Taxonomy of Semantic Information in Robot-Assisted Disaster Response
Sep 30, 2022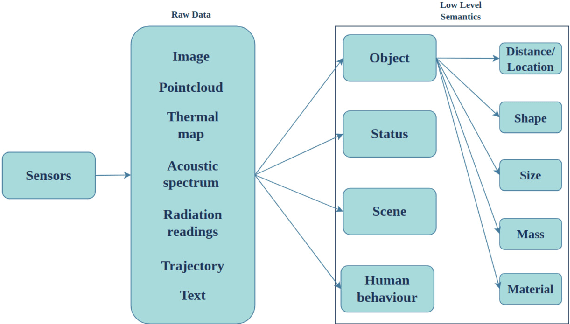
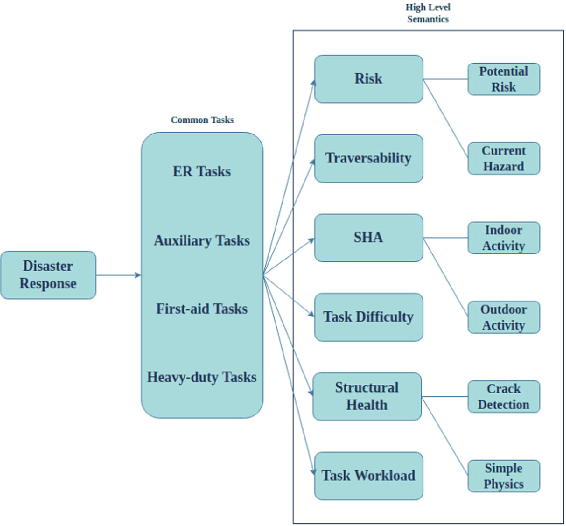
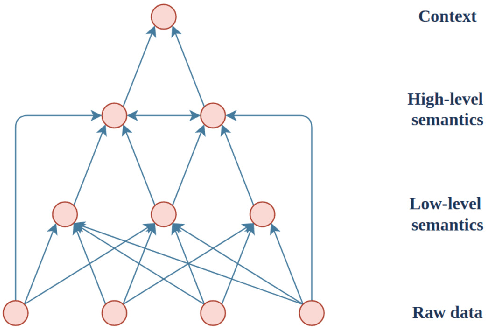
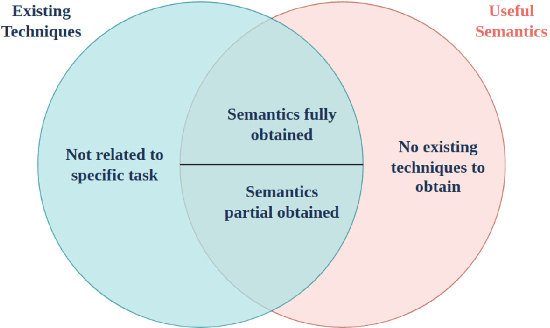
This paper proposes a taxonomy of semantic information in robot-assisted disaster response. Robots are increasingly being used in hazardous environment industries and emergency response teams to perform various tasks. Operational decision-making in such applications requires a complex semantic understanding of environments that are remote from the human operator. Low-level sensory data from the robot is transformed into perception and informative cognition. Currently, such cognition is predominantly performed by a human expert, who monitors remote sensor data such as robot video feeds. This engenders a need for AI-generated semantic understanding capabilities on the robot itself. Current work on semantics and AI lies towards the relatively academic end of the research spectrum, hence relatively removed from the practical realities of first responder teams. We aim for this paper to be a step towards bridging this divide. We first review common robot tasks in disaster response and the types of information such robots must collect. We then organize the types of semantic features and understanding that may be useful in disaster operations into a taxonomy of semantic information. We also briefly review the current state-of-the-art semantic understanding techniques. We highlight potential synergies, but we also identify gaps that need to be bridged to apply these ideas. We aim to stimulate the research that is needed to adapt, robustify, and implement state-of-the-art AI semantics methods in the challenging conditions of disasters and first responder scenarios.
Exploiting Transformer in Reinforcement Learning for Interpretable Temporal Logic Motion Planning
Sep 27, 2022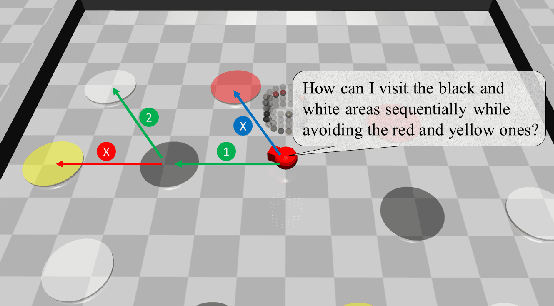
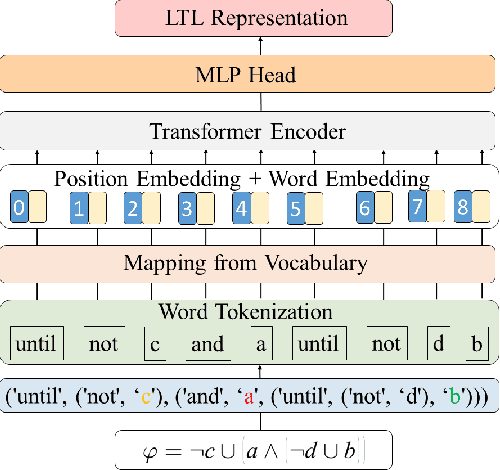
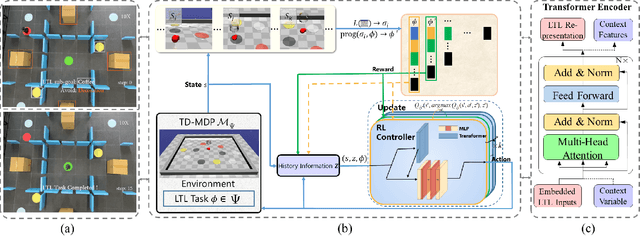
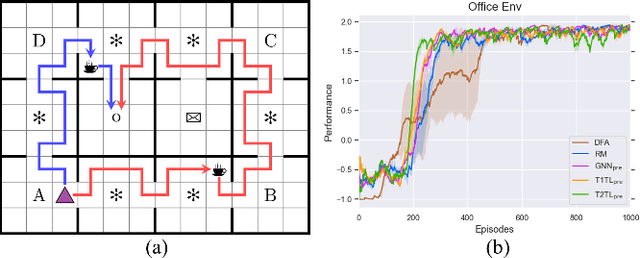
Automaton based approaches have enabled robots to perform various complex tasks. However, most existing automaton based algorithms highly rely on the manually customized representation of states for the considered task, limiting its applicability in deep reinforcement learning algorithms. To address this issue, by incorporating Transformer into reinforcement learning, we develop a Double-Transformer-guided Temporal Logic framework (T2TL) that exploits the structural feature of Transformer twice, i.e., first encoding the LTL instruction via the Transformer module for efficient understanding of task instructions during the training and then encoding the context variable via the Transformer again for improved task performance. Particularly, the LTL instruction is specified by co-safe LTL. As a semantics-preserving rewriting operation, LTL progression is exploited to decompose the complex task into learnable sub-goals, which not only converts non-Markovian reward decision process to Markovian ones, but also improves the sampling efficiency by simultaneous learning of multiple sub-tasks. An environment-agnostic LTL pre-training scheme is further incorporated to facilitate the learning of the Transformer module resulting in improved representation of LTL. The simulation and experiment results demonstrate the effectiveness of the T2TL framework.
Model Inversion Attacks against Graph Neural Networks
Sep 19, 2022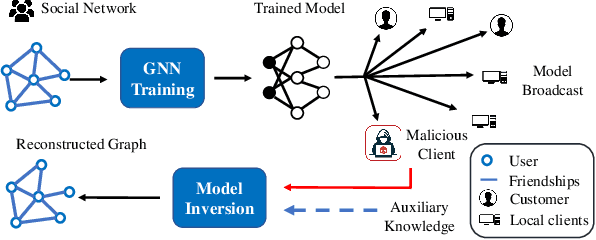
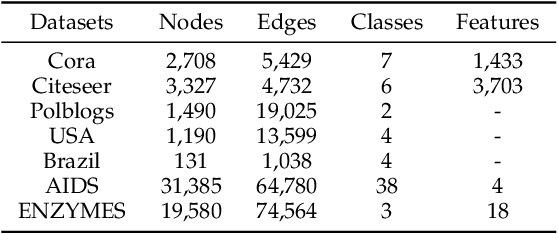
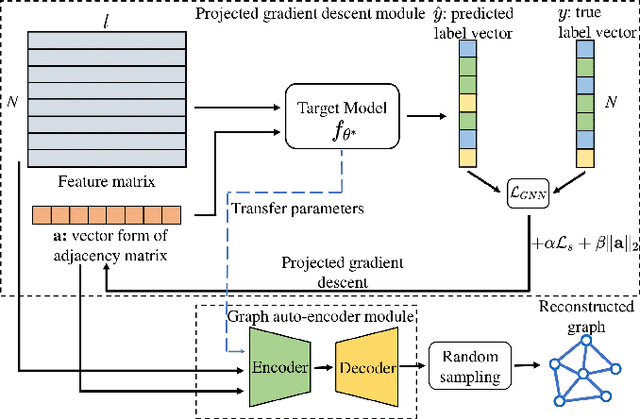

Many data mining tasks rely on graphs to model relational structures among individuals (nodes). Since relational data are often sensitive, there is an urgent need to evaluate the privacy risks in graph data. One famous privacy attack against data analysis models is the model inversion attack, which aims to infer sensitive data in the training dataset and leads to great privacy concerns. Despite its success in grid-like domains, directly applying model inversion attacks on non-grid domains such as graph leads to poor attack performance. This is mainly due to the failure to consider the unique properties of graphs. To bridge this gap, we conduct a systematic study on model inversion attacks against Graph Neural Networks (GNNs), one of the state-of-the-art graph analysis tools in this paper. Firstly, in the white-box setting where the attacker has full access to the target GNN model, we present GraphMI to infer the private training graph data. Specifically, in GraphMI, a projected gradient module is proposed to tackle the discreteness of graph edges and preserve the sparsity and smoothness of graph features; a graph auto-encoder module is used to efficiently exploit graph topology, node attributes, and target model parameters for edge inference; a random sampling module can finally sample discrete edges. Furthermore, in the hard-label black-box setting where the attacker can only query the GNN API and receive the classification results, we propose two methods based on gradient estimation and reinforcement learning (RL-GraphMI). Our experimental results show that such defenses are not sufficiently effective and call for more advanced defenses against privacy attacks.
LO-Det: Lightweight Oriented Object Detection in Remote Sensing Images
Sep 16, 2022
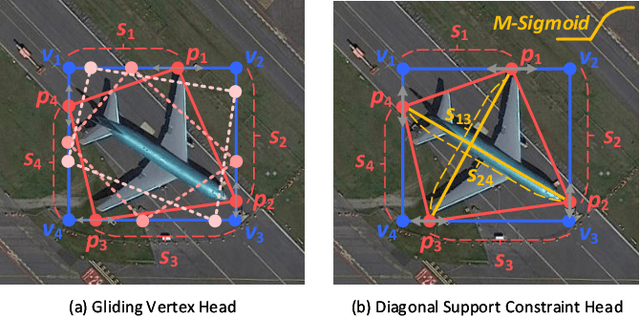
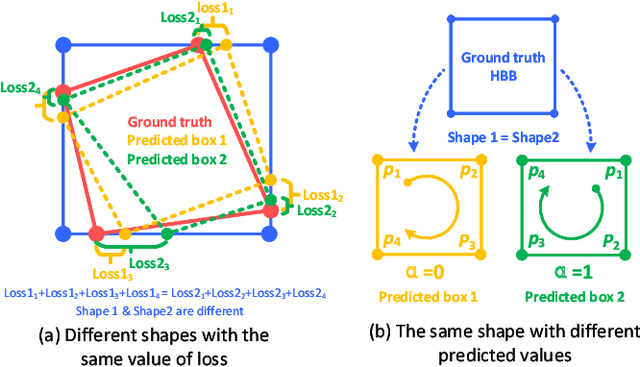
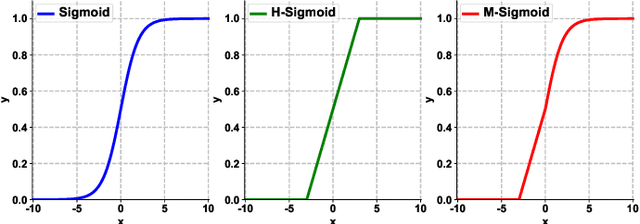
A few lightweight convolutional neural network (CNN) models have been recently designed for remote sensing object detection (RSOD). However, most of them simply replace vanilla convolutions with stacked separable convolutions, which may not be efficient due to a lot of precision losses and may not be able to detect oriented bounding boxes (OBB). Also, the existing OBB detection methods are difficult to constrain the shape of objects predicted by CNNs accurately. In this paper, we propose an effective lightweight oriented object detector (LO-Det). Specifically, a channel separation-aggregation (CSA) structure is designed to simplify the complexity of stacked separable convolutions, and a dynamic receptive field (DRF) mechanism is developed to maintain high accuracy by customizing the convolution kernel and its perception range dynamically when reducing the network complexity. The CSA-DRF component optimizes efficiency while maintaining high accuracy. Then, a diagonal support constraint head (DSC-Head) component is designed to detect OBBs and constrain their shapes more accurately and stably. Extensive experiments on public datasets demonstrate that the proposed LO-Det can run very fast even on embedded devices with the competitive accuracy of detecting oriented objects.
* 15 pages
Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence
Sep 07, 2022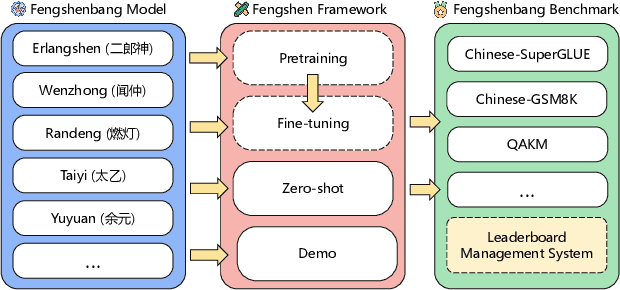
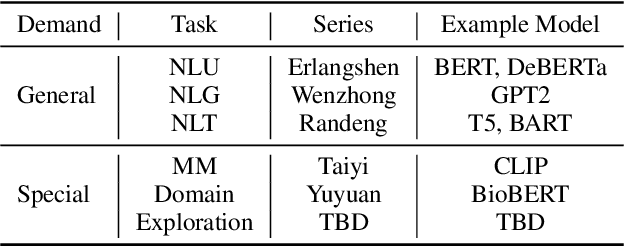

Nowadays, foundation models become one of fundamental infrastructures in artificial intelligence, paving ways to the general intelligence. However, the reality presents two urgent challenges: existing foundation models are dominated by the English-language community; users are often given limited resources and thus cannot always use foundation models. To support the development of the Chinese-language community, we introduce an open-source project, called Fengshenbang, which leads by the research center for Cognitive Computing and Natural Language (CCNL). Our project has comprehensive capabilities, including large pre-trained models, user-friendly APIs, benchmarks, datasets, and others. We wrap all these in three sub-projects: the Fengshenbang Model, the Fengshen Framework, and the Fengshen Benchmark. An open-source roadmap, Fengshenbang, aims to re-evaluate the open-source community of Chinese pre-trained large-scale models, prompting the development of the entire Chinese large-scale model community. We also want to build a user-centered open-source ecosystem to allow individuals to access the desired models to match their computing resources. Furthermore, we invite companies, colleges, and research institutions to collaborate with us to build the large-scale open-source model-based ecosystem. We hope that this project will be the foundation of Chinese cognitive intelligence.
Multi-Grained Angle Representation for Remote Sensing Object Detection
Sep 07, 2022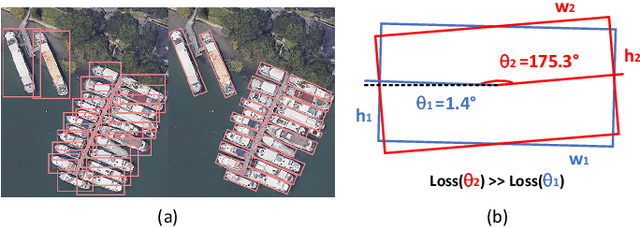
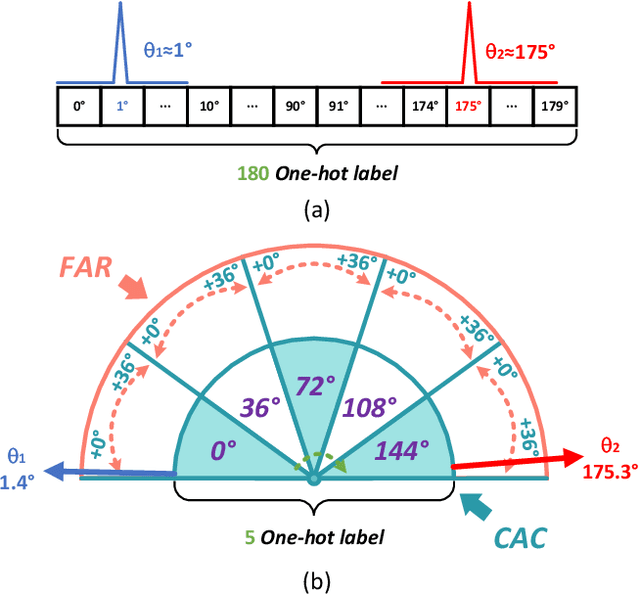
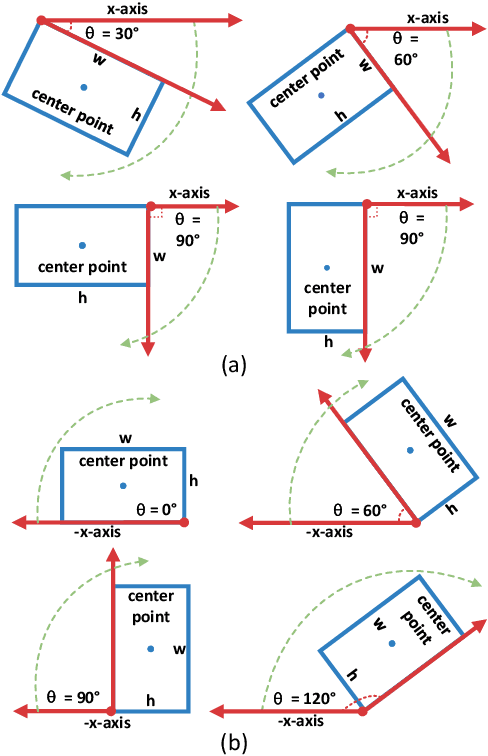
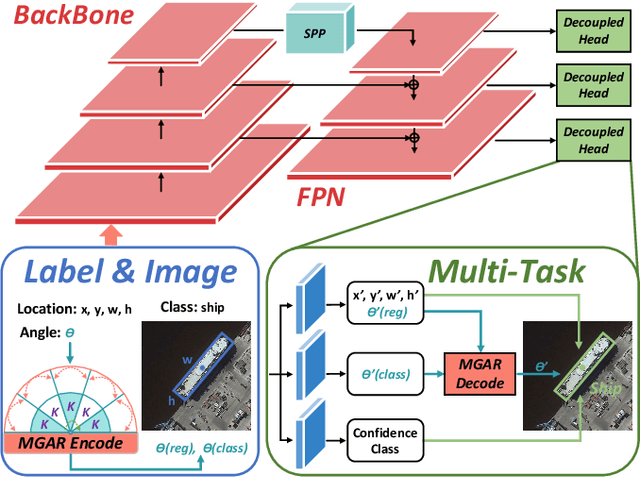
Arbitrary-oriented object detection (AOOD) plays a significant role for image understanding in remote sensing scenarios. The existing AOOD methods face the challenges of ambiguity and high costs in angle representation. To this end, a multi-grained angle representation (MGAR) method, consisting of coarse-grained angle classification (CAC) and fine-grained angle regression (FAR), is proposed. Specifically, the designed CAC avoids the ambiguity of angle prediction by discrete angular encoding (DAE) and reduces complexity by coarsening the granularity of DAE. Based on CAC, FAR is developed to refine the angle prediction with much lower costs than narrowing the granularity of DAE. Furthermore, an Intersection over Union (IoU) aware FAR-Loss (IFL) is designed to improve accuracy of angle prediction using an adaptive re-weighting mechanism guided by IoU. Extensive experiments are performed on several public remote sensing datasets, which demonstrate the effectiveness of the proposed MGAR. Moreover, experiments on embedded devices demonstrate that the proposed MGAR is also friendly for lightweight deployments.
Task-wise Sampling Convolutions for Arbitrary-Oriented Object Detection in Aerial Images
Sep 06, 2022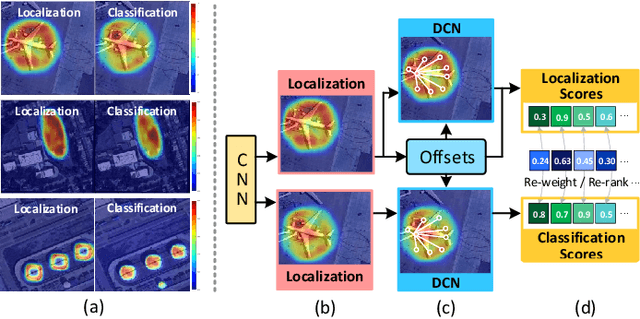
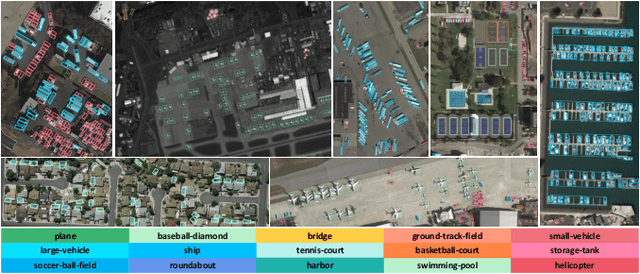

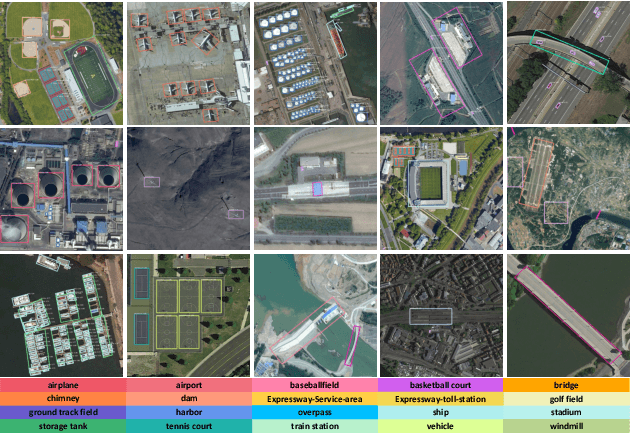
Arbitrary-oriented object detection (AOOD) has been widely applied to locate and classify objects with diverse orientations in remote sensing images. However, the inconsistent features for the localization and classification tasks in AOOD models may lead to ambiguity and low-quality object predictions, which constrains the detection performance. In this paper, an AOOD method called task-wise sampling convolutions (TS-Conv) is proposed. TS-Conv adaptively samples task-wise features from respective sensitive regions and maps these features together in alignment to guide a dynamic label assignment for better predictions. Specifically, sampling positions of the localization convolution in TS-Conv is supervised by the oriented bounding box (OBB) prediction associated with spatial coordinates. While sampling positions and convolutional kernel of the classification convolution are designed to be adaptively adjusted according to different orientations for improving the orientation robustness of features. Furthermore, a dynamic task-aware label assignment (DTLA) strategy is developed to select optimal candidate positions and assign labels dynamicly according to ranked task-aware scores obtained from TS-Conv. Extensive experiments on several public datasets covering multiple scenes, multimodal images, and multiple categories of objects demonstrate the effectiveness, scalability and superior performance of the proposed TS-Conv.
Transformer-CNN Cohort: Semi-supervised Semantic Segmentation by the Best of Both Students
Sep 06, 2022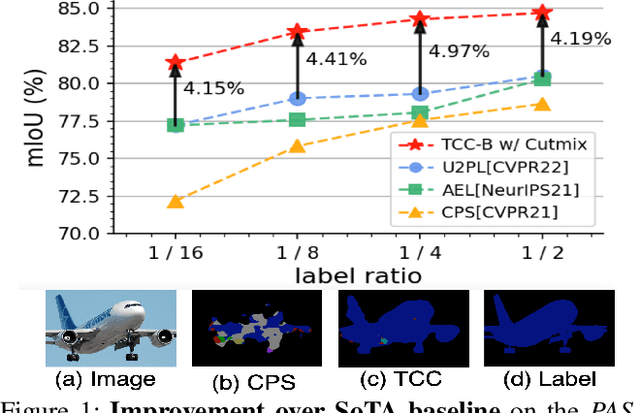
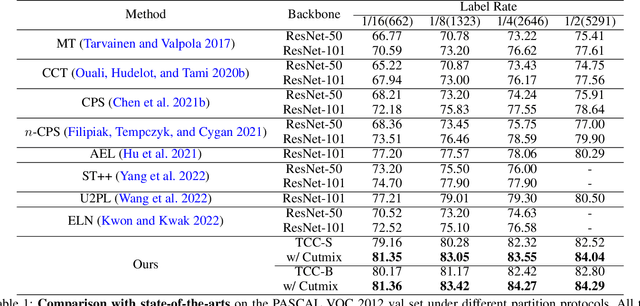
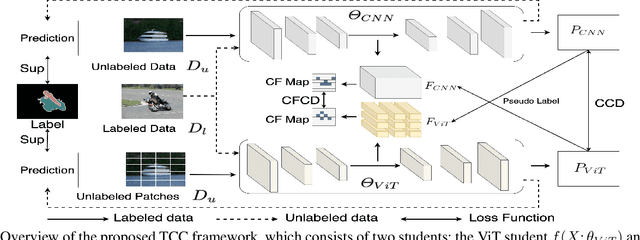
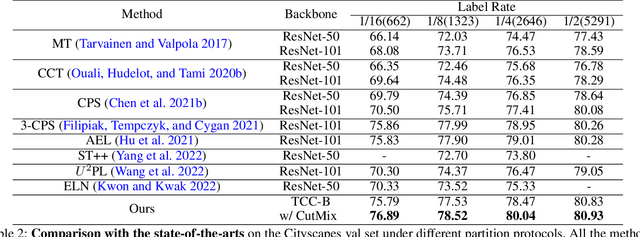
The popular methods for semi-supervised semantic segmentation mostly adopt a unitary network model using convolutional neural networks (CNNs) and enforce consistency of the model predictions over small perturbations applied to the inputs or model. However, such a learning paradigm suffers from a) limited learning capability of the CNN-based model; b) limited capacity of learning the discriminative features for the unlabeled data; c) limited learning for both global and local information from the whole image. In this paper, we propose a novel Semi-supervised Learning approach, called Transformer-CNN Cohort (TCC), that consists of two students with one based on the vision transformer (ViT) and the other based on the CNN. Our method subtly incorporates the multi-level consistency regularization on the predictions and the heterogeneous feature spaces via pseudo labeling for the unlabeled data. First, as the inputs of the ViT student are image patches, the feature maps extracted encode crucial class-wise statistics. To this end, we propose class-aware feature consistency distillation (CFCD) that first leverages the outputs of each student as the pseudo labels and generates class-aware feature (CF) maps. It then transfers knowledge via the CF maps between the students. Second, as the ViT student has more uniform representations for all layers, we propose consistency-aware cross distillation to transfer knowledge between the pixel-wise predictions from the cohort. We validate the TCC framework on Cityscapes and Pascal VOC 2012 datasets, which significantly outperforms existing semi-supervised methods by a large margin.
Few-shot Incremental Event Detection
Sep 05, 2022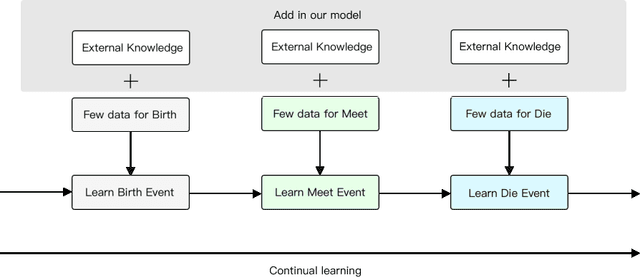
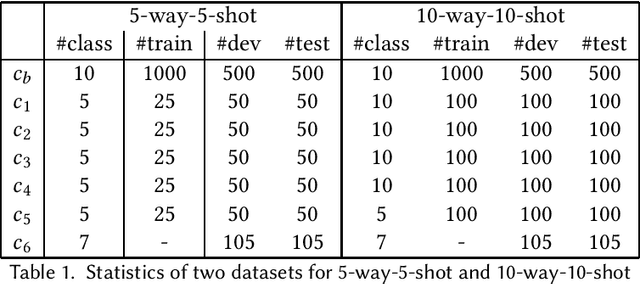
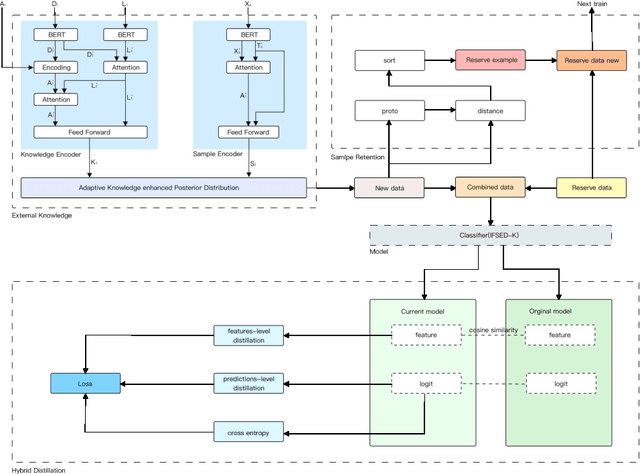
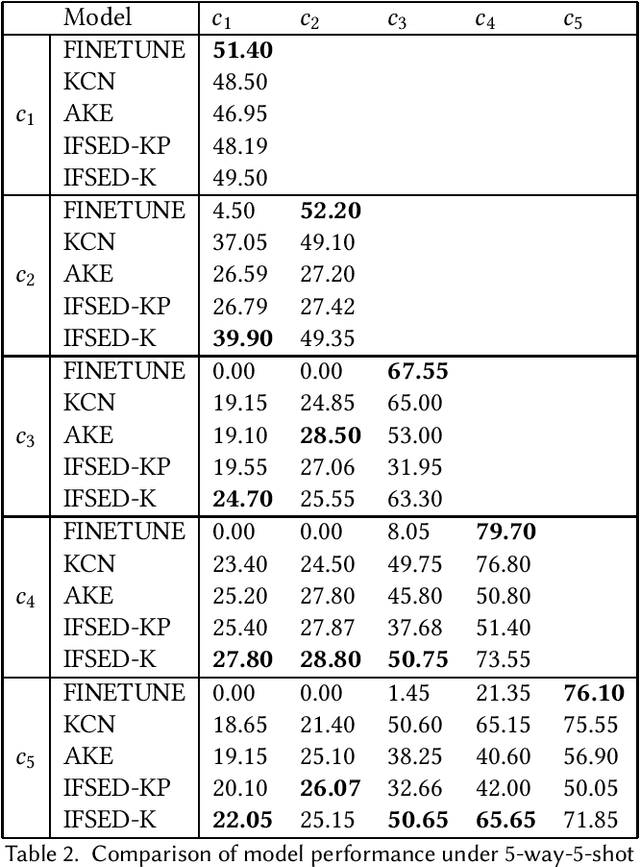
Event detection tasks can help people quickly determine the domain from complex texts. It can also provides powerful support for downstream tasks of natural language processing.Existing methods implement fixed-type learning only based on large amounts of data. When extending to new classes, it is often required to retain the original data and retrain the model.Incremental event detection tasks enables lifelong learning of new classes, but most existing methods need to retain a large number of original data or face the problem of catastrophic forgetting. Apart from that, it is difficult to obtain enough data for model training due to the lack of high-quality data in practical.To address the above problems, we define a new task in the domain of event detection, which is few-shot incremental event detection.This task require that the model should retain previous type when learning new event type in each round with limited input. We recreate and release a benchmark dataset in the few-shot incremental event detection task based on FewEvent.The dataset we published is more appropriate than other in this new task. In addition, we propose two benchmark approaches, IFSED-K and IFSED-KP, which can address the task in different ways. Experiments results have shown that our approach has a higher F1 score and is more stable than baseline.