 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUCID: Learned Undersampling-Adaptive Consistency-Guided Inference with Deterministic Flow Matching for Sparse-View CT Reconstruction
Jun 15, 2026Sparse-view CT reduces radiation dose and scanning time by acquiring fewer projection views, but angular undersampling makes reconstruction severely ill-posed, causing streak artifacts, structural blurring, and loss of fine details. Existing supervised methods are often tied to specific sampling settings, whereas generative methods may introduce anatomically inconsistent hallucination-like structures under severe undersampling. We propose Lucid, a sparsity-adaptive, consistency-guided reconstruction framework based on a Flow Matching generative prior for sparse-view CT. Lucid is trained only on high-quality CT images to learn a continuous transport between a Gaussian distribution and the high-quality CT image distribution, independent of view sampling. During inference, the sampling sparsity level is explicitly incorporated to adapt the generative trajectory of a single pretrained model. Specifically, Lucid constructs a degradation-matched initial state by sparsity-weighted fusion of the sparse-view FBP image and Gaussian noise, performs sparsity-modulated Flow Matching updates, and applies projection-domain data-consistency correction after each prior update. Experiments under multiple sparse-view settings show that Lucid achieves stable reconstruction performance across different sampling densities, improves image quality and structural fidelity, and reduces the risk of hallucination-like structures in generative sparse-view CT reconstruction.
WALL-WM: Carving World Action Modeling at the Event Joints
Jun 01, 2026WALL-WM is a World Action Model that shifts video-action learning from chunk-centric optimization to event-grounded Vision-Language-Action pretraining, using semantically coherent action events as the atomic unit of learning. Existing WAMs commonly initialize from multimodal or video foundation models and then optimize fixed-length action chunks conditioned directly on the current observation and instruction. Although convenient, this chunk-centric formulation creates a fundamental granularity mismatch. Language describes semantic goals and events, vision evolves through continuous scene dynamics, and actions operate at control-level timescales; forcing all three into the same fixed-length prediction window turns VLA training into short-horizon correlation fitting. WALL-WM addresses this mismatch by organizing both supervision and data around semantic events. Specifically, it pairs event-grounded VLA pretraining with a data ecosystem built from event-level captions and cluster-balanced sampling, enabling scalable learning over diverse behaviors, scenes, and task structures. From the same event-pretrained backbone, WALL-WM supports two complementary inference modes. The event mode consumes next-event descriptions and enables variable-length execution chunks, while the unified mode uses a VLM with Staircase Decoding to condition conventional fixed-length chunk inference while preserving a gradient-continuous VLA path. Together with Muon-optimizer-based large-scale pretraining infrastructure, WALL-WM provides a practical scale-up recipe for general-purpose WAMs. Experiments show that WALL-WM generalizes broadly across language, scenes, and tasks, achieving state-of-the-art performance in large-scale real-world generalization evaluation.
Wall-OSS-0.5 Technical Report
Jun 01, 2026Large-scale Vision-Language-Action (VLA) pretraining is increasingly adopted as the foundation for robot policies, yet the evidence for pretrained VLAs is almost invariably reported after task-specific fine-tuning. This leaves a foundational question unanswered: does VLA pretraining itself yield executable robot behavior, or does it merely furnish a better initialization for downstream policy learning? We present Wall-OSS-0.5, an open-source 4B VLA built upon a 3B VLM backbone augmented with action-generation components, designed so that pretrained robotic capability is directly measurable on physical hardware. The model is pretrained across more than 20 embodiments, processing over one million robot trajectories per epoch alongside a grounded multimodal corpus. We adopt a gradient-bridged co-training recipe in which three objectives play distinct and complementary roles: discrete action prediction routes strong VLM-native gradients into the backbone, multimodal prediction preserves grounded vision-language understanding, and continuous flow matching serves as the deployment-time action interface. Before task-specific fine-tuning, the pretrained checkpoint achieves non-trivial zero-shot real-robot behavior, completing several tasks, including a held-out deformable manipulation task, at high task progress on a 17-task suite. After fine-tuning, the same checkpoint serves as a stronger adaptation prior, reaching 60.5% average task progress on 15 real-robot tasks and outperforming π_0.5 by 17.5%. Multimodal evaluations further confirm that action training does not erode grounded vision-language competence: the model preserves broad vision-language ability while strengthening embodied grounding. Together, these results reposition VLA pretraining from an initialization strategy to a directly testable, already useful source of robot capability.
XRZero-G0: Pushing the Frontier of Dexterous Robotic Manipulation with Interfaces, Quality and Ratios
Apr 14, 2026The acquisition of high-quality, action-aligned demonstration data remains a fundamental bottleneck in scaling foundation models for dexterous robot manipulation. Although robot-free human demonstrations (e.g., the UMI paradigm) offer a scalable alternative to traditional teleoperation, current systems are constrained by sub-optimal hardware ergonomics, open-loop workflows, and a lack of systematic data-mixing strategies. To address these limitations, we present XRZero-G0, a hardware-software co-designed system for embodied data collection and policy learning. The system features an ergonomic, virtual reality interface equipped with a top-view camera and dual specialized grippers to directly improve collection efficiency. To ensure dataset reliability, we propose a closed-loop collection, inspection, training, and evaluation pipeline for non-proprioceptive data. This workflow achieves an 85% data validity rate and establishes a transparent mechanism for quality control. Furthermore, we investigate the empirical scaling behaviors and optimal mixing ratios of robot-free data. Extensive experiments indicate that combining a minimal volume of real-robot data with large-scale robot-free data (e.g., a 10:1 ratio) achieves performance comparable to exclusively real-robot datasets, while reducing acquisition costs by a factor of twenty. Utilizing XRZero-G0, we construct a 2,000-hour robot-free dataset that enables zero-shot cross-embodiment transfer to a target physical robot, demonstrating a highly scalable methodology for generalized real-world manipulation.Our project repository: https://github.com/X-Square-Robot/XRZero-G0
General Explicit Network (GEN): A novel deep learning architecture for solving partial differential equations
Apr 02, 2026Machine learning, especially physics-informed neural networks (PINNs) and their neural network variants, has been widely used to solve problems involving partial differential equations (PDEs). The successful deployment of such methods beyond academic research remains limited. For example, PINN methods primarily consider discrete point-to-point fitting and fail to account for the potential properties of real solutions. The adoption of continuous activation functions in these approaches leads to local characteristics that align with the equation solutions while resulting in poor extensibility and robustness. A general explicit network (GEN) that implements point-to-function PDE solving is proposed in this paper. The "function" component can be constructed based on our prior knowledge of the original PDEs through corresponding basis functions for fitting. The experimental results demonstrate that this approach enables solutions with high robustness and strong extensibility to be obtained.
Beyond Fixed Inference: Quantitative Flow Matching for Adaptive Image Denoising
Apr 02, 2026Diffusion and flow-based generative models have shown strong potential for image restoration. However, image denoising under unknown and varying noise conditions remains challenging, because the learned vector fields may become inconsistent across different noise levels, leading to degraded restoration quality under mismatch between training and inference. To address this issue, we propose a quantitative flow matching framework for adaptive image denoising. The method first estimates the input noise level from local pixel statistics, and then uses this quantitative estimate to adapt the inference trajectory, including the starting point, the number of integration steps, and the step-size schedule. In this way, the denoising process is better aligned with the actual corruption level of each input, reducing unnecessary computation for lightly corrupted images while providing sufficient refinement for heavily degraded ones. By coupling quantitative noise estimation with noise-adaptive flow inference, the proposed method improves both restoration accuracy and inference efficiency. Extensive experiments on natural, medical, and microscopy images demonstrate its robustness and strong generalization across diverse noise levels and imaging conditions.
A Novel Low-Complexity Dual-Domain Expectation Propagation Detection Aided AFDM for Future Communications
Mar 31, 2026This paper presents a dual-domain low-complexity expectation propagation (EP) detection framework for affine frequency division multiplexing (AFDM) systems. By analyzing the structural properties of the effective channel matrices in both the time and affine frequency (AF) domains, our key observation is the domain-specific quasi-banded sparsity patterns, including AF-domain sparsity under frequency-selective channels and time-domain sparsity under doubly-selective channels. Based on these observations, we develop an AF-domain EP (EP-AF) detector for frequency-selective channels and a time-domain EP (EP-T) detector for doubly-selective channels, respectively. By performing iterative inference in the time domain using the Gaussian approximation, the proposed EP-T detector avoids inverting the dense channel matrix in the AF domain. Furthermore, the proposed EP-AF and EP-T detectors leverage the aforementioned quasi-banded sparsity of the AF domain and time domain channel matrices, respectively, to reduce the complexity of matrix inversion from cubic to linear order. Simulation results demonstrate that the proposed low-complexity EP-AF detector achieves nearly identical error rate performance to its conventional counterpart, while the proposed low-complexity EP-T detector offers an attractive trade-off between detection performance and complexity.
ManipArena: Comprehensive Real-world Evaluation of Reasoning-Oriented Generalist Robot Manipulation
Mar 30, 2026Vision-Language-Action (VLA) models and world models have recently emerged as promising paradigms for general-purpose robotic intelligence, yet their progress is hindered by the lack of reliable evaluation protocols that reflect real-world deployment. Existing benchmarks are largely simulator-centric, which provide controllability but fail to capture the reality gap caused by perception noise, complex contact dynamics, hardware constraints, and system latency. Moreover, fragmented real-world evaluations across different robot platforms prevent fair and reproducible comparison. To address these challenges, we introduce ManipArena, a standardized evaluation framework designed to bridge simulation and real-world execution. ManipArena comprises 20 diverse tasks across 10,812 expert trajectories emphasizing reasoning-oriented manipulation tasks requiring semantic and spatial reasoning, supports multi-level generalization through controlled out-of-distribution settings, and incorporates long-horizon mobile manipulation beyond tabletop scenarios. The framework further provides rich sensory diagnostics, including low-level motor signals, and synchronized real-to-sim environments constructed via high-quality 3D scanning. Together, these features enable fair, realistic, and reproducible evaluation for both VLA and world model approaches, providing a scalable foundation for diagnosing and advancing embodied intelligence systems.
Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network
Aug 18, 2025



Accurate watch time prediction is crucial for enhancing user engagement in streaming short-video platforms, although it is challenged by complex distribution characteristics across multi-granularity levels. Through systematic analysis of real-world industrial data, we uncover two critical challenges in watch time prediction from a distribution aspect: (1) coarse-grained skewness induced by a significant concentration of quick-skips1, (2) fine-grained diversity arising from various user-video interaction patterns. Consequently, we assume that the watch time follows the Exponential-Gaussian Mixture (EGM) distribution, where the exponential and Gaussian components respectively characterize the skewness and diversity. Accordingly, an Exponential-Gaussian Mixture Network (EGMN) is proposed for the parameterization of EGM distribution, which consists of two key modules: a hidden representation encoder and a mixture parameter generator. We conducted extensive offline experiments on public datasets and online A/B tests on the industrial short-video feeding scenario of Xiaohongshu App to validate the superiority of EGMN compared with existing state-of-the-art methods. Remarkably, comprehensive experimental results have proven that EGMN exhibits excellent distribution fitting ability across coarse-to-fine-grained levels. We open source related code on Github: https://github.com/BestActionNow/EGMN.
Go-Oracle: Automated Test Oracle for Go Concurrency Bugs
Dec 11, 2024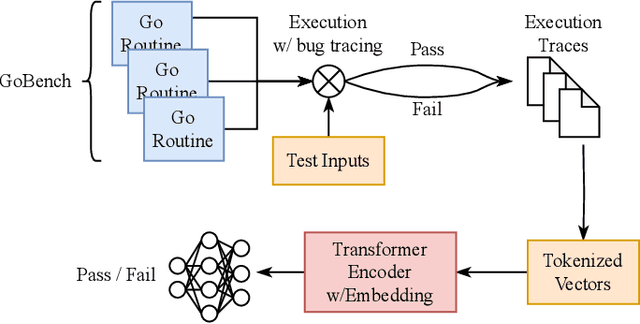

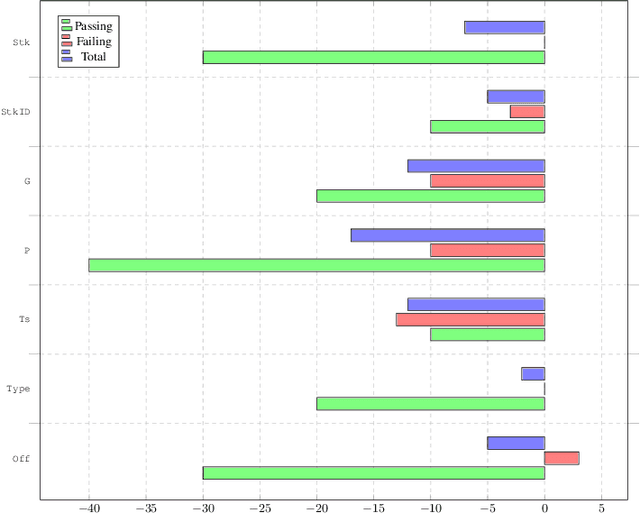
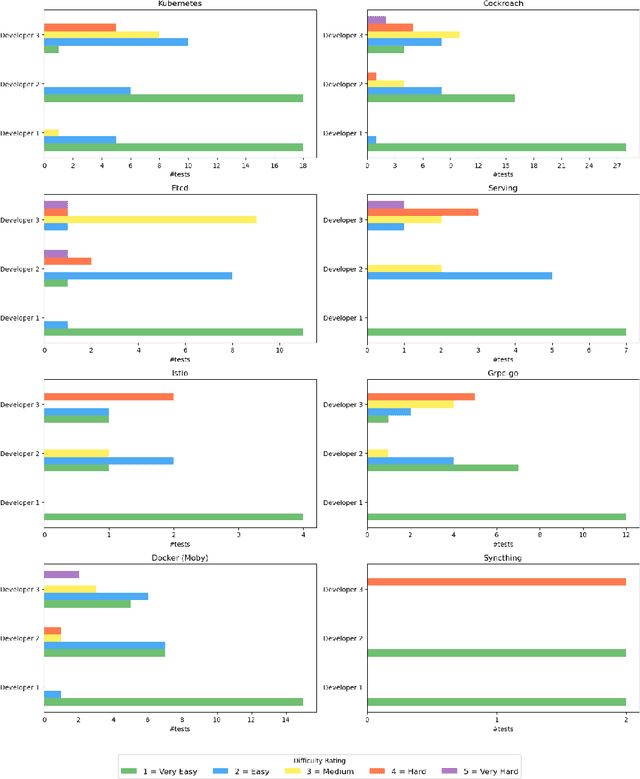
The Go programming language has gained significant traction for developing software, especially in various infrastructure systems. Nonetheless, concurrency bugs have become a prevalent issue within Go, presenting a unique challenge due to the language's dual concurrency mechanisms-communicating sequential processes and shared memory. Detecting concurrency bugs and accurately classifying program executions as pass or fail presents an immense challenge, even for domain experts. We conducted a survey with expert developers at Bytedance that confirmed this challenge. Our work seeks to address the test oracle problem for Go programs, to automatically classify test executions as pass or fail. This problem has not been investigated in the literature for Go programs owing to its distinctive programming model. Our approach involves collecting both passing and failing execution traces from various subject Go programs. We capture a comprehensive array of execution events using the native Go execution tracer. Subsequently, we preprocess and encode these traces before training a transformer-based neural network to effectively classify the traces as either passing or failing. The evaluation of our approach encompasses 8 subject programs sourced from the GoBench repository. These subject programs are routinely used as benchmarks in an industry setting. Encouragingly, our test oracle, Go-Oracle, demonstrates high accuracies even when operating with a limited dataset, showcasing the efficacy and potential of our methodology. Developers at Bytedance strongly agreed that they would use the Go-Oracle tool over the current practice of manual inspections to classify tests for Go programs as pass or fail.