 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Flexible Multi-LLM Integration for Scalable Knowledge Aggregation
May 28, 2025



Large language models (LLMs) have shown remarkable promise but remain challenging to continually improve through traditional finetuning, particularly when integrating capabilities from other specialized LLMs. Popular methods like ensemble and weight merging require substantial memory and struggle to adapt to changing data environments. Recent efforts have transferred knowledge from multiple LLMs into a single target model; however, they suffer from interference and degraded performance among tasks, largely due to limited flexibility in candidate selection and training pipelines. To address these issues, we propose a framework that adaptively selects and aggregates knowledge from diverse LLMs to build a single, stronger model, avoiding the high memory overhead of ensemble and inflexible weight merging. Specifically, we design an adaptive selection network that identifies the most relevant source LLMs based on their scores, thereby reducing knowledge interference. We further propose a dynamic weighted fusion strategy that accounts for the inherent strengths of candidate LLMs, along with a feedback-driven loss function that prevents the selector from converging on a single subset of sources. Experimental results demonstrate that our method can enable a more stable and scalable knowledge aggregation process while reducing knowledge interference by up to 50% compared to existing approaches. Code is avaliable at https://github.com/ZLKong/LLM_Integration
SpikeStereoNet: A Brain-Inspired Framework for Stereo Depth Estimation from Spike Streams
May 26, 2025



Conventional frame-based cameras often struggle with stereo depth estimation in rapidly changing scenes. In contrast, bio-inspired spike cameras emit asynchronous events at microsecond-level resolution, providing an alternative sensing modality. However, existing methods lack specialized stereo algorithms and benchmarks tailored to the spike data. To address this gap, we propose SpikeStereoNet, a brain-inspired framework and the first to estimate stereo depth directly from raw spike streams. The model fuses raw spike streams from two viewpoints and iteratively refines depth estimation through a recurrent spiking neural network (RSNN) update module. To benchmark our approach, we introduce a large-scale synthetic spike stream dataset and a real-world stereo spike dataset with dense depth annotations. SpikeStereoNet outperforms existing methods on both datasets by leveraging spike streams' ability to capture subtle edges and intensity shifts in challenging regions such as textureless surfaces and extreme lighting conditions. Furthermore, our framework exhibits strong data efficiency, maintaining high accuracy even with substantially reduced training data. The source code and datasets will be publicly available.
Token Reduction Should Go Beyond Efficiency in Generative Models -- From Vision, Language to Multimodality
May 23, 2025In Transformer architectures, tokens\textemdash discrete units derived from raw data\textemdash are formed by segmenting inputs into fixed-length chunks. Each token is then mapped to an embedding, enabling parallel attention computations while preserving the input's essential information. Due to the quadratic computational complexity of transformer self-attention mechanisms, token reduction has primarily been used as an efficiency strategy. This is especially true in single vision and language domains, where it helps balance computational costs, memory usage, and inference latency. Despite these advances, this paper argues that token reduction should transcend its traditional efficiency-oriented role in the era of large generative models. Instead, we position it as a fundamental principle in generative modeling, critically influencing both model architecture and broader applications. Specifically, we contend that across vision, language, and multimodal systems, token reduction can: (i) facilitate deeper multimodal integration and alignment, (ii) mitigate "overthinking" and hallucinations, (iii) maintain coherence over long inputs, and (iv) enhance training stability, etc. We reframe token reduction as more than an efficiency measure. By doing so, we outline promising future directions, including algorithm design, reinforcement learning-guided token reduction, token optimization for in-context learning, and broader ML and scientific domains. We highlight its potential to drive new model architectures and learning strategies that improve robustness, increase interpretability, and better align with the objectives of generative modeling.
Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
May 22, 2025

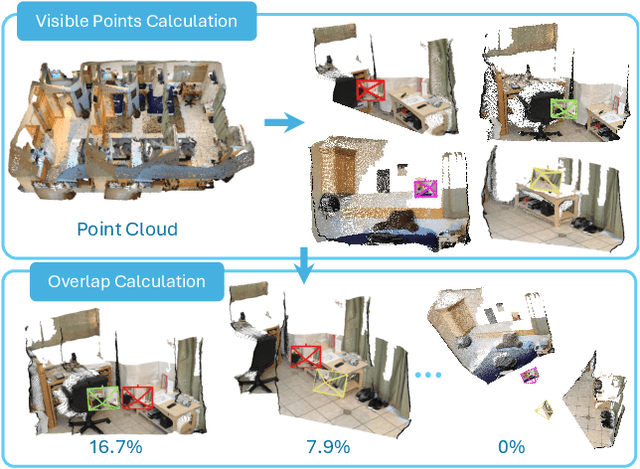
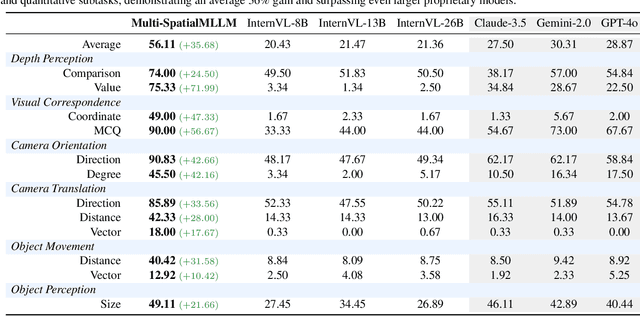
Multi-modal large language models (MLLMs) have rapidly advanced in visual tasks, yet their spatial understanding remains limited to single images, leaving them ill-suited for robotics and other real-world applications that require multi-frame reasoning. In this paper, we propose a framework to equip MLLMs with robust multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception. Central to our approach is the MultiSPA dataset, a novel, large-scale collection of more than 27 million samples spanning diverse 3D and 4D scenes. Alongside MultiSPA, we introduce a comprehensive benchmark that tests a wide spectrum of spatial tasks under uniform metrics. Our resulting model, Multi-SpatialMLLM, achieves significant gains over baselines and proprietary systems, demonstrating scalable, generalizable multi-frame reasoning. We further observe multi-task benefits and early indications of emergent capabilities in challenging scenarios, and showcase how our model can serve as a multi-frame reward annotator for robotics.
SAMba-UNet: Synergizing SAM2 and Mamba in UNet with Heterogeneous Aggregation for Cardiac MRI Segmentation
May 22, 2025



To address the challenge of complex pathological feature extraction in automated cardiac MRI segmentation, this study proposes an innovative dual-encoder architecture named SAMba-UNet. The framework achieves cross-modal feature collaborative learning by integrating the vision foundation model SAM2, the state-space model Mamba, and the classical UNet. To mitigate domain discrepancies between medical and natural images, a Dynamic Feature Fusion Refiner is designed, which enhances small lesion feature extraction through multi-scale pooling and a dual-path calibration mechanism across channel and spatial dimensions. Furthermore, a Heterogeneous Omni-Attention Convergence Module (HOACM) is introduced, combining global contextual attention with branch-selective emphasis mechanisms to effectively fuse SAM2's local positional semantics and Mamba's long-range dependency modeling capabilities. Experiments on the ACDC cardiac MRI dataset demonstrate that the proposed model achieves a Dice coefficient of 0.9103 and an HD95 boundary error of 1.0859 mm, significantly outperforming existing methods, particularly in boundary localization for complex pathological structures such as right ventricular anomalies. This work provides an efficient and reliable solution for automated cardiac disease diagnosis, and the code will be open-sourced.
Replace in Translation: Boost Concept Alignment in Counterfactual Text-to-Image
May 20, 2025



Text-to-Image (T2I) has been prevalent in recent years, with most common condition tasks having been optimized nicely. Besides, counterfactual Text-to-Image is obstructing us from a more versatile AIGC experience. For those scenes that are impossible to happen in real world and anti-physics, we should spare no efforts in increasing the factual feel, which means synthesizing images that people think very likely to be happening, and concept alignment, which means all the required objects should be in the same frame. In this paper, we focus on concept alignment. As controllable T2I models have achieved satisfactory performance for real applications, we utilize this technology to replace the objects in a synthesized image in latent space step-by-step to change the image from a common scene to a counterfactual scene to meet the prompt. We propose a strategy to instruct this replacing process, which is called as Explicit Logical Narrative Prompt (ELNP), by using the newly SoTA language model DeepSeek to generate the instructions. Furthermore, to evaluate models' performance in counterfactual T2I, we design a metric to calculate how many required concepts in the prompt can be covered averagely in the synthesized images. The extensive experiments and qualitative comparisons demonstrate that our strategy can boost the concept alignment in counterfactual T2I.
Structured Agent Distillation for Large Language Model
May 20, 2025
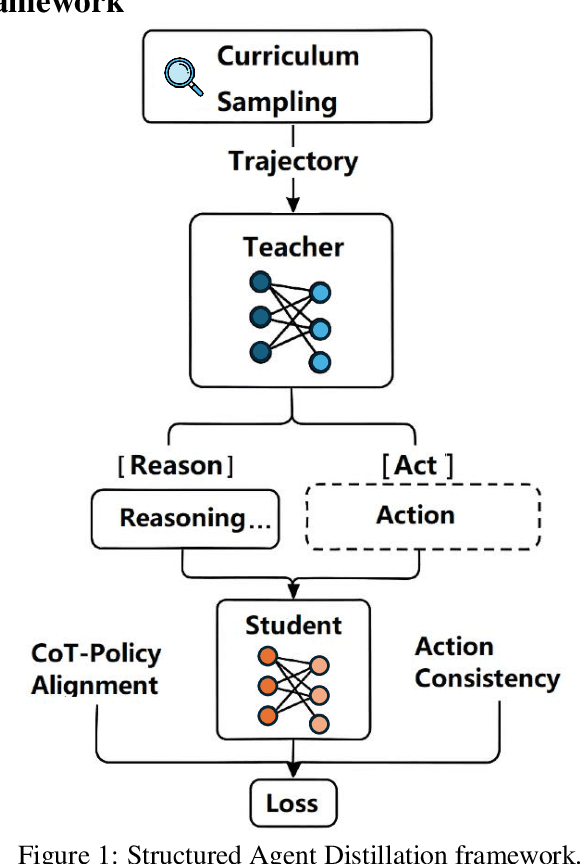

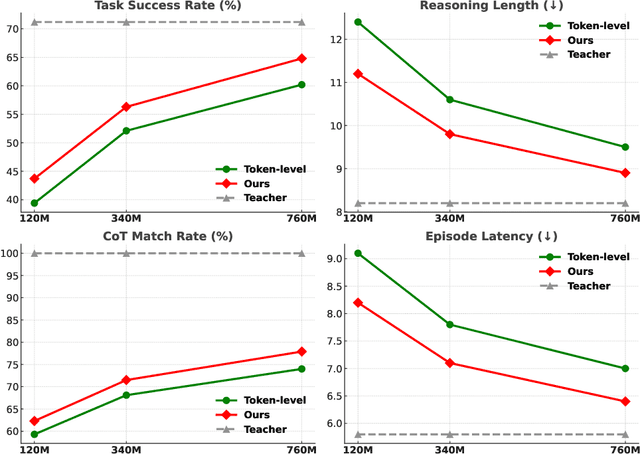
Large language models (LLMs) exhibit strong capabilities as decision-making agents by interleaving reasoning and actions, as seen in ReAct-style frameworks. Yet, their practical deployment is constrained by high inference costs and large model sizes. We propose Structured Agent Distillation, a framework that compresses large LLM-based agents into smaller student models while preserving both reasoning fidelity and action consistency. Unlike standard token-level distillation, our method segments trajectories into {[REASON]} and {[ACT]} spans, applying segment-specific losses to align each component with the teacher's behavior. This structure-aware supervision enables compact agents to better replicate the teacher's decision process. Experiments on ALFWorld, HotPotQA-ReAct, and WebShop show that our approach consistently outperforms token-level and imitation learning baselines, achieving significant compression with minimal performance drop. Scaling and ablation results further highlight the importance of span-level alignment for efficient and deployable agents.
Programmatic Video Prediction Using Large Language Models
May 20, 2025The task of estimating the world model describing the dynamics of a real world process assumes immense importance for anticipating and preparing for future outcomes. For applications such as video surveillance, robotics applications, autonomous driving, etc. this objective entails synthesizing plausible visual futures, given a few frames of a video to set the visual context. Towards this end, we propose ProgGen, which undertakes the task of video frame prediction by representing the dynamics of the video using a set of neuro-symbolic, human-interpretable set of states (one per frame) by leveraging the inductive biases of Large (Vision) Language Models (LLM/VLM). In particular, ProgGen utilizes LLM/VLM to synthesize programs: (i) to estimate the states of the video, given the visual context (i.e. the frames); (ii) to predict the states corresponding to future time steps by estimating the transition dynamics; (iii) to render the predicted states as visual RGB-frames. Empirical evaluations reveal that our proposed method outperforms competing techniques at the task of video frame prediction in two challenging environments: (i) PhyWorld (ii) Cart Pole. Additionally, ProgGen permits counter-factual reasoning and interpretable video generation attesting to its effectiveness and generalizability for video generation tasks.
CtrlDiff: Boosting Large Diffusion Language Models with Dynamic Block Prediction and Controllable Generation
May 20, 2025Although autoregressive models have dominated language modeling in recent years, there has been a growing interest in exploring alternative paradigms to the conventional next-token prediction framework. Diffusion-based language models have emerged as a compelling alternative due to their powerful parallel generation capabilities and inherent editability. However, these models are often constrained by fixed-length generation. A promising direction is to combine the strengths of both paradigms, segmenting sequences into blocks, modeling autoregressive dependencies across blocks while leveraging discrete diffusion to estimate the conditional distribution within each block given the preceding context. Nevertheless, their practical application is often hindered by two key limitations: rigid fixed-length outputs and a lack of flexible control mechanisms. In this work, we address the critical limitations of fixed granularity and weak controllability in current large diffusion language models. We propose CtrlDiff, a dynamic and controllable semi-autoregressive framework that adaptively determines the size of each generation block based on local semantics using reinforcement learning. Furthermore, we introduce a classifier-guided control mechanism tailored to discrete diffusion, which significantly reduces computational overhead while facilitating efficient post-hoc conditioning without retraining. Extensive experiments demonstrate that CtrlDiff sets a new standard among hybrid diffusion models, narrows the performance gap to state-of-the-art autoregressive approaches, and enables effective conditional text generation across diverse tasks.
PoE-World: Compositional World Modeling with Products of Programmatic Experts
May 16, 2025Learning how the world works is central to building AI agents that can adapt to complex environments. Traditional world models based on deep learning demand vast amounts of training data, and do not flexibly update their knowledge from sparse observations. Recent advances in program synthesis using Large Language Models (LLMs) give an alternate approach which learns world models represented as source code, supporting strong generalization from little data. To date, application of program-structured world models remains limited to natural language and grid-world domains. We introduce a novel program synthesis method for effectively modeling complex, non-gridworld domains by representing a world model as an exponentially-weighted product of programmatic experts (PoE-World) synthesized by LLMs. We show that this approach can learn complex, stochastic world models from just a few observations. We evaluate the learned world models by embedding them in a model-based planning agent, demonstrating efficient performance and generalization to unseen levels on Atari's Pong and Montezuma's Revenge. We release our code and display the learned world models and videos of the agent's gameplay at https://topwasu.github.io/poe-world.