 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\texttt{DeepSqueeze}$: Decentralization Meets Error-Compensated Compression
Aug 03, 2019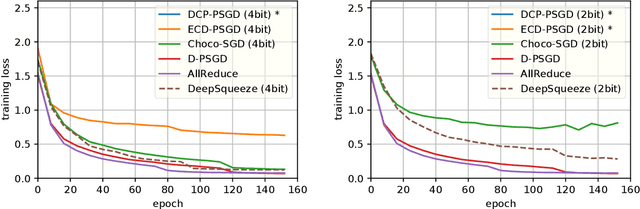
Communication is a key bottleneck in distributed training. Recently, an \emph{error-compensated} compression technology was particularly designed for the \emph{centralized} learning and receives huge successes, by showing significant advantages over state-of-the-art compression based methods in saving the communication cost. Since the \emph{decentralized} training has been witnessed to be superior to the traditional \emph{centralized} training in the communication restricted scenario, therefore a natural question to ask is "how to apply the error-compensated technology to the decentralized learning to further reduce the communication cost." However, a trivial extension of compression based centralized training algorithms does not exist for the decentralized scenario. key difference between centralized and decentralized training makes this extension extremely non-trivial. In this paper, we propose an elegant algorithmic design to employ error-compensated stochastic gradient descent for the decentralized scenario, named $\texttt{DeepSqueeze}$. Both the theoretical analysis and the empirical study are provided to show the proposed $\texttt{DeepSqueeze}$ algorithm outperforms the existing compression based decentralized learning algorithms. To the best of our knowledge, this is the first time to apply the error-compensated compression to the decentralized learning.
Generalization to Novel Objects using Prior Relational Knowledge
Jun 26, 2019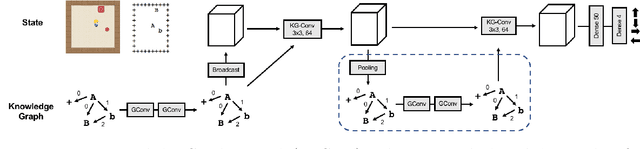
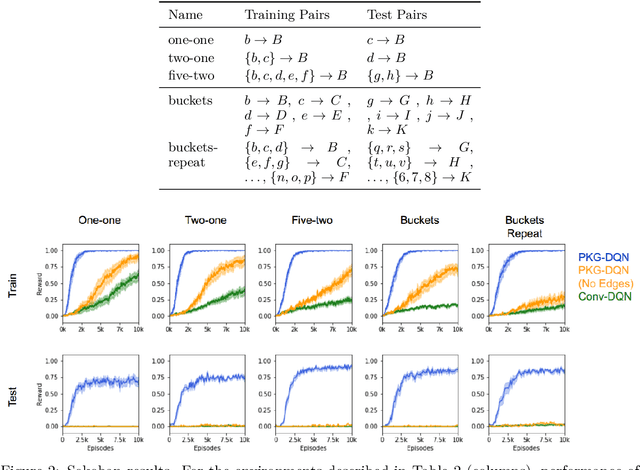
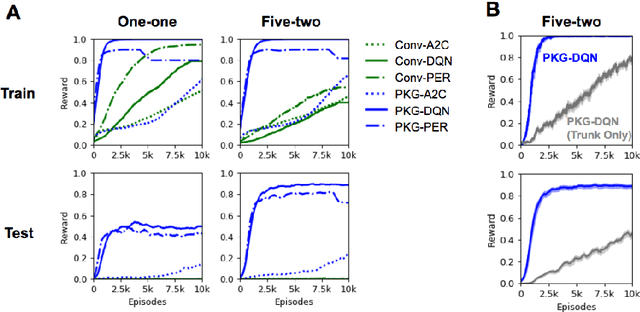
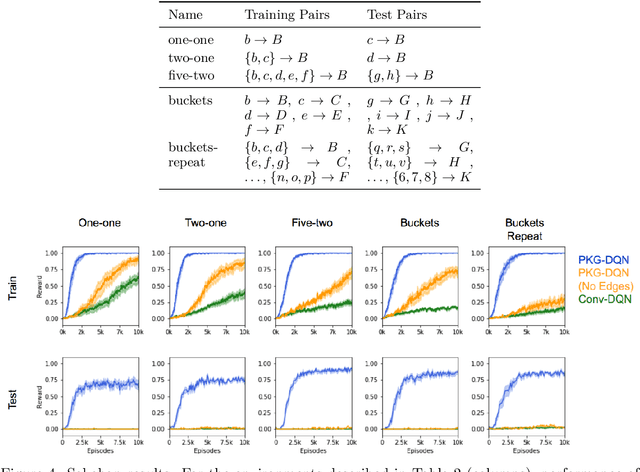
To solve tasks in new environments involving objects unseen during training, agents must reason over prior information about those objects and their relations. We introduce the Prior Knowledge Graph network, an architecture for combining prior information, structured as a knowledge graph, with a symbolic parsing of the visual scene, and demonstrate that this approach is able to apply learned relations to novel objects whereas the baseline algorithms fail. Ablation experiments show that the agents ground the knowledge graph relations to semantically-relevant behaviors. In both a Sokoban game and the more complex Pacman environment, our network is also more sample efficient than the baselines, reaching the same performance in 5-10x fewer episodes. Once the agents are trained with our approach, we can manipulate agent behavior by modifying the knowledge graph in semantically meaningful ways. These results suggest that our network provides a framework for agents to reason over structured knowledge graphs while still leveraging gradient based learning approaches.
Amur Tiger Re-identification in the Wild
Jun 14, 2019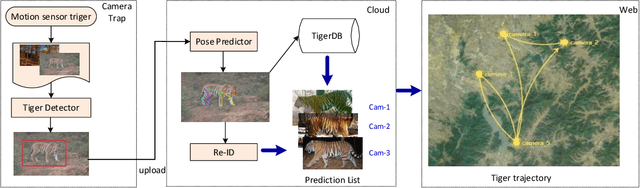

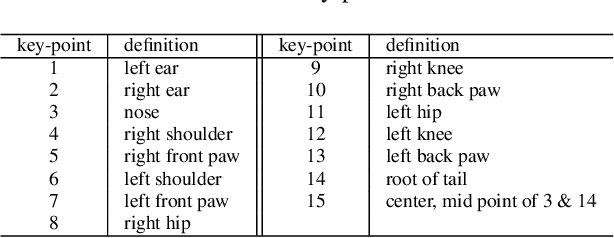
Monitoring the population and movements of endangered species is an important task to wildlife conversation. Traditional tagging methods do not scale to large populations, while applying computer vision methods to camera sensor data requires re-identification (re-ID) algorithms to obtain accurate counts and moving trajectory of wildlife. However, existing re-ID methods are largely targeted at persons and cars, which have limited pose variations and constrained capture environments. This paper tries to fill the gap by introducing a novel large-scale dataset, the Amur Tiger Re-identification in the Wild (ATRW) dataset. ATRW contains over 8,000 video clips from 92 Amur tigers, with bounding box, pose keypoint, and tiger identity annotations. In contrast to typical re-ID datasets, the tigers are captured in a diverse set of unconstrained poses and lighting conditions. We demonstrate with a set of baseline algorithms that ATRW is a challenging dataset for re-ID. Lastly, we propose a novel method for tiger re-identification, which introduces precise pose parts modeling in deep neural networks to handle large pose variation of tigers, and reaches notable performance improvement over existing re-ID methods. The dataset will be public available at https://cvwc2019.github.io/ .
DoubleSqueeze: Parallel Stochastic Gradient Descent with Double-Pass Error-Compensated Compression
May 15, 2019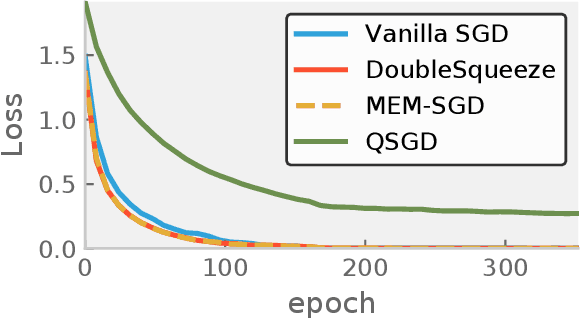
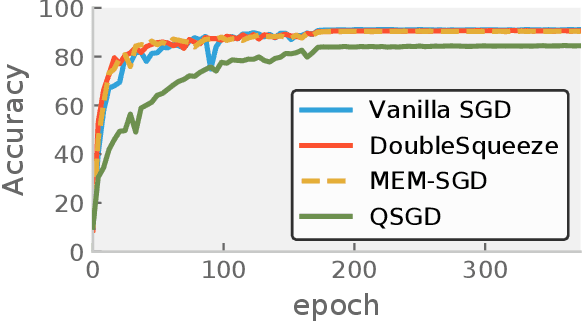
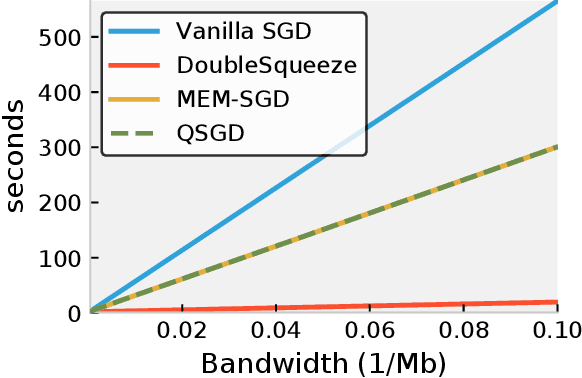
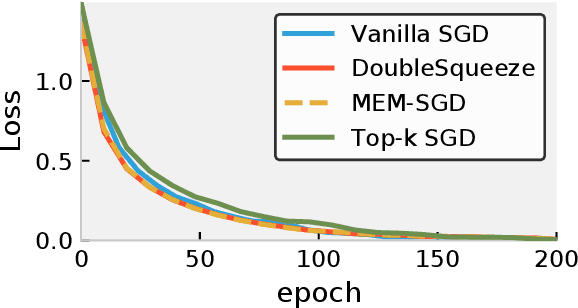
A standard approach in large scale machine learning is distributed stochastic gradient training, which requires the computation of aggregated stochastic gradients over multiple nodes on a network. Communication is a major bottleneck in such applications, and in recent years, compressed stochastic gradient methods such as QSGD (quantized SGD) and sparse SGD have been proposed to reduce communication. It was also shown that error compensation can be combined with compression to achieve better convergence in a scheme that each node compresses its local stochastic gradient and broadcast the result to all other nodes over the network in a single pass. However, such a single pass broadcast approach is not realistic in many practical implementations. For example, under the popular parameter server model for distributed learning, the worker nodes need to send the compressed local gradients to the parameter server, which performs the aggregation. The parameter server has to compress the aggregated stochastic gradient again before sending it back to the worker nodes. In this work, we provide a detailed analysis on this two-pass communication model and its asynchronous parallel variant, with error-compensated compression both on the worker nodes and on the parameter server. We show that the error-compensated stochastic gradient algorithm admits three very nice properties: 1) it is compatible with an \emph{arbitrary} compression technique; 2) it admits an improved convergence rate than the non error-compensated stochastic gradient methods such as QSGD and sparse SGD; 3) it admits linear speedup with respect to the number of workers. The empirical study is also conducted to validate our theoretical results.
Compact Scene Graphs for Layout Composition and Patch Retrieval
Apr 19, 2019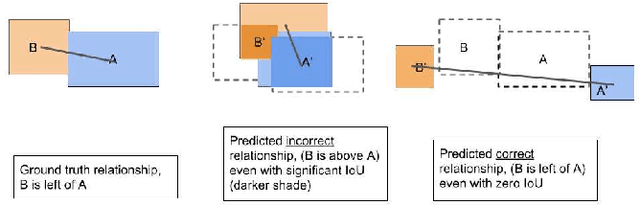

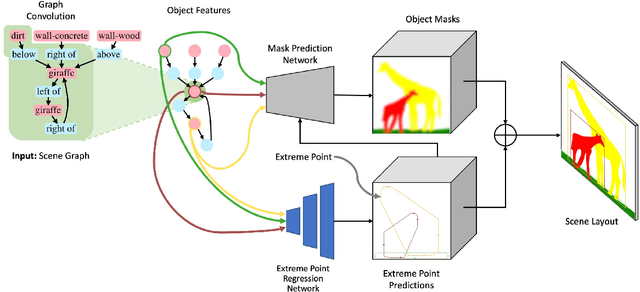

Structured representations such as scene graphs serve as an efficient and compact representation that can be used for downstream rendering or retrieval tasks. However, existing efforts to generate realistic images from scene graphs perform poorly on scene composition for cluttered or complex scenes. We propose two contributions to improve the scene composition. First, we enhance the scene graph representation with heuristic-based relations, which add minimal storage overhead. Second, we use extreme points representation to supervise the learning of the scene composition network. These methods achieve significantly higher performance over existing work (69.0% vs 51.2% in relation score metric). We additionally demonstrate how scene graphs can be used to retrieve pose-constrained image patches that are semantically similar to the source query. Improving structured scene graph representations for rendering or retrieval is an important step towards realistic image generation.
SpaceNet MVOI: a Multi-View Overhead Imagery Dataset
Mar 28, 2019
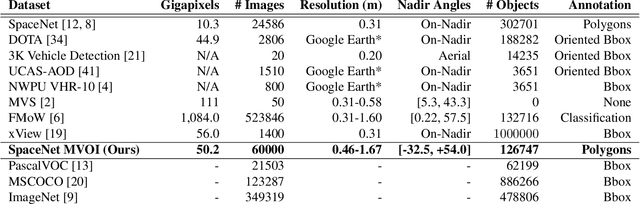
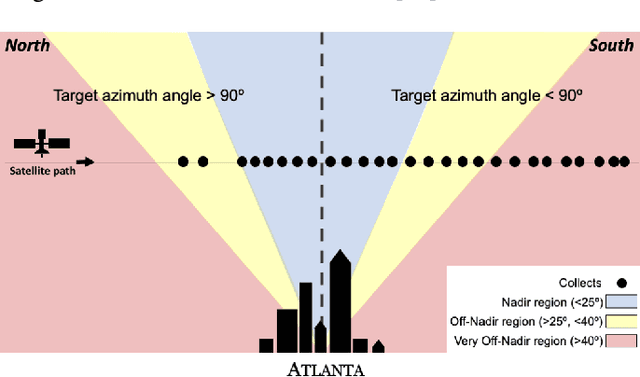

Detection and segmentation of objects in overheard imagery is a challenging task. The variable density, random orientation, small size, and instance-to-instance heterogeneity of objects in overhead imagery calls for approaches distinct from existing models designed for natural scene datasets. Though new overhead imagery datasets are being developed, they almost universally comprise a single view taken from directly overhead ("at nadir"), failing to address one critical variable: look angle. By contrast, views vary in real-world overhead imagery, particularly in dynamic scenarios such as natural disasters where first looks are often over 40 degrees off-nadir. This represents an important challenge to computer vision methods, as changing view angle adds distortions, alters resolution, and changes lighting. At present, the impact of these perturbations for algorithmic detection and segmentation of objects is untested. To address this problem, we introduce the SpaceNet Multi-View Overhead Imagery (MVOI) Dataset, an extension of the SpaceNet open source remote sensing dataset. MVOI comprises 27 unique looks from a broad range of viewing angles (-32 to 54 degrees). Each of these images cover the same geography and are annotated with 126,747 building footprint labels, enabling direct assessment of the impact of viewpoint perturbation on model performance. We benchmark multiple leading segmentation and object detection models on: (1) building detection, (2) generalization to unseen viewing angles and resolutions, and (3) sensitivity of building footprint extraction to changes in resolution. We find that segmentation and object detection models struggle to identify buildings in off-nadir imagery and generalize poorly to unseen views, presenting an important benchmark to explore the broadly relevant challenge of detecting small, heterogeneous target objects in visually dynamic contexts.
Using Scene Graph Context to Improve Image Generation
Jan 15, 2019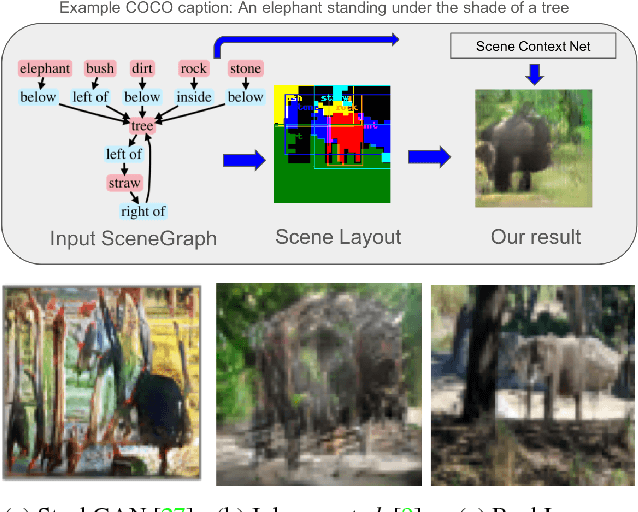

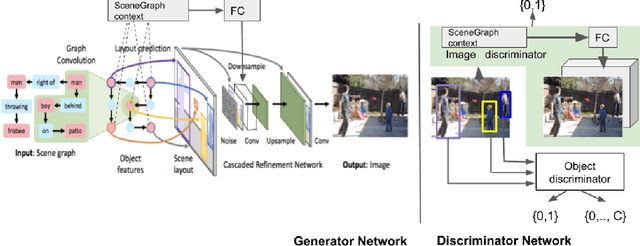

Generating realistic images from scene graphs asks neural networks to be able to reason about object relationships and compositionality. As a relatively new task, how to properly ensure the generated images comply with scene graphs or how to measure task performance remains an open question. In this paper, we propose to harness scene graph context to improve image generation from scene graphs. We introduce a scene graph context network that pools features generated by a graph convolutional neural network that are then provided to both the image generation network and the adversarial loss. With the context network, our model is trained to not only generate realistic looking images, but also to better preserve non-spatial object relationships. We also define two novel evaluation metrics, the relation score and the mean opinion relation score, for this task that directly evaluate scene graph compliance. We use both quantitative and qualitative studies to demonstrate that our pro-posed model outperforms the state-of-the-art on this challenging task.
Distributed Learning over Unreliable Networks
Oct 17, 2018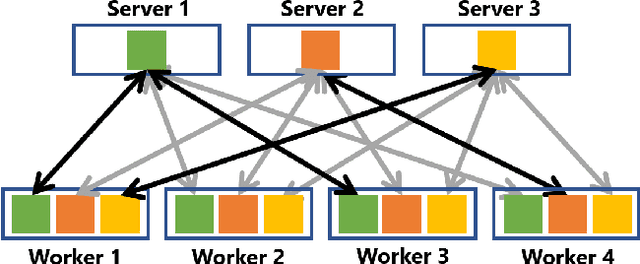
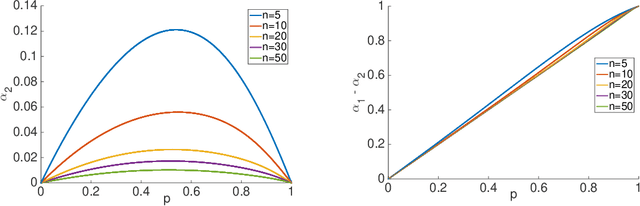
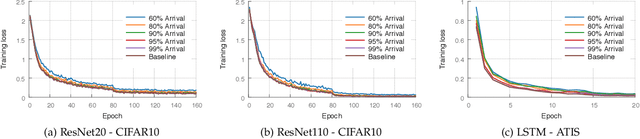
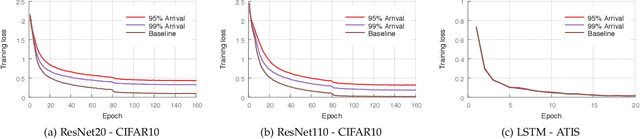
Most of today's distributed machine learning systems assume {\em reliable networks}: whenever two machines exchange information (e.g., gradients or models), the network should guarantee the delivery of the message. At the same time, recent work exhibits the impressive tolerance of machine learning algorithms to errors or noise arising from relaxed communication or synchronization. In this paper, we connect these two trends, and consider the following question: {\em Can we design machine learning systems that are tolerant to network unreliability during training?} With this motivation, we focus on a theoretical problem of independent interest---given a standard distributed parameter server architecture, if every communication between the worker and the server has a non-zero probability $p$ of being dropped, does there exist an algorithm that still converges, and at what speed? In the context of prior art, this problem can be phrased as {\em distributed learning over random topologies}. The technical contribution of this paper is a novel theoretical analysis proving that distributed learning over random topologies can achieve comparable convergence rate to centralized or distributed learning over reliable networks. Further, we prove that the influence of the packet drop rate diminishes with the growth of the number of \textcolor{black}{parameter servers}. We map this theoretical result onto a real-world scenario, training deep neural networks over an unreliable network layer, and conduct network simulation to validate the system improvement by allowing the networks to be unreliable.
Communication Compression for Decentralized Training
Sep 27, 2018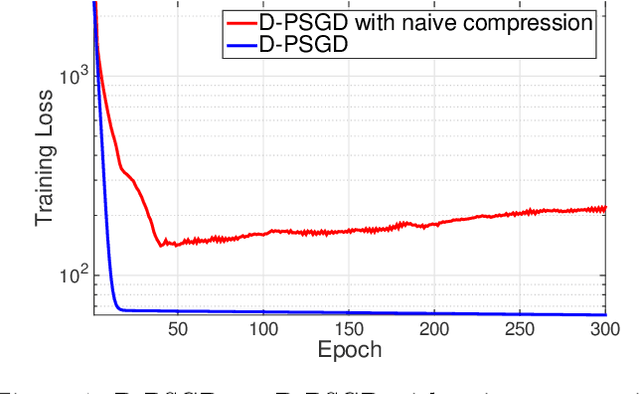
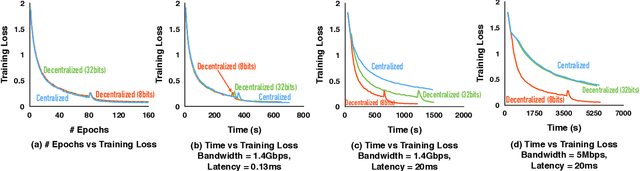
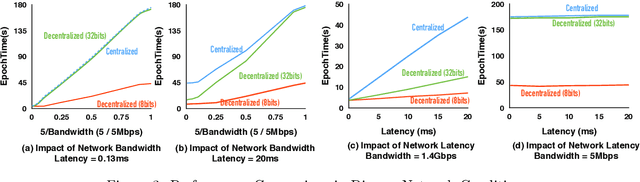
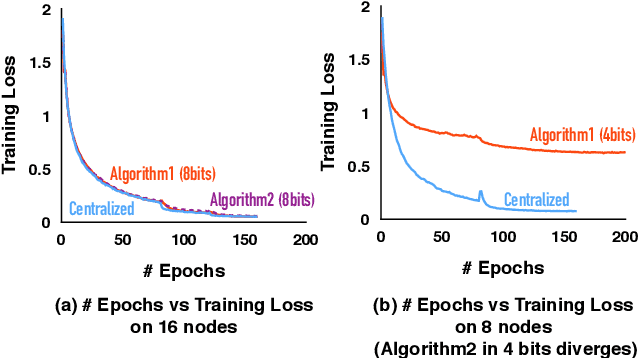
Optimizing distributed learning systems is an art of balancing between computation and communication. There have been two lines of research that try to deal with slower networks: {\em communication compression} for low bandwidth networks, and {\em decentralization} for high latency networks. In this paper, We explore a natural question: {\em can the combination of both techniques lead to a system that is robust to both bandwidth and latency?} Although the system implication of such combination is trivial, the underlying theoretical principle and algorithm design is challenging: unlike centralized algorithms, simply compressing exchanged information, even in an unbiased stochastic way, within the decentralized network would accumulate the error and fail to converge. In this paper, we develop a framework of compressed, decentralized training and propose two different strategies, which we call {\em extrapolation compression} and {\em difference compression}. We analyze both algorithms and prove both converge at the rate of $O(1/\sqrt{nT})$ where $n$ is the number of workers and $T$ is the number of iterations, matching the convergence rate for full precision, centralized training. We validate our algorithms and find that our proposed algorithm outperforms the best of merely decentralized and merely quantized algorithm significantly for networks with {\em both} high latency and low bandwidth.
D$^2$: Decentralized Training over Decentralized Data
Apr 20, 2018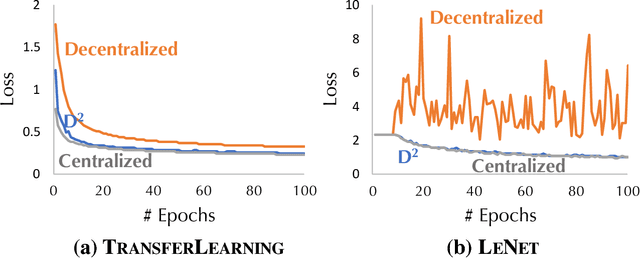
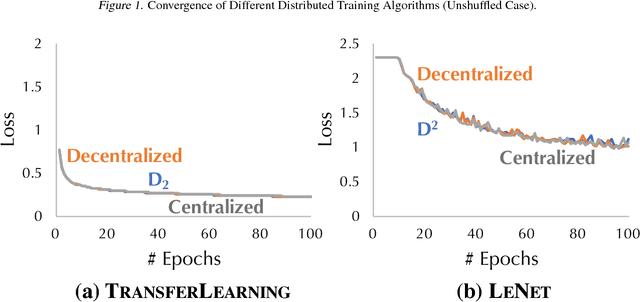
While training a machine learning model using multiple workers, each of which collects data from their own data sources, it would be most useful when the data collected from different workers can be {\em unique} and {\em different}. Ironically, recent analysis of decentralized parallel stochastic gradient descent (D-PSGD) relies on the assumption that the data hosted on different workers are {\em not too different}. In this paper, we ask the question: {\em Can we design a decentralized parallel stochastic gradient descent algorithm that is less sensitive to the data variance across workers?} In this paper, we present D$^2$, a novel decentralized parallel stochastic gradient descent algorithm designed for large data variance \xr{among workers} (imprecisely, "decentralized" data). The core of D$^2$ is a variance blackuction extension of the standard D-PSGD algorithm, which improves the convergence rate from $O\left({\sigma \over \sqrt{nT}} + {(n\zeta^2)^{\frac{1}{3}} \over T^{2/3}}\right)$ to $O\left({\sigma \over \sqrt{nT}}\right)$ where $\zeta^{2}$ denotes the variance among data on different workers. As a result, D$^2$ is robust to data variance among workers. We empirically evaluated D$^2$ on image classification tasks where each worker has access to only the data of a limited set of labels, and find that D$^2$ significantly outperforms D-PSGD.