 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Query-Based Image Retrieval Using Scene Graphs
May 13, 2020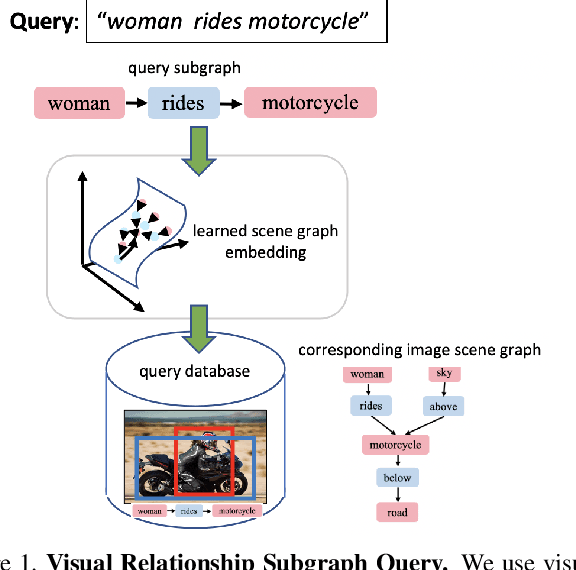
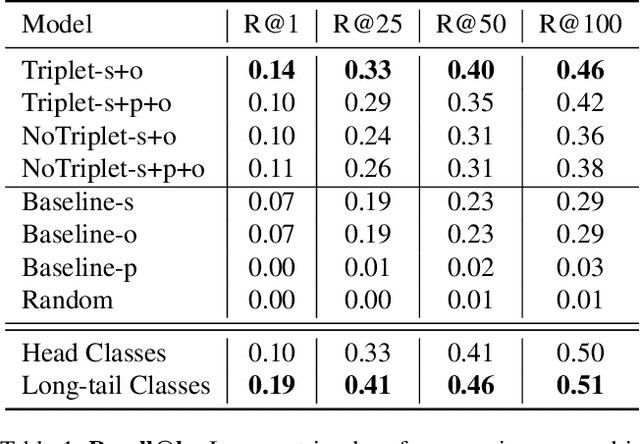
A structured query can capture the complexity of object interactions (e.g. 'woman rides motorcycle') unlike single objects (e.g. 'woman' or 'motorcycle'). Retrieval using structured queries therefore is much more useful than single object retrieval, but a much more challenging problem. In this paper we present a method which uses scene graph embeddings as the basis for an approach to image retrieval. We examine how visual relationships, derived from scene graphs, can be used as structured queries. The visual relationships are directed subgraphs of the scene graph with a subject and object as nodes connected by a predicate relationship. Notably, we are able to achieve high recall even on low to medium frequency objects found in the long-tailed COCO-Stuff dataset, and find that adding a visual relationship-inspired loss boosts our recall by 10% in the best case.
Using Image Priors to Improve Scene Understanding
Oct 02, 2019
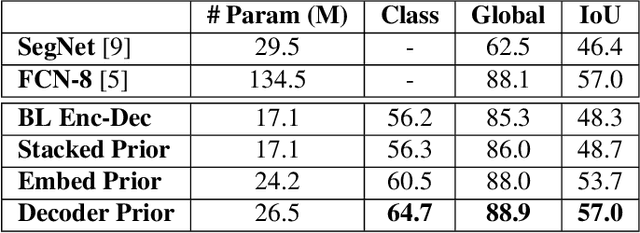
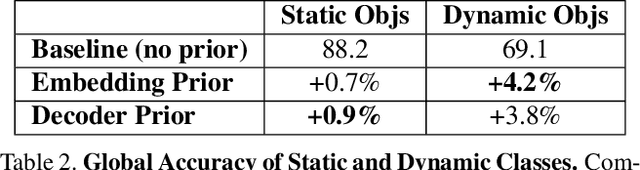
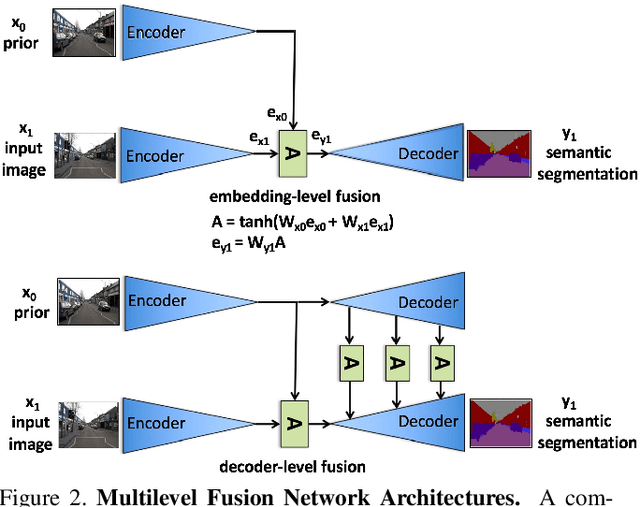
Semantic segmentation algorithms that can robustly segment objects across multiple camera viewpoints are crucial for assuring navigation and safety in emerging applications such as autonomous driving. Existing algorithms treat each image in isolation, but autonomous vehicles often revisit the same locations or maintain information from the immediate past. We propose a simple yet effective method for leveraging these image priors to improve semantic segmentation of images from sequential driving datasets. We examine several methods to fuse these temporal scene priors, and introduce a prior fusion network that is able to learn how to transfer this information. The prior fusion model improves the accuracy over the non-prior baseline from 69.1% to 73.3% for dynamic classes, and from 88.2% to 89.1% for static classes. Compared to models such as FCN-8, our prior method achieves the same accuracy with 5 times fewer parameters. We used a simple encoder decoder backbone, but this general prior fusion method could be applied to more complex semantic segmentation backbones. We also discuss how structured representations of scenes in the form of a scene graph could be leveraged as priors to further improve scene understanding.
Triplet-Aware Scene Graph Embeddings
Sep 19, 2019
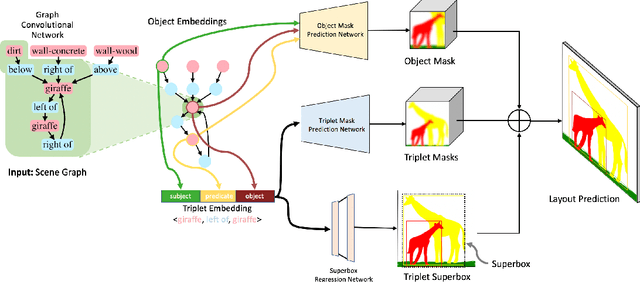

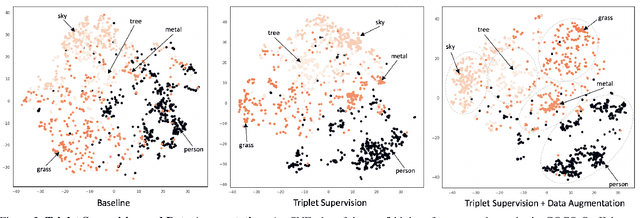
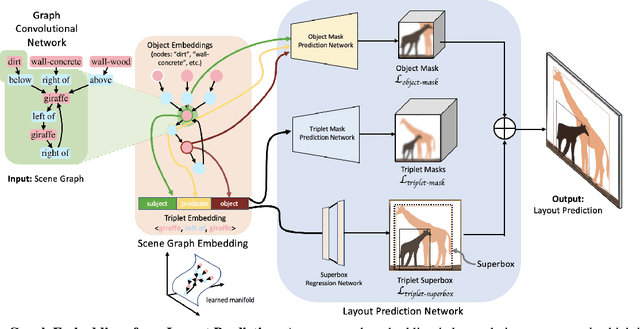
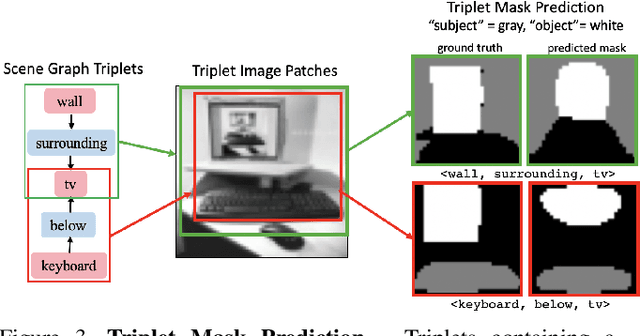
Scene graphs have become an important form of structured knowledge for tasks such as for image generation, visual relation detection, visual question answering, and image retrieval. While visualizing and interpreting word embeddings is well understood, scene graph embeddings have not been fully explored. In this work, we train scene graph embeddings in a layout generation task with different forms of supervision, specifically introducing triplet super-vision and data augmentation. We see a significant performance increase in both metrics that measure the goodness of layout prediction, mean intersection-over-union (mIoU)(52.3% vs. 49.2%) and relation score (61.7% vs. 54.1%),after the addition of triplet supervision and data augmentation. To understand how these different methods affect the scene graph representation, we apply several new visualization and evaluation methods to explore the evolution of the scene graph embedding. We find that triplet supervision significantly improves the embedding separability, which is highly correlated with the performance of the layout prediction model.