 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomate Knowledge Concept Tagging on Math Questions with LLMs
Mar 26, 2024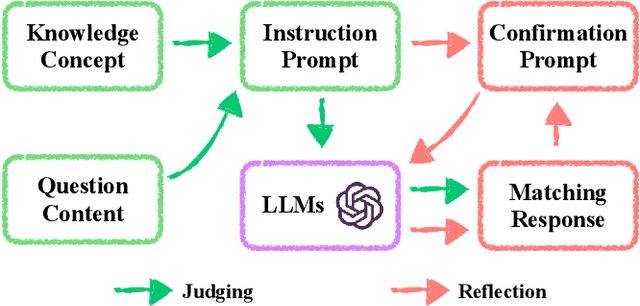
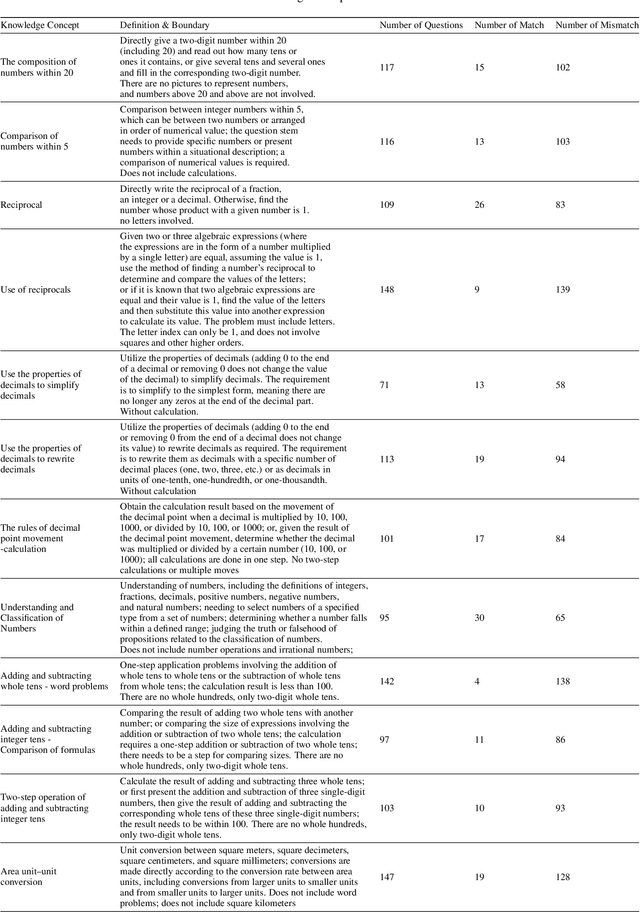
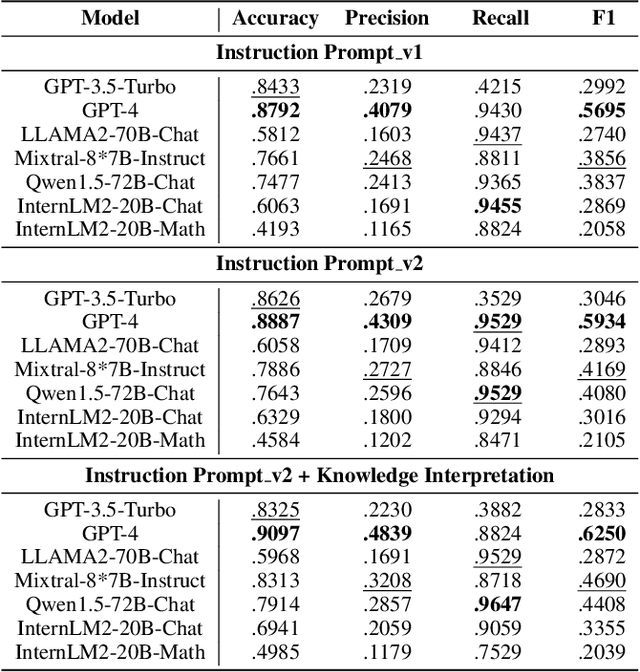
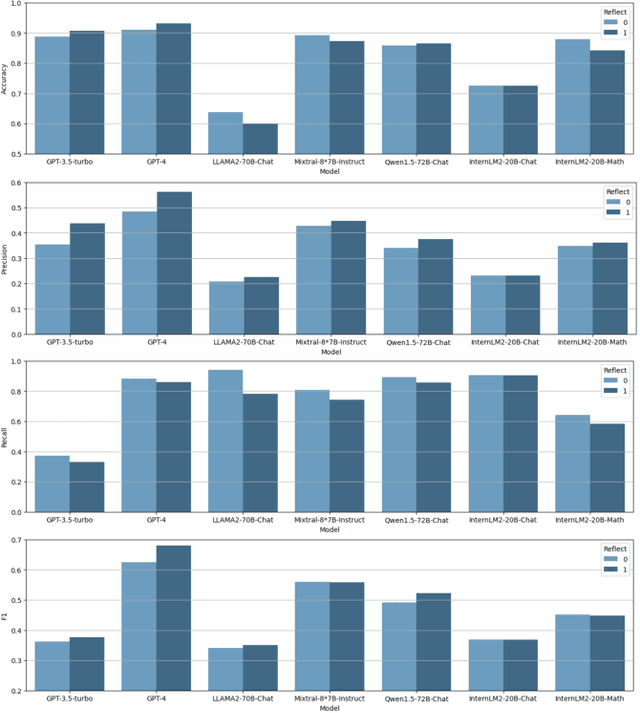
Knowledge concept tagging for questions plays a crucial role in contemporary intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations have been conducted manually with help from pedagogical experts, as the task requires not only a strong semantic understanding of both question stems and knowledge definitions but also deep insights into connecting question-solving logic with corresponding knowledge concepts. In this paper, we explore automating the tagging task using Large Language Models (LLMs), in response to the inability of prior manual methods to meet the rapidly growing demand for concept tagging in questions posed by advanced educational applications. Moreover, the zero/few-shot learning capability of LLMs makes them well-suited for application in educational scenarios, which often face challenges in collecting large-scale, expertise-annotated datasets. By conducting extensive experiments with a variety of representative LLMs, we demonstrate that LLMs are a promising tool for concept tagging in math questions. Furthermore, through case studies examining the results from different LLMs, we draw some empirical conclusions about the key factors for success in applying LLMs to the automatic concept tagging task.
RadioGAT: A Joint Model-based and Data-driven Framework for Multi-band Radiomap Reconstruction via Graph Attention Networks
Mar 25, 2024



Multi-band radiomap reconstruction (MB-RMR) is a key component in wireless communications for tasks such as spectrum management and network planning. However, traditional machine-learning-based MB-RMR methods, which rely heavily on simulated data or complete structured ground truth, face significant deployment challenges. These challenges stem from the differences between simulated and actual data, as well as the scarcity of real-world measurements. To address these challenges, our study presents RadioGAT, a novel framework based on Graph Attention Network (GAT) tailored for MB-RMR within a single area, eliminating the need for multi-region datasets. RadioGAT innovatively merges model-based spatial-spectral correlation encoding with data-driven radiomap generalization, thus minimizing the reliance on extensive data sources. The framework begins by transforming sparse multi-band data into a graph structure through an innovative encoding strategy that leverages radio propagation models to capture the spatial-spectral correlation inherent in the data. This graph-based representation not only simplifies data handling but also enables tailored label sampling during training, significantly enhancing the framework's adaptability for deployment. Subsequently, The GAT is employed to generalize the radiomap information across various frequency bands. Extensive experiments using raytracing datasets based on real-world environments have demonstrated RadioGAT's enhanced accuracy in supervised learning settings and its robustness in semi-supervised scenarios. These results underscore RadioGAT's effectiveness and practicality for MB-RMR in environments with limited data availability.
Driving Animatronic Robot Facial Expression From Speech
Mar 21, 2024



Animatronic robots aim to enable natural human-robot interaction through lifelike facial expressions. However, generating realistic, speech-synchronized robot expressions is challenging due to the complexities of facial biomechanics and responsive motion synthesis. This paper presents a principled, skinning-centric approach to drive animatronic robot facial expressions from speech. The proposed approach employs linear blend skinning (LBS) as the core representation to guide tightly integrated innovations in embodiment design and motion synthesis. LBS informs the actuation topology, enables human expression retargeting, and allows speech-driven facial motion generation. The proposed approach is capable of generating highly realistic, real-time facial expressions from speech on an animatronic face, significantly advancing robots' ability to replicate nuanced human expressions for natural interaction.
Finding the Missing Data: A BERT-inspired Approach Against Package Loss in Wireless Sensing
Mar 19, 2024



Despite the development of various deep learning methods for Wi-Fi sensing, package loss often results in noncontinuous estimation of the Channel State Information (CSI), which negatively impacts the performance of the learning models. To overcome this challenge, we propose a deep learning model based on Bidirectional Encoder Representations from Transformers (BERT) for CSI recovery, named CSI-BERT. CSI-BERT can be trained in an self-supervised manner on the target dataset without the need for additional data. Furthermore, unlike traditional interpolation methods that focus on one subcarrier at a time, CSI-BERT captures the sequential relationships across different subcarriers. Experimental results demonstrate that CSI-BERT achieves lower error rates and faster speed compared to traditional interpolation methods, even when facing with high loss rates. Moreover, by harnessing the recovered CSI obtained from CSI-BERT, other deep learning models like Residual Network and Recurrent Neural Network can achieve an average increase in accuracy of approximately 15\% in Wi-Fi sensing tasks. The collected dataset WiGesture and code for our model are publicly available at https://github.com/RS2002/CSI-BERT.
Rethinking Machine Unlearning for Large Language Models
Feb 15, 2024We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
Large Language Models as Agents in Two-Player Games
Feb 12, 2024By formally defining the training processes of large language models (LLMs), which usually encompasses pre-training, supervised fine-tuning, and reinforcement learning with human feedback, within a single and unified machine learning paradigm, we can glean pivotal insights for advancing LLM technologies. This position paper delineates the parallels between the training methods of LLMs and the strategies employed for the development of agents in two-player games, as studied in game theory, reinforcement learning, and multi-agent systems. We propose a re-conceptualization of LLM learning processes in terms of agent learning in language-based games. This framework unveils innovative perspectives on the successes and challenges in LLM development, offering a fresh understanding of addressing alignment issues among other strategic considerations. Furthermore, our two-player game approach sheds light on novel data preparation and machine learning techniques for training LLMs.
Boximator: Generating Rich and Controllable Motions for Video Synthesis
Feb 02, 2024



Generating rich and controllable motion is a pivotal challenge in video synthesis. We propose Boximator, a new approach for fine-grained motion control. Boximator introduces two constraint types: hard box and soft box. Users select objects in the conditional frame using hard boxes and then use either type of boxes to roughly or rigorously define the object's position, shape, or motion path in future frames. Boximator functions as a plug-in for existing video diffusion models. Its training process preserves the base model's knowledge by freezing the original weights and training only the control module. To address training challenges, we introduce a novel self-tracking technique that greatly simplifies the learning of box-object correlations. Empirically, Boximator achieves state-of-the-art video quality (FVD) scores, improving on two base models, and further enhanced after incorporating box constraints. Its robust motion controllability is validated by drastic increases in the bounding box alignment metric. Human evaluation also shows that users favor Boximator generation results over the base model.
TPRF: A Transformer-based Pseudo-Relevance Feedback Model for Efficient and Effective Retrieval
Jan 24, 2024This paper considers Pseudo-Relevance Feedback (PRF) methods for dense retrievers in a resource constrained environment such as that of cheap cloud instances or embedded systems (e.g., smartphones and smartwatches), where memory and CPU are limited and GPUs are not present. For this, we propose a transformer-based PRF method (TPRF), which has a much smaller memory footprint and faster inference time compared to other deep language models that employ PRF mechanisms, with a marginal effectiveness loss. TPRF learns how to effectively combine the relevance feedback signals from dense passage representations. Specifically, TPRF provides a mechanism for modelling relationships and weights between the query and the relevance feedback signals. The method is agnostic to the specific dense representation used and thus can be generally applied to any dense retriever.
ReFT: Reasoning with Reinforced Fine-Tuning
Jan 17, 2024



One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Dec 21, 2023



Generative pre-trained models have demonstrated remarkable effectiveness in language and vision domains by learning useful representations. In this paper, we extend the scope of this effectiveness by showing that visual robot manipulation can significantly benefit from large-scale video generative pre-training. We introduce GR-1, a straightforward GPT-style model designed for multi-task language-conditioned visual robot manipulation. GR-1 takes as inputs a language instruction, a sequence of observation images, and a sequence of robot states. It predicts robot actions as well as future images in an end-to-end manner. Thanks to a flexible design, GR-1 can be seamlessly finetuned on robot data after pre-trained on a large-scale video dataset. We perform extensive experiments on the challenging CALVIN benchmark and a real robot. On CALVIN benchmark, our method outperforms state-of-the-art baseline methods and improves the success rate from 88.9% to 94.9%. In the setting of zero-shot unseen scene generalization, GR-1 improves the success rate from 53.3% to 85.4%. In real robot experiments, GR-1 also outperforms baseline methods and shows strong potentials in generalization to unseen scenes and objects. We provide inaugural evidence that a unified GPT-style transformer, augmented with large-scale video generative pre-training, exhibits remarkable generalization to multi-task visual robot manipulation. Project page: https://GR1-Manipulation.github.io