 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMix-2: Establishing Protein as a Native Modality in Large Language Models
May 29, 2026We present AMix-2, a protein-text foundation model that establishes protein as a native modality in large language models (LLMs), unifying protein understanding and sequence design within a single foundation model. AMix-2 is built upon two key ideas: (1) a unified protein-text formulation that embeds natural language and protein sequence in a shared token space, enabling one model to perform biological reasoning and conditional design instead of separate downstream task-specialized models; and (2) a block-wise diffusion language modeling backbone that combines causal generation across blocks with bidirectional context and iterative refinement within blocks. This scheme better matches the intrinsic nature of proteins than a strict left-to-right factorization. To evaluate protein foundation models under realistic generalization settings, we further introduce ProteinArena, a comprehensive benchmark with time-aware and homology-aware protocols across various understanding and design tasks, and with baselines covering classical bioinformatics tools, protein-specialized models and LLMs. On ProteinArena, AMix-2 outperforms frontier LLMs and demonstrates competitive performance to task-specific protein models. Controlled experiments further show that the diffusion-based paradigm generally surpasses its autoregressive counterpart, highlighting the advantage of flexible generation order for protein sequences. We release both AMix-2 and ProteinArena to facilitate open research in protein foundation models.
Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
Feb 08, 2024



In this paper, we propose R$^3$: Learning Reasoning through Reverse Curriculum Reinforcement Learning (RL), a novel method that employs only outcome supervision to achieve the benefits of process supervision for large language models. The core challenge in applying RL to complex reasoning is to identify a sequence of actions that result in positive rewards and provide appropriate supervision for optimization. Outcome supervision provides sparse rewards for final results without identifying error locations, whereas process supervision offers step-wise rewards but requires extensive manual annotation. R$^3$ overcomes these limitations by learning from correct demonstrations. Specifically, R$^3$ progressively slides the start state of reasoning from a demonstration's end to its beginning, facilitating easier model exploration at all stages. Thus, R$^3$ establishes a step-wise curriculum, allowing outcome supervision to offer step-level signals and precisely pinpoint errors. Using Llama2-7B, our method surpasses RL baseline on eight reasoning tasks by $4.1$ points on average. Notebaly, in program-based reasoning on GSM8K, it exceeds the baseline by $4.2$ points across three backbone models, and without any extra data, Codellama-7B + R$^3$ performs comparable to larger models or closed-source models.
ReFT: Reasoning with Reinforced Fine-Tuning
Jan 17, 2024



One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
Design of Chain-of-Thought in Math Problem Solving
Sep 30, 2023Chain-of-Thought (CoT) plays a crucial role in reasoning for math problem solving. We conduct a comprehensive examination of methods for designing CoT, comparing conventional natural language CoT with various program CoTs, including the self-describing program, the comment-describing program, and the non-describing program. Furthermore, we investigate the impact of programming language on program CoTs, comparing Python and Wolfram Language. Through extensive experiments on GSM8K, MATHQA, and SVAMP, we find that program CoTs often have superior effectiveness in math problem solving. Notably, the best performing combination with 30B parameters beats GPT-3.5-turbo by a significant margin. The results show that self-describing program offers greater diversity and thus can generally achieve higher performance. We also find that Python is a better choice of language than Wolfram for program CoTs. The experimental results provide a valuable guideline for future CoT designs that take into account both programming language and coding style for further advancements. Our datasets and code are publicly available.
E-KAR: A Benchmark for Rationalizing Natural Language Analogical Reasoning
Mar 16, 2022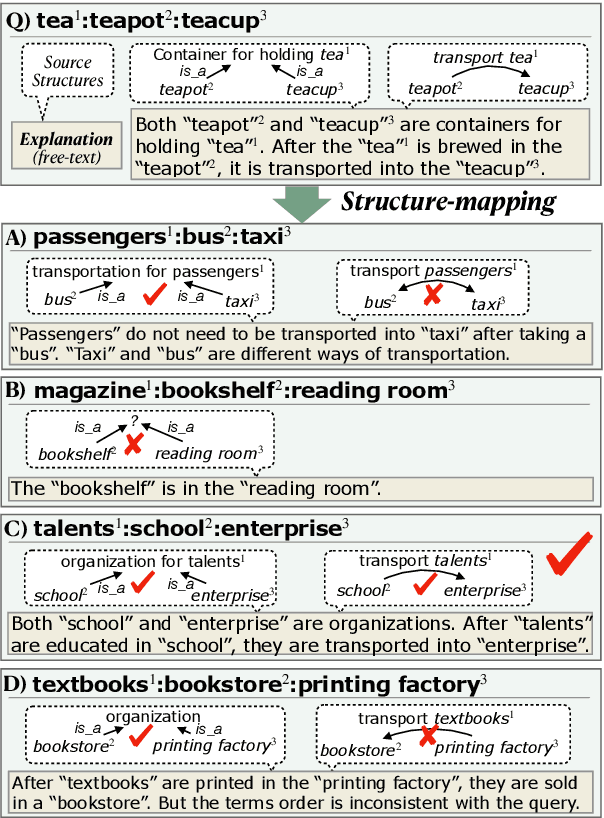
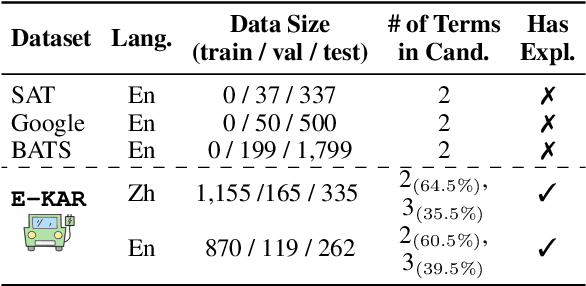
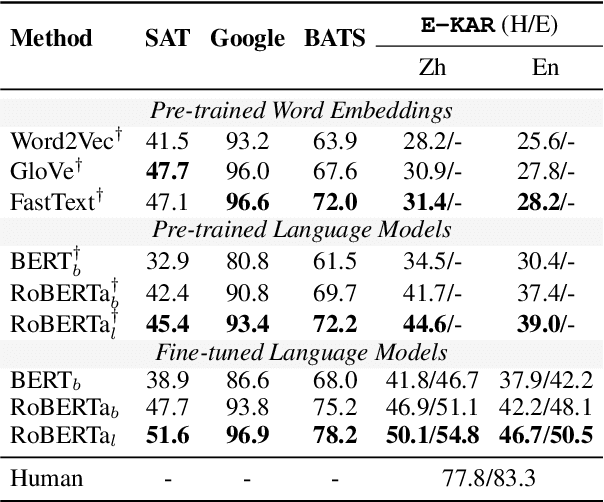
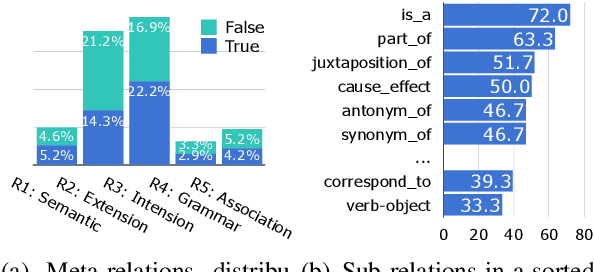
The ability to recognize analogies is fundamental to human cognition. Existing benchmarks to test word analogy do not reveal the underneath process of analogical reasoning of neural models. Holding the belief that models capable of reasoning should be right for the right reasons, we propose a first-of-its-kind Explainable Knowledge-intensive Analogical Reasoning benchmark (E-KAR). Our benchmark consists of 1,655 (in Chinese) and 1,251 (in English) problems sourced from the Civil Service Exams, which require intensive background knowledge to solve. More importantly, we design a free-text explanation scheme to explain whether an analogy should be drawn, and manually annotate them for each and every question and candidate answer. Empirical results suggest that this benchmark is very challenging for some state-of-the-art models for both explanation generation and analogical question answering tasks, which invites further research in this area.
Probabilistic Graph Reasoning for Natural Proof Generation
Jul 06, 2021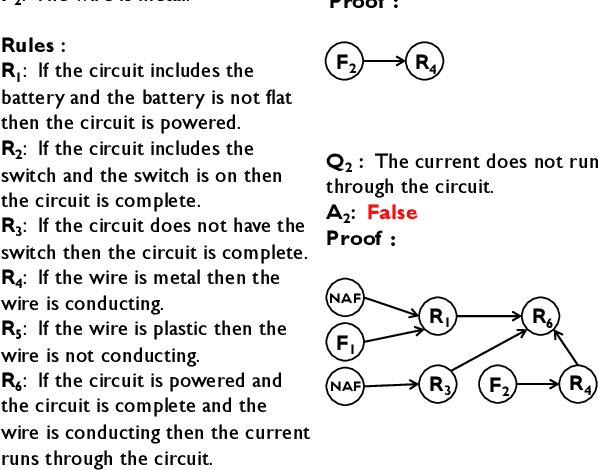
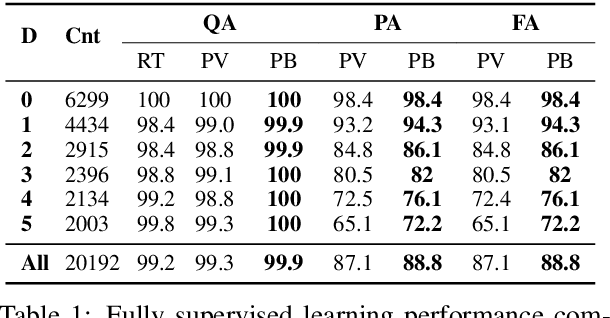
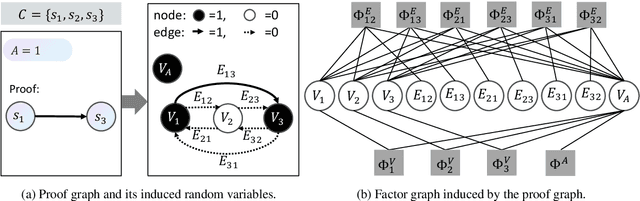

In this paper, we investigate the problem of reasoning over natural language statements. Prior neural based approaches do not explicitly consider the inter-dependency among answers and their proofs. In this paper, we propose PRobr, a novel approach for joint answer prediction and proof generation. PRobr defines a joint probabilistic distribution over all possible proof graphs and answers via an induced graphical model. We then optimize the model using variational approximation on top of neural textual representation. Experiments on multiple datasets under diverse settings (fully supervised, few-shot and zero-shot evaluation) verify the effectiveness of PRobr, e.g., achieving 10%-30% improvement on QA accuracy in few/zero-shot evaluation. Our codes and models can be found at https://github.com/changzhisun/PRobr/.