 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding high-resolution touch across robotic hands enables adaptive human-like grasping
Dec 19, 2024



Developing robotic hands that adapt to real-world dynamics remains a fundamental challenge in robotics and machine intelligence. Despite significant advances in replicating human hand kinematics and control algorithms, robotic systems still struggle to match human capabilities in dynamic environments, primarily due to inadequate tactile feedback. To bridge this gap, we present F-TAC Hand, a biomimetic hand featuring high-resolution tactile sensing (0.1mm spatial resolution) across 70% of its surface area. Through optimized hand design, we overcome traditional challenges in integrating high-resolution tactile sensors while preserving the full range of motion. The hand, powered by our generative algorithm that synthesizes human-like hand configurations, demonstrates robust grasping capabilities in dynamic real-world conditions. Extensive evaluation across 600 real-world trials demonstrates that this tactile-embodied system significantly outperforms non-tactile alternatives in complex manipulation tasks (p<0.0001). These results provide empirical evidence for the critical role of rich tactile embodiment in developing advanced robotic intelligence, offering new perspectives on the relationship between physical sensing capabilities and intelligent behavior.
Large-scale Deployment of Vision-based Tactile Sensors on Multi-fingered Grippers
Aug 05, 2024Vision-based Tactile Sensors (VBTSs) show significant promise in that they can leverage image measurements to provide high-spatial-resolution human-like performance. However, current VBTS designs, typically confined to the fingertips of robotic grippers, prove somewhat inadequate, as many grasping and manipulation tasks require multiple contact points with the object. With an end goal of enabling large-scale, multi-surface tactile sensing via VBTSs, our research (i) develops a synchronized image acquisition system with minimal latency,(ii) proposes a modularized VBTS design for easy integration into finger phalanges, and (iii) devises a zero-shot calibration approach to improve data efficiency in the simultaneous calibration of multiple VBTSs. In validating the system within a miniature 3-fingered robotic gripper equipped with 7 VBTSs we demonstrate improved tactile perception performance by covering the contact surfaces of both gripper fingers and palm. Additionally, we show that our VBTS design can be seamlessly integrated into various end-effector morphologies significantly reducing the data requirements for calibration.
Driving Animatronic Robot Facial Expression From Speech
Mar 21, 2024



Animatronic robots aim to enable natural human-robot interaction through lifelike facial expressions. However, generating realistic, speech-synchronized robot expressions is challenging due to the complexities of facial biomechanics and responsive motion synthesis. This paper presents a principled, skinning-centric approach to drive animatronic robot facial expressions from speech. The proposed approach employs linear blend skinning (LBS) as the core representation to guide tightly integrated innovations in embodiment design and motion synthesis. LBS informs the actuation topology, enables human expression retargeting, and allows speech-driven facial motion generation. The proposed approach is capable of generating highly realistic, real-time facial expressions from speech on an animatronic face, significantly advancing robots' ability to replicate nuanced human expressions for natural interaction.
Interpretable Foreground Object Search As Knowledge Distillation
Jul 22, 2020

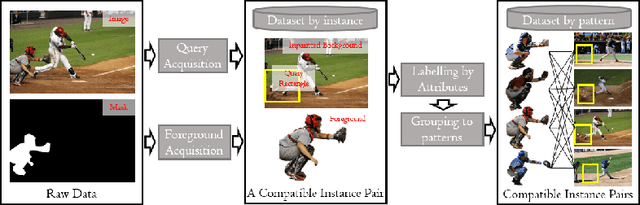

This paper proposes a knowledge distillation method for foreground object search (FoS). Given a background and a rectangle specifying the foreground location and scale, FoS retrieves compatible foregrounds in a certain category for later image composition. Foregrounds within the same category can be grouped into a small number of patterns. Instances within each pattern are compatible with any query input interchangeably. These instances are referred to as interchangeable foregrounds. We first present a pipeline to build pattern-level FoS dataset containing labels of interchangeable foregrounds. We then establish a benchmark dataset for further training and testing following the pipeline. As for the proposed method, we first train a foreground encoder to learn representations of interchangeable foregrounds. We then train a query encoder to learn query-foreground compatibility following a knowledge distillation framework. It aims to transfer knowledge from interchangeable foregrounds to supervise representation learning of compatibility. The query feature representation is projected to the same latent space as interchangeable foregrounds, enabling very efficient and interpretable instance-level search. Furthermore, pattern-level search is feasible to retrieve more controllable, reasonable and diverse foregrounds. The proposed method outperforms the previous state-of-the-art by 10.42% in absolute difference and 24.06% in relative improvement evaluated by mean average precision (mAP). Extensive experimental results also demonstrate its efficacy from various aspects. The benchmark dataset and code will be release shortly.
Seq-SG2SL: Inferring Semantic Layout from Scene Graph Through Sequence to Sequence Learning
Aug 19, 2019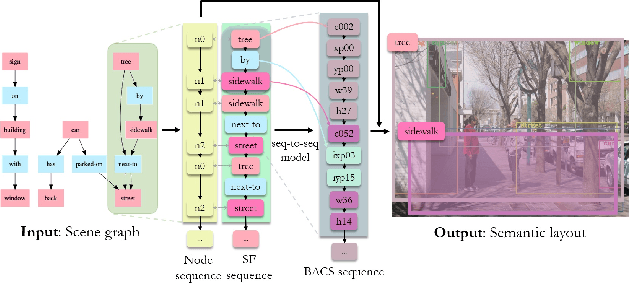

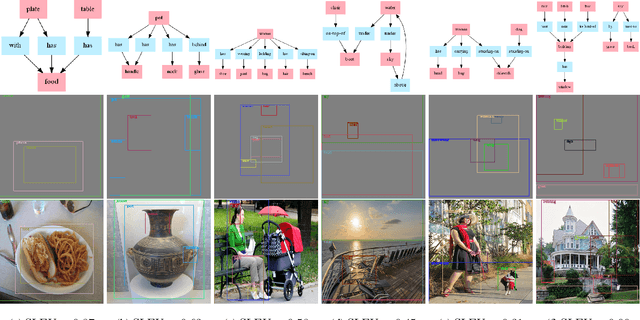
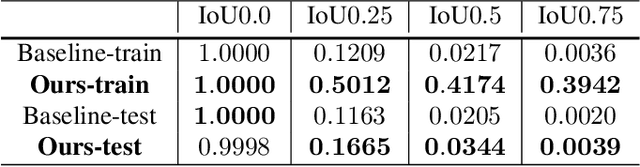
Generating semantic layout from scene graph is a crucial intermediate task connecting text to image. We present a conceptually simple, flexible and general framework using sequence to sequence (seq-to-seq) learning for this task. The framework, called Seq-SG2SL, derives sequence proxies for the two modality and a Transformer-based seq-to-seq model learns to transduce one into the other. A scene graph is decomposed into a sequence of semantic fragments (SF), one for each relationship. A semantic layout is represented as the consequence from a series of brick-action code segments (BACS), dictating the position and scale of each object bounding box in the layout. Viewing the two building blocks, SF and BACS, as corresponding terms in two different vocabularies, a seq-to-seq model is fittingly used to translate. A new metric, semantic layout evaluation understudy (SLEU), is devised to evaluate the task of semantic layout prediction inspired by BLEU. SLEU defines relationships within a layout as unigrams and looks at the spatial distribution for n-grams. Unlike the binary precision of BLEU, SLEU allows for some tolerances spatially through thresholding the Jaccard Index and is consequently more adapted to the task. Experimental results on the challenging Visual Genome dataset show improvement over a non-sequential approach based on graph convolution.