 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDFLoRA: Selective Decoupled Federated LoRA for Privacy-preserving Fine-tuning with Heterogeneous Clients
Jan 29, 2026Federated learning (FL) for large language models (LLMs) has attracted increasing attention as a privacy-preserving approach for adapting models over distributed data, where parameter-efficient methods such as Low-Rank Adaptation (LoRA) are widely adopted to reduce communication and memory costs. However, practical deployments often exhibit rank and data heterogeneity: clients operate under different low-rank budgets and data distributions, making direct aggregation of LoRA updates biased and unstable. Existing approaches either enforce a unified rank or align heterogeneous updates into a single shared subspace, which tends to mix transferable and client-specific directions and consequently undermines personalization. Moreover, under differential privacy (DP), perturbing such structurally mixed updates injects noise into directions that should remain purely local, leading to unnecessary utility degradation. To address these issues, we propose Selective Decoupled Federated LoRA (SDFLoRA), a structure-aware LoRA framework that decouples each client update into a shared component for aggregation and a private component that preserves client-specific semantics. Only the shared component participates in subspace alignment, while the private component remains local and uncommunicated, making the training DP-compatible and stabilizing aggregation under rank heterogeneity. By injecting noise only into the aggregated shareable update, this approach avoids perturbations to local directions and improves the utility-privacy trade-off. Experiments on multiple benchmarks demonstrate that SDFLoRA outperforms federated LoRA baselines and achieves a strong utility-privacy trade-off.
SDFLoRA: Selective Dual-Module LoRA for Federated Fine-tuning with Heterogeneous Clients
Jan 16, 2026Federated learning (FL) for large language models (LLMs) has attracted increasing attention as a way to enable privacy-preserving adaptation over distributed data. Parameter-efficient methods such as LoRA are widely adopted to reduce communication and memory costs. Despite these advances, practical FL deployments often exhibit rank heterogeneity, since different clients may use different low-rank configurations. This makes direct aggregation of LoRA updates biased and unstable. Existing solutions typically enforce unified ranks or align heterogeneous updates into a shared subspace, which over-constrains client-specific semantics, limits personalization, and provides weak protection of local client information under differential privacy noise. To address this issue, we propose Selective Dual-module Federated LoRA (SDFLoRA), which decomposes each client adapter into a global module that captures transferable knowledge and a local module that preserves client-specific adaptations. The global module is selectively aligned and aggregated across clients, while local modules remain private. This design enables robust learning under rank heterogeneity and supports privacy-aware optimization by injecting differential privacy noise exclusively into the global module. Experiments on GLUE benchmarks demonstrate that SDFLoRA outperforms representative federated LoRA baselines and achieves a better utility-privacy trade-off.
Toward a Team of AI-made Scientists for Scientific Discovery from Gene Expression Data
Feb 21, 2024



Machine learning has emerged as a powerful tool for scientific discovery, enabling researchers to extract meaningful insights from complex datasets. For instance, it has facilitated the identification of disease-predictive genes from gene expression data, significantly advancing healthcare. However, the traditional process for analyzing such datasets demands substantial human effort and expertise for the data selection, processing, and analysis. To address this challenge, we introduce a novel framework, a Team of AI-made Scientists (TAIS), designed to streamline the scientific discovery pipeline. TAIS comprises simulated roles, including a project manager, data engineer, and domain expert, each represented by a Large Language Model (LLM). These roles collaborate to replicate the tasks typically performed by data scientists, with a specific focus on identifying disease-predictive genes. Furthermore, we have curated a benchmark dataset to assess TAIS's effectiveness in gene identification, demonstrating our system's potential to significantly enhance the efficiency and scope of scientific exploration. Our findings represent a solid step towards automating scientific discovery through large language models.
Challenges and approaches for mitigating byzantine attacks in federated learning
Dec 29, 2021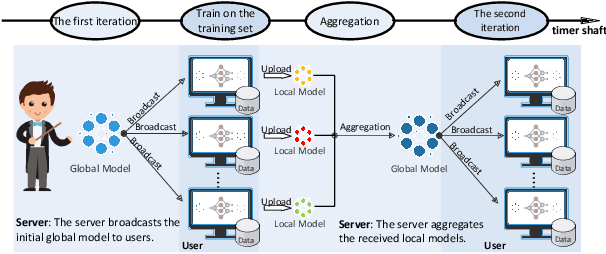
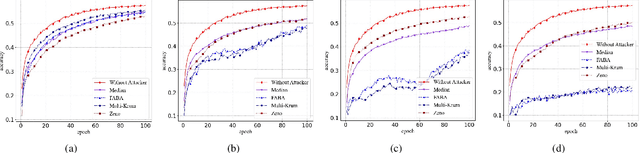
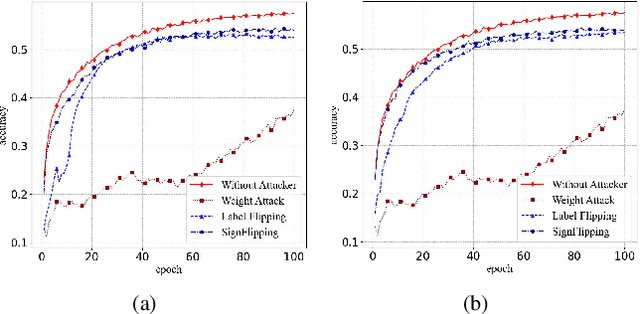
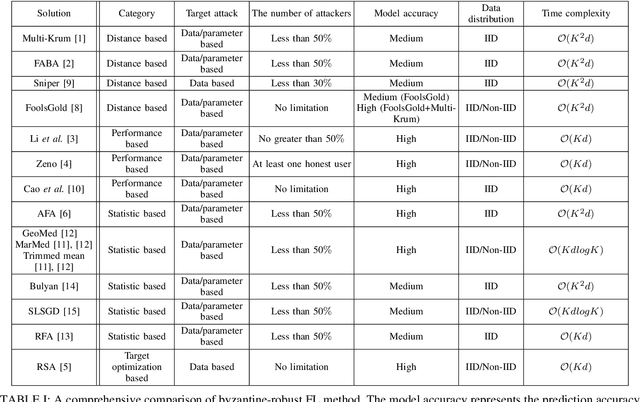
Recently emerged federated learning (FL) is an attractive distributed learning framework in which numerous wireless end-user devices can train a global model with the data remained autochthonous. Compared with the traditional machine learning framework that collects user data for centralized storage, which brings huge communication burden and concerns about data privacy, this approach can not only save the network bandwidth but also protect the data privacy. Despite the promising prospect, byzantine attack, an intractable threat in conventional distributed network, is discovered to be rather efficacious against FL as well. In this paper, we conduct a comprehensive investigation of the state-of-the-art strategies for defending against byzantine attacks in FL. We first provide a taxonomy for the existing defense solutions according to the techniques they used, followed by an across-the-board comparison and discussion. Then we propose a new byzantine attack method called weight attack to defeat those defense schemes, and conduct experiments to demonstrate its threat. The results show that existing defense solutions, although abundant, are still far from fully protecting FL. Finally, we indicate possible countermeasures for weight attack, and highlight several challenges and future research directions for mitigating byzantine attacks in FL.