 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenCompass: A Universal Evaluation Platform for Large Language Models
May 19, 2026In recent years, the field of artificial intelligence has undergone a paradigm shift from task-specific small-scale models to general-purpose large language models (LLMs). With the rapid iteration of LLMs, objective, quantitative, and comprehensive evaluation of their capabilities has become a critical link in advancing technological development. Currently, the mainstream static benchmark dataset-based evaluation methods face challenges such as the diversity of task types, inconsistent evaluation criteria, and fragmentation of data and processing workflows, making it difficult to efficiently conduct cross-domain and large-scale model evaluation. To address the aforementioned issues, this paper proposes and open-sources OpenCompass, a one-stop, scalable, and high-concurrency-supported general-purpose LLM evaluation platform. Adhering to the design philosophy of modularization and component decoupling, the platform boasts three core advantages: high compatibility, flexibility, and high concurrency. The core architecture of OpenCompass comprises five key components: the Configuration System, Task Partitioning Module, Execution and Scheduling Module, Task Execution Unit, and Result Visualization Module. Its workflow provides rule-based, LLM-as-a-Judge, and cascaded evaluators to adapt to the requirements of different task scenarios. Supporting mainstream benchmark datasets across multiple domains, including knowledge, reasoning, computation, science, language, code, etc., the platform offers a unified and efficient LLM evaluation tool for both academia and industry, facilitating the accurate identification of strengths and weaknesses of LLMs as well as their subsequent optimization.
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
May 13, 2026Recent progress in reasoning models has substantially advanced long-horizon mathematical and scientific problem solving, with several systems now reaching gold-medal-level performance on International Mathematical Olympiad (IMO) and International Physics Olympiad (IPhO) problems. In this paper, we introduce a simple and unified recipe for converting a post-trained reasoning backbone into a rigorous olympiad-level solver. The recipe first uses a reverse-perplexity curriculum for SFT to instill rigorous proof-search and self-checking behaviors, then scales these behaviors through a two-stage RL pipeline that progresses from RL with verifiable rewards to more delicate proof-level RL, and finally boosts solving performance with test-time scaling. Applying this recipe, we train a 30B-A3B backbone with SFT on around 340K sub-8K-token trajectories followed by 200 RL steps. The resulting model, SU-01, supports stable reasoning on difficult problems with trajectories exceeding 100K tokens, while achieving gold-medal-level performance on mathematical and physical olympiad competitions, including IMO 2025/USAMO 2026 and IPhO 2024/2025. It also demonstrates strong generalization of scientific reasoning to domains beyond mathematics and physics.
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Feb 10, 2026The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.
NoisyICL: A Little Noise in Model Parameters Calibrates In-context Learning
Feb 15, 2024



In-Context Learning (ICL) is suffering from unsatisfactory performance and under-calibration due to high prior bias and unfaithful confidence. Some previous works fine-tuned language models for better ICL performance with enormous datasets and computing costs. In this paper, we propose NoisyICL, simply perturbing the model parameters by random noises to strive for better performance and calibration. Our experiments on two models and 12 downstream datasets show that NoisyICL can help ICL produce more accurate predictions. Our further analysis indicates that NoisyICL enables the model to provide more fair predictions, and also with more faithful confidence. Therefore, we believe that NoisyICL is an effective calibration of ICL. Our experimental code is uploaded to Github.
SkIn: Skimming-Intensive Long-Text Classification Using BERT for Medical Corpus
Sep 24, 2022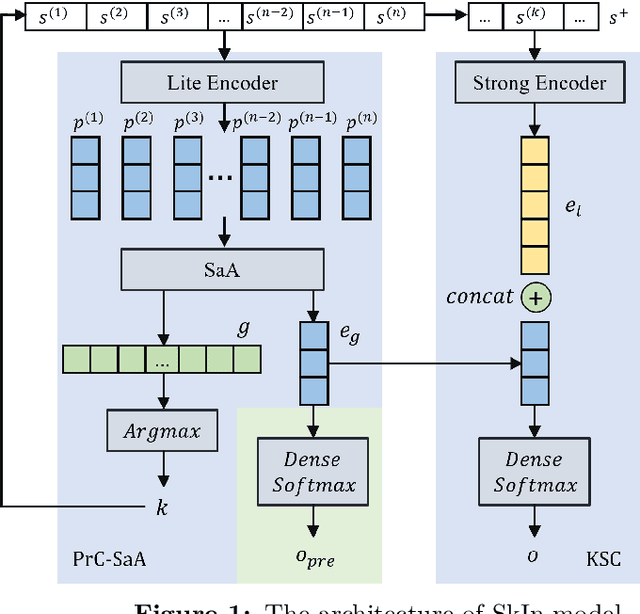
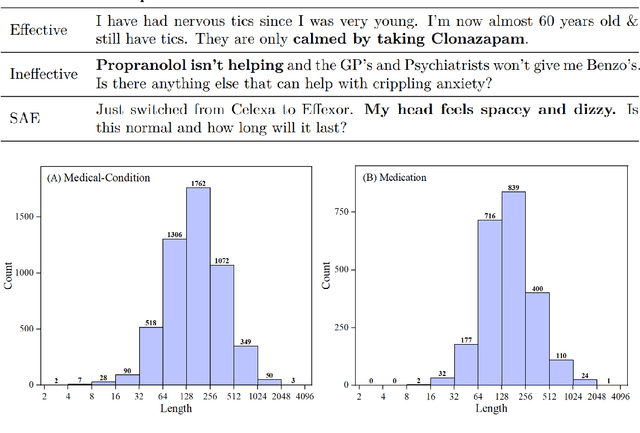
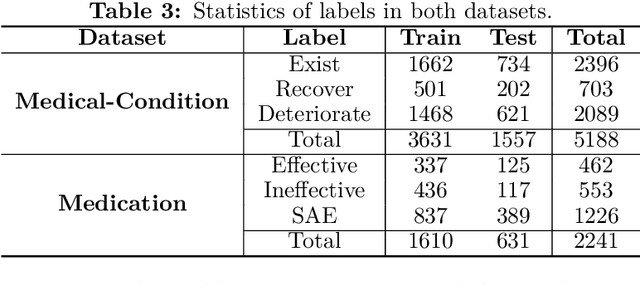
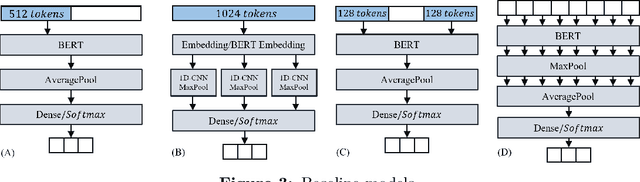
BERT is a widely used pre-trained model in natural language processing. However, since BERT is quadratic to the text length, the BERT model is difficult to be used directly on the long-text corpus. In some fields, the collected text data may be quite long, such as in the health care field. Therefore, to apply the pre-trained language knowledge of BERT to long text, in this paper, imitating the skimming-intensive reading method used by humans when reading a long paragraph, the Skimming-Intensive Model (SkIn) is proposed. It can dynamically select the critical information in the text so that the sentence input into the BERT-Base model is significantly shortened, which can effectively save the cost of the classification algorithm. Experiments show that the SkIn method has achieved superior accuracy than the baselines on long-text classification datasets in the medical field, while its time and space requirements increase linearly with the text length, alleviating the time and space overflow problem of basic BERT on long-text data.