 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSG-Stump: A Learning Friendly CSG-Like Representation for Interpretable Shape Parsing
Aug 25, 2021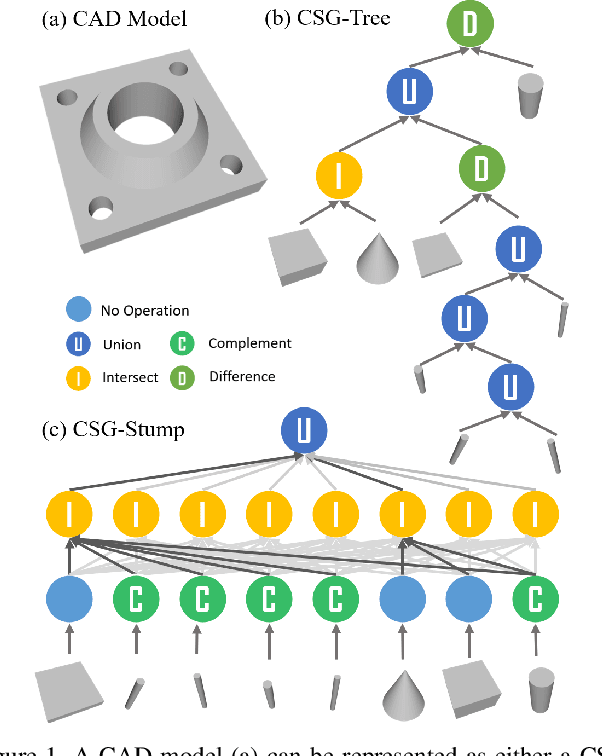

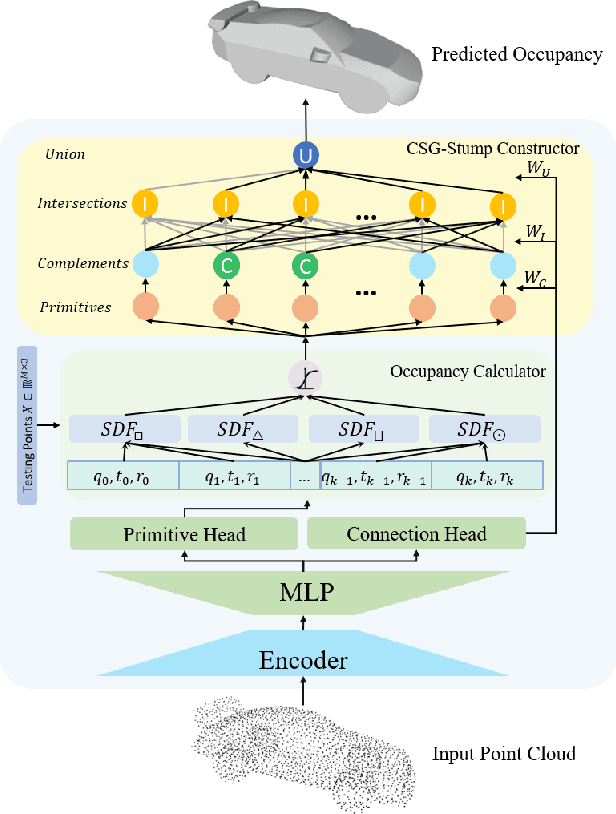
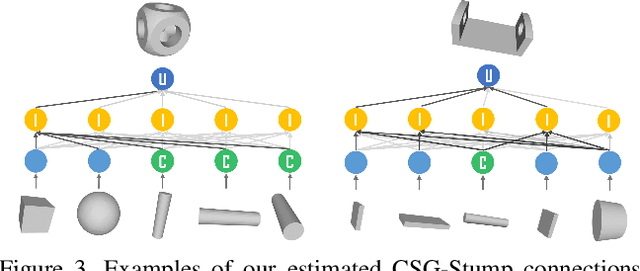
Generating an interpretable and compact representation of 3D shapes from point clouds is an important and challenging problem. This paper presents CSG-Stump Net, an unsupervised end-to-end network for learning shapes from point clouds and discovering the underlying constituent modeling primitives and operations as well. At the core is a three-level structure called {\em CSG-Stump}, consisting of a complement layer at the bottom, an intersection layer in the middle, and a union layer at the top. CSG-Stump is proven to be equivalent to CSG in terms of representation, therefore inheriting the interpretable, compact and editable nature of CSG while freeing from CSG's complex tree structures. Particularly, the CSG-Stump has a simple and regular structure, allowing neural networks to give outputs of a constant dimensionality, which makes itself deep-learning friendly. Due to these characteristics of CSG-Stump, CSG-Stump Net achieves superior results compared to previous CSG-based methods and generates much more appealing shapes, as confirmed by extensive experiments. Project page: https://kimren227.github.io/projects/CSGStump/
Unsupervised Domain Adaptive 3D Detection with Multi-Level Consistency
Aug 18, 2021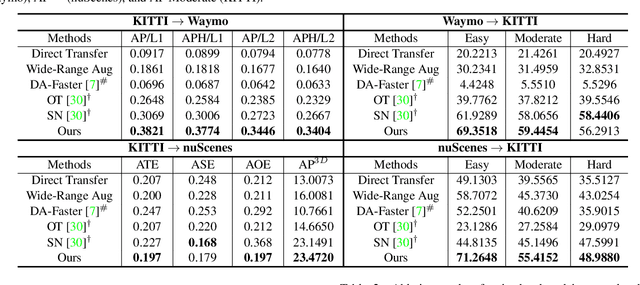
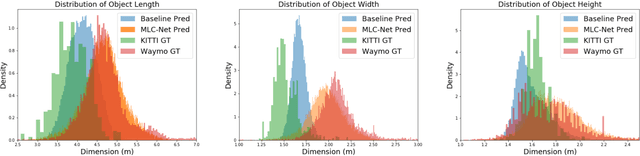
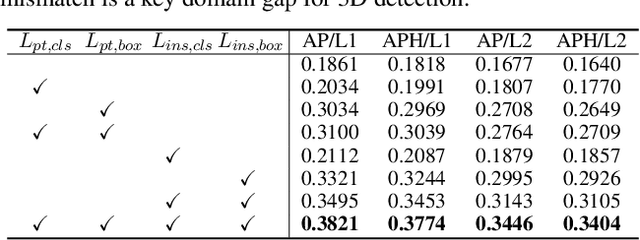
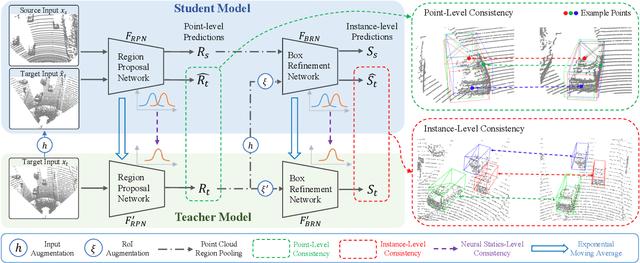
Deep learning-based 3D object detection has achieved unprecedented success with the advent of large-scale autonomous driving datasets. However, drastic performance degradation remains a critical challenge for cross-domain deployment. In addition, existing 3D domain adaptive detection methods often assume prior access to the target domain annotations, which is rarely feasible in the real world. To address this challenge, we study a more realistic setting, unsupervised 3D domain adaptive detection, which only utilizes source domain annotations. 1) We first comprehensively investigate the major underlying factors of the domain gap in 3D detection. Our key insight is that geometric mismatch is the key factor of domain shift. 2) Then, we propose a novel and unified framework, Multi-Level Consistency Network (MLC-Net), which employs a teacher-student paradigm to generate adaptive and reliable pseudo-targets. MLC-Net exploits point-, instance- and neural statistics-level consistency to facilitate cross-domain transfer. Extensive experiments demonstrate that MLC-Net outperforms existing state-of-the-art methods (including those using additional target domain information) on standard benchmarks. Notably, our approach is detector-agnostic, which achieves consistent gains on both single- and two-stage 3D detectors.
Delving Deep into the Generalization of Vision Transformers under Distribution Shifts
Jun 18, 2021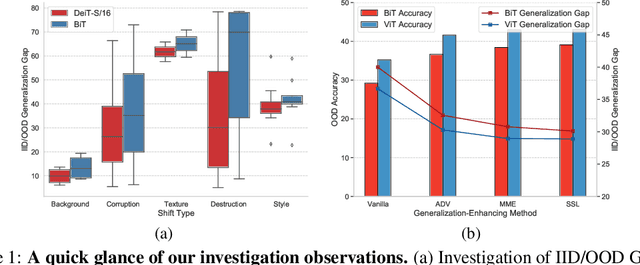
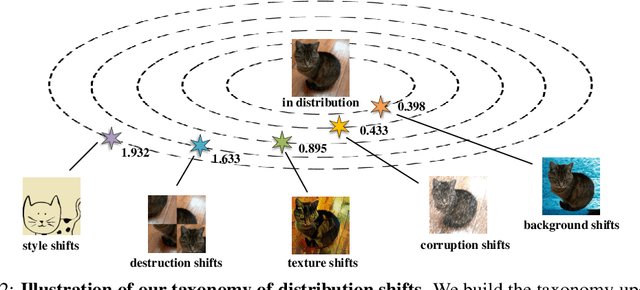

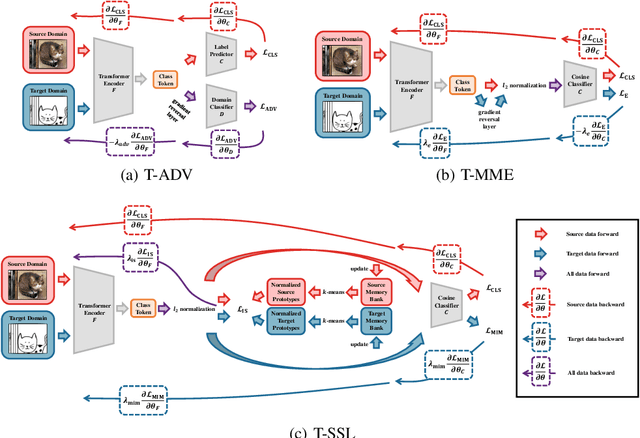
Recently, Vision Transformers (ViTs) have achieved impressive results on various vision tasks. Yet, their generalization ability under different distribution shifts is rarely understood. In this work, we provide a comprehensive study on the out-of-distribution generalization of ViTs. To support a systematic investigation, we first present a taxonomy of distribution shifts by categorizing them into five conceptual groups: corruption shift, background shift, texture shift, destruction shift, and style shift. Then we perform extensive evaluations of ViT variants under different groups of distribution shifts and compare their generalization ability with CNNs. Several important observations are obtained: 1) ViTs generalize better than CNNs under multiple distribution shifts. With the same or fewer parameters, ViTs are ahead of corresponding CNNs by more than 5% in top-1 accuracy under most distribution shifts. 2) Larger ViTs gradually narrow the in-distribution and out-of-distribution performance gap. To further improve the generalization of ViTs, we design the Generalization-Enhanced ViTs by integrating adversarial learning, information theory, and self-supervised learning. By investigating three types of generalization-enhanced ViTs, we observe their gradient-sensitivity and design a smoother learning strategy to achieve a stable training process. With modified training schemes, we achieve improvements on performance towards out-of-distribution data by 4% from vanilla ViTs. We comprehensively compare three generalization-enhanced ViTs with their corresponding CNNs, and observe that: 1) For the enhanced model, larger ViTs still benefit more for the out-of-distribution generalization. 2) generalization-enhanced ViTs are more sensitive to the hyper-parameters than corresponding CNNs. We hope our comprehensive study could shed light on the design of more generalizable learning architectures.
Unsupervised 3D Shape Completion through GAN Inversion
Apr 29, 2021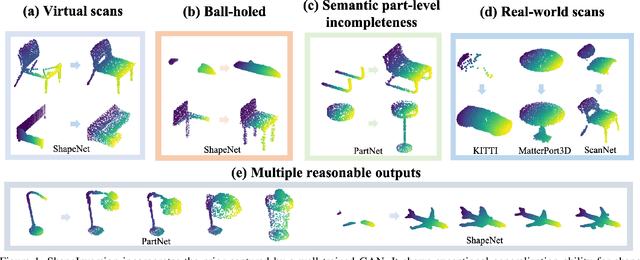
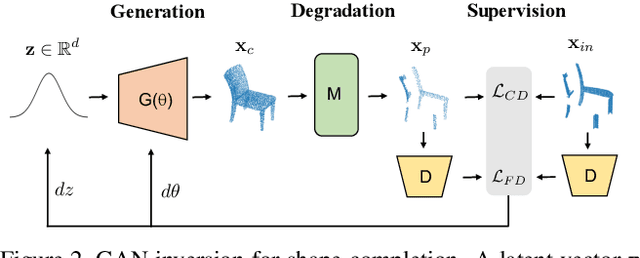

Most 3D shape completion approaches rely heavily on partial-complete shape pairs and learn in a fully supervised manner. Despite their impressive performances on in-domain data, when generalizing to partial shapes in other forms or real-world partial scans, they often obtain unsatisfactory results due to domain gaps. In contrast to previous fully supervised approaches, in this paper we present ShapeInversion, which introduces Generative Adversarial Network (GAN) inversion to shape completion for the first time. ShapeInversion uses a GAN pre-trained on complete shapes by searching for a latent code that gives a complete shape that best reconstructs the given partial input. In this way, ShapeInversion no longer needs paired training data, and is capable of incorporating the rich prior captured in a well-trained generative model. On the ShapeNet benchmark, the proposed ShapeInversion outperforms the SOTA unsupervised method, and is comparable with supervised methods that are learned using paired data. It also demonstrates remarkable generalization ability, giving robust results for real-world scans and partial inputs of various forms and incompleteness levels. Importantly, ShapeInversion naturally enables a series of additional abilities thanks to the involvement of a pre-trained GAN, such as producing multiple valid complete shapes for an ambiguous partial input, as well as shape manipulation and interpolation.
Variational Relational Point Completion Network
Apr 20, 2021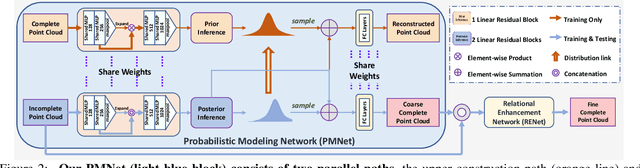
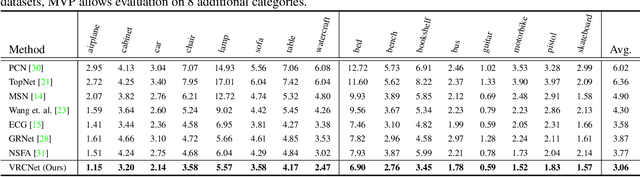
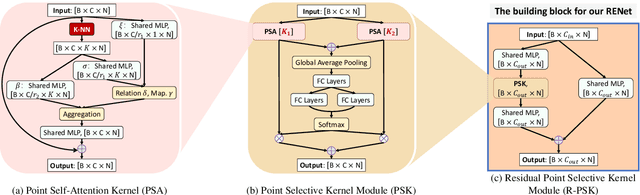
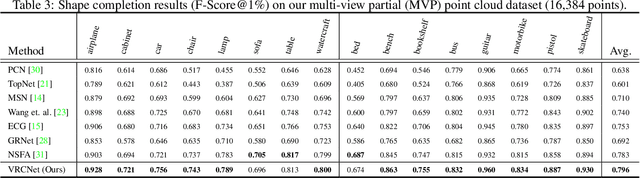
Real-scanned point clouds are often incomplete due to viewpoint, occlusion, and noise. Existing point cloud completion methods tend to generate global shape skeletons and hence lack fine local details. Furthermore, they mostly learn a deterministic partial-to-complete mapping, but overlook structural relations in man-made objects. To tackle these challenges, this paper proposes a variational framework, Variational Relational point Completion network (VRCNet) with two appealing properties: 1) Probabilistic Modeling. In particular, we propose a dual-path architecture to enable principled probabilistic modeling across partial and complete clouds. One path consumes complete point clouds for reconstruction by learning a point VAE. The other path generates complete shapes for partial point clouds, whose embedded distribution is guided by distribution obtained from the reconstruction path during training. 2) Relational Enhancement. Specifically, we carefully design point self-attention kernel and point selective kernel module to exploit relational point features, which refines local shape details conditioned on the coarse completion. In addition, we contribute a multi-view partial point cloud dataset (MVP dataset) containing over 100,000 high-quality scans, which renders partial 3D shapes from 26 uniformly distributed camera poses for each 3D CAD model. Extensive experiments demonstrate that VRCNet outperforms state-of-theart methods on all standard point cloud completion benchmarks. Notably, VRCNet shows great generalizability and robustness on real-world point cloud scans.
HAVANA: Hierarchical and Variation-Normalized Autoencoder for Person Re-identification
Jan 09, 2021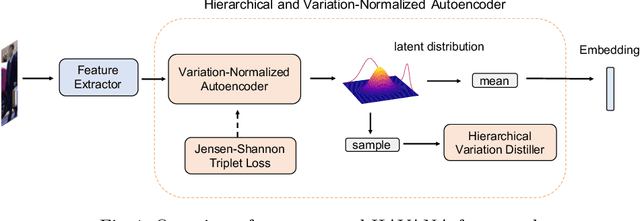

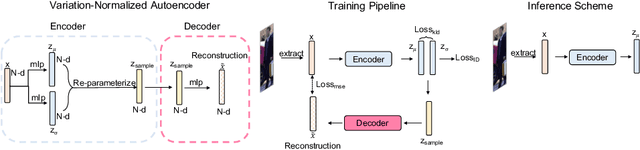
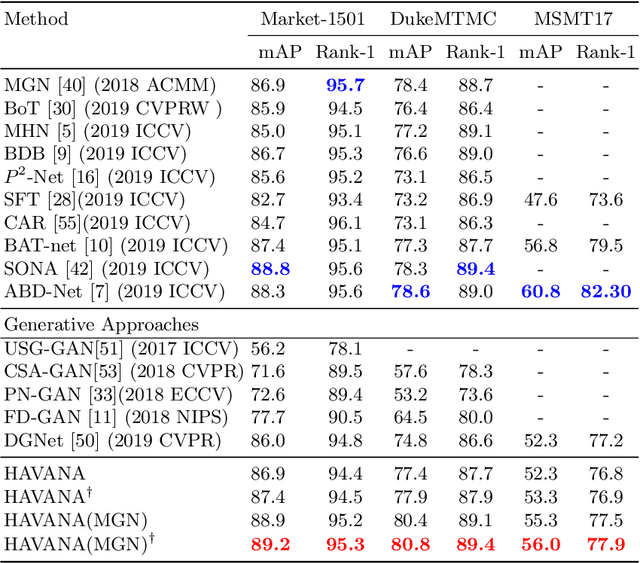
Person Re-Identification (Re-ID) is of great importance to the many video surveillance systems. Learning discriminative features for Re-ID remains a challenge due to the large variations in the image space, e.g., continuously changing human poses, illuminations and point of views. In this paper, we propose HAVANA, a novel extensible, light-weight HierArchical and VAriation-Normalized Autoencoder that learns features robust to intra-class variations. In contrast to existing generative approaches that prune the variations with heavy extra supervised signals, HAVANA suppresses the intra-class variations with a Variation-Normalized Autoencoder trained with no additional supervision. We also introduce a novel Jensen-Shannon triplet loss for contrastive distribution learning in Re-ID. In addition, we present Hierarchical Variation Distiller, a hierarchical VAE to factorize the latent representation and explicitly model the variations. To the best of our knowledge, HAVANA is the first VAE-based framework for person ReID.
Towards Overcoming False Positives in Visual Relationship Detection
Dec 24, 2020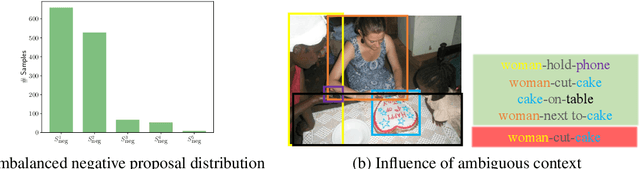
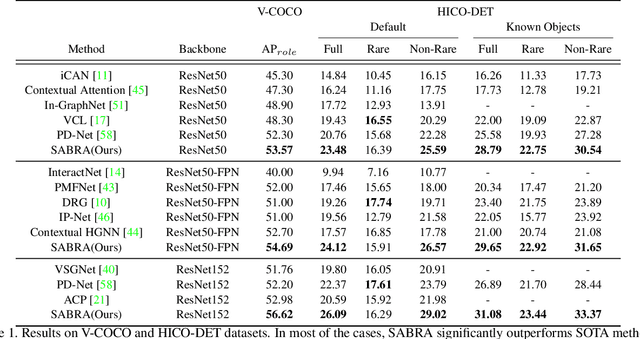
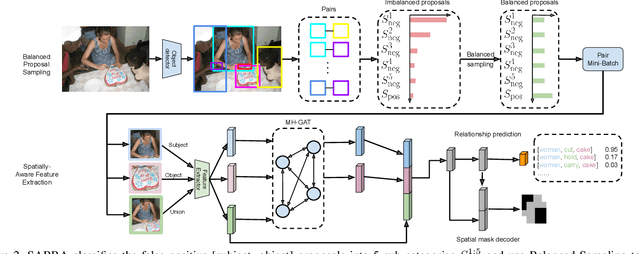
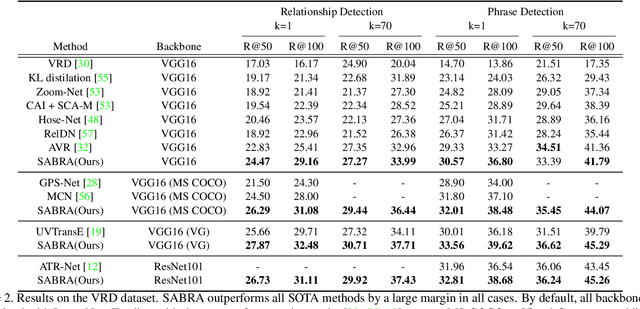
In this paper, we investigate the cause of the high false positive rate in Visual Relationship Detection (VRD). We observe that during training, the relationship proposal distribution is highly imbalanced: most of the negative relationship proposals are easy to identify, e.g., the inaccurate object detection, which leads to the under-fitting of low-frequency difficult proposals. This paper presents Spatially-Aware Balanced negative pRoposal sAmpling (SABRA), a robust VRD framework that alleviates the influence of false positives. To effectively optimize the model under imbalanced distribution, SABRA adopts Balanced Negative Proposal Sampling (BNPS) strategy for mini-batch sampling. BNPS divides proposals into 5 well defined sub-classes and generates a balanced training distribution according to the inverse frequency. BNPS gives an easier optimization landscape and significantly reduces the number of false positives. To further resolve the low-frequency challenging false positive proposals with high spatial ambiguity, we improve the spatial modeling ability of SABRA on two aspects: a simple and efficient multi-head heterogeneous graph attention network (MH-GAT) that models the global spatial interactions of objects, and a spatial mask decoder that learns the local spatial configuration. SABRA outperforms SOTA methods by a large margin on two human-object interaction (HOI) datasets and one general VRD dataset.
BiPointNet: Binary Neural Network for Point Clouds
Oct 12, 2020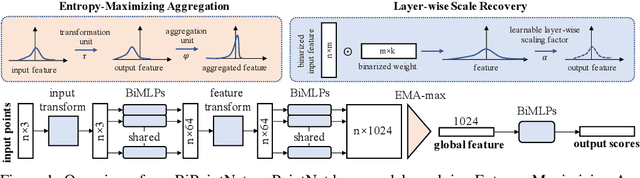

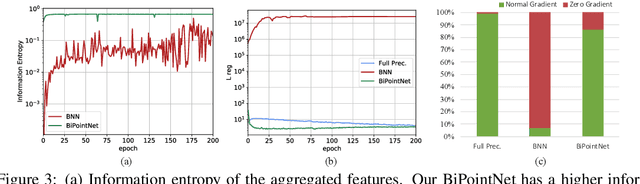
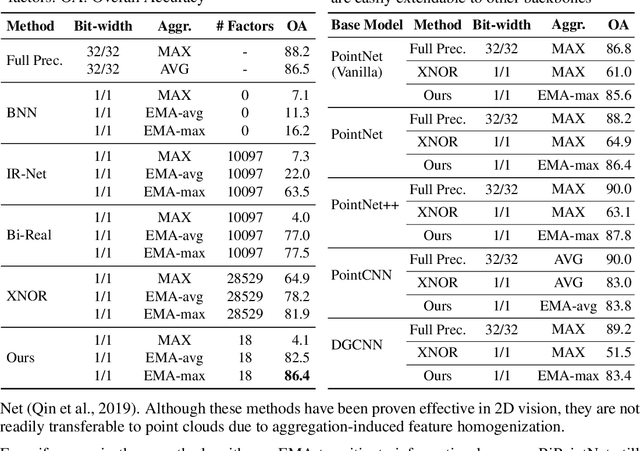
To alleviate the resource constraint for real-time point clouds applications that run on edge devices, we present BiPointNet, the first model binarization approach for efficient deep learning on point clouds. In this work, we discover that the immense performance drop of binarized models for point clouds is caused by two main challenges: aggregation-induced feature homogenization that leads to a degradation of information entropy, and scale distortion that hinders optimization and invalidates scale-sensitive structures. With theoretical justifications and in-depth analysis, we propose Entropy-Maximizing Aggregation(EMA) to modulate the distribution before aggregation for the maximum information entropy, andLayer-wise Scale Recovery(LSR) to efficiently restore feature scales. Extensive experiments show that our BiPointNet outperforms existing binarization methods by convincing margins, at the level even comparable with the full precision counterpart. We highlight that our techniques are generic which show significant improvements on various fundamental tasks and mainstream backbones. BiPoint-Net gives an impressive 14.7 times speedup and 18.9 times storage saving on real-world resource-constrained devices.
Balanced Activation for Long-tailed Visual Recognition
Aug 24, 2020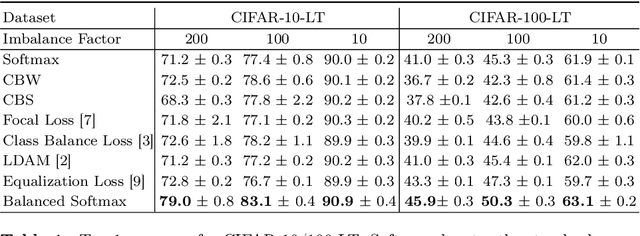
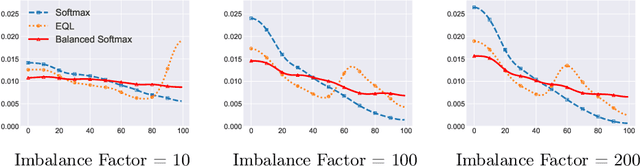
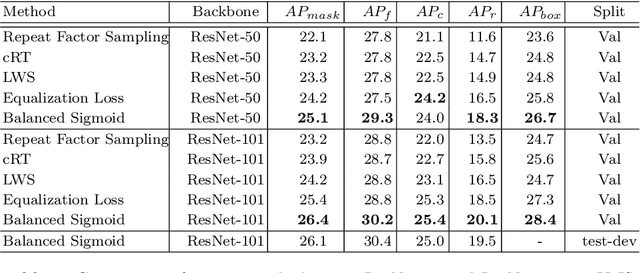
Deep classifiers have achieved great success in visual recognition. However, real-world data is long-tailed by nature, leading to the mismatch between training and testing distributions. In this report, we introduce Balanced Activation (Balanced Softmax and Balanced Sigmoid), an elegant unbiased, and simple extension of Sigmoid and Softmax activation function, to accommodate the label distribution shift between training and testing in object detection. We derive the generalization bound for multiclass Softmax regression and show our loss minimizes the bound. In our experiments, we demonstrate that Balanced Activation generally provides ~3% gain in terms of mAP on LVIS-1.0 and outperforms the current state-of-the-art methods without introducing any extra parameters.
Leveraging Localization for Multi-camera Association
Aug 07, 2020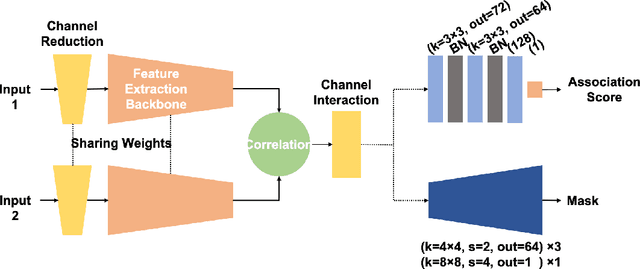
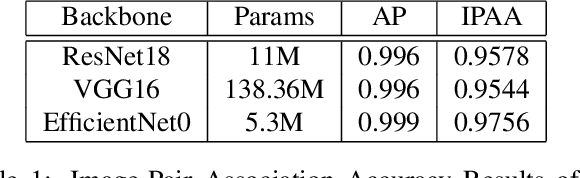
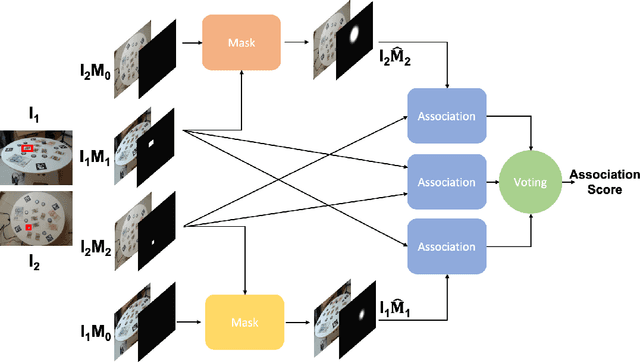
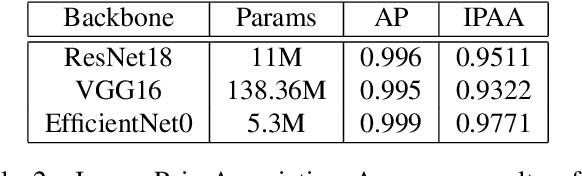
We present McAssoc, a deep learning approach to the as-sociation of detection bounding boxes in different views ofa multi-camera system. The vast majority of the academiahas been developing single-camera computer vision algo-rithms, however, little research attention has been directedto incorporating them into a multi-camera system. In thispaper, we designed a 3-branch architecture that leveragesdirect association and additional cross localization infor-mation. A new metric, image-pair association accuracy(IPAA) is designed specifically for performance evaluationof cross-camera detection association. We show in the ex-periments that localization information is critical to suc-cessful cross-camera association, especially when similar-looking objects are present. This paper is an experimentalwork prior to MessyTable, which is a large-scale bench-mark for instance association in mutliple cameras.