 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Quantized Tokenization Framework for Task-Adaptive Graph Representation Learning
Oct 14, 2025Recent progress in language and vision foundation models demonstrates the importance of discrete token interfaces that transform complex inputs into compact sequences for large-scale modeling. Extending this paradigm to graphs requires a tokenization scheme that handles non-Euclidean structures and multi-scale dependencies efficiently. Existing approaches to graph tokenization, linearized, continuous, and quantized, remain limited in adaptability and efficiency. In particular, most current quantization-based tokenizers organize hierarchical information in fixed or task-agnostic ways, which may either over-represent or under-utilize structural cues, and lack the ability to dynamically reweight contributions from different levels without retraining the encoder. This work presents a hierarchical quantization framework that introduces a self-weighted mechanism for task-adaptive aggregation across multiple scales. The proposed method maintains a frozen encoder while modulating information flow through a lightweight gating process, enabling parameter-efficient adaptation to diverse downstream tasks. Experiments on benchmark datasets for node classification and link prediction demonstrate consistent improvements over strong baselines under comparable computational budgets.
Uncertainty-Aware Semantic Decoding for LLM-Based Sequential Recommendation
Aug 10, 2025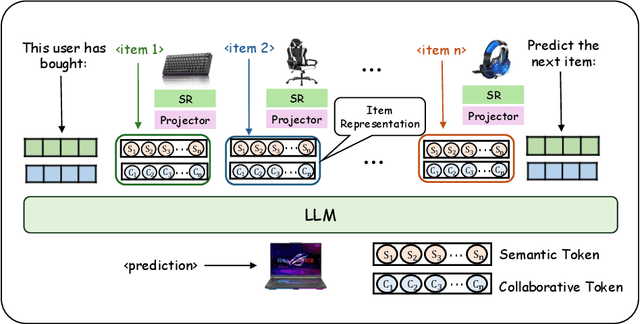
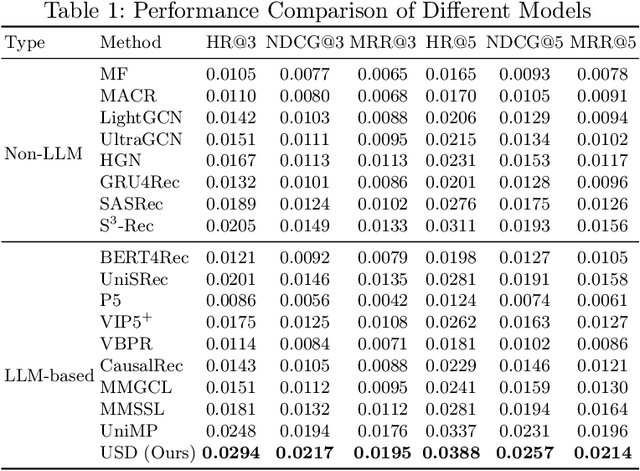
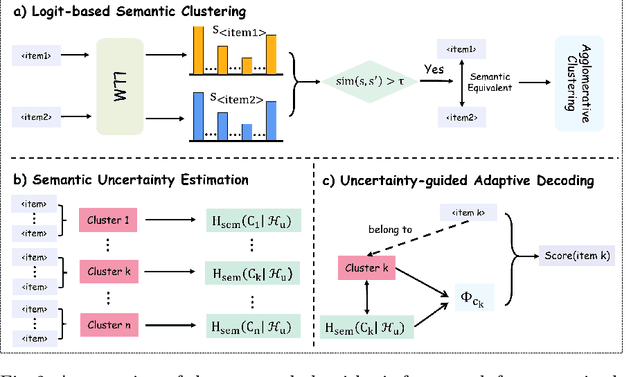

Large language models have been widely applied to sequential recommendation tasks, yet during inference, they continue to rely on decoding strategies developed for natural language processing. This creates a mismatch between text-generation objectives and recommendation next item selection objectives. This paper addresses this limitation by proposing an Uncertainty-aware Semantic Decoding (USD) framework that combines logit-based clustering with adaptive scoring to improve next-item predictions. Our approach clusters items with similar logit vectors into semantic equivalence groups, then redistributes probability mass within these clusters and computes entropy across them to control item scoring and sampling temperature during recommendation inference. Experiments on Amazon Product datasets (six domains) gains of 18.5\% in HR@3, 11.9\% in NDCG@3, and 10.8\% in MRR@3 compared to state-of-the-art baselines. Hyperparameter analysis confirms the optimal parameters among various settings, and experiments on H\&M, and Netflix datasets indicate that the framework can adapt to differing recommendation domains. The experimental results confirm that integrating semantic clustering and uncertainty assessment yields more reliable and accurate recommendations.
Exploiting Epistemic Uncertainty in Cold-Start Recommendation Systems
Feb 22, 2025


The cold-start problem remains a significant challenge in recommendation systems based on generative models. Current methods primarily focus on enriching embeddings or inputs by gathering more data, often overlooking the effectiveness of how existing training knowledge is utilized. This inefficiency can lead to missed opportunities for improving cold-start recommendations. To address this, we propose the use of epistemic uncertainty, which reflects a lack of certainty about the optimal model, as a tool to measure and enhance the efficiency with which a recommendation system leverages available knowledge. By considering epistemic uncertainty as a reducible component of overall uncertainty, we introduce a new approach to refine model performance. The effectiveness of this approach is validated through extensive offline experiments on publicly available datasets, demonstrating its superior performance and robustness in tackling the cold-start problem.