 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Token Initialization for New Vocabulary in LMs for Generative Recommendation
Apr 02, 2026Language models (LMs) are increasingly extended with new learnable vocabulary tokens for domain-specific tasks, such as Semantic-ID tokens in generative recommendation. The standard practice initializes these new tokens as the mean of existing vocabulary embeddings, then relies on supervised fine-tuning to learn their representations. We present a systematic analysis of this strategy: through spectral and geometric diagnostics, we show that mean initialization collapses all new tokens into a degenerate subspace, erasing inter-token distinctions that subsequent fine-tuning struggles to fully recover. These findings suggest that \emph{token initialization} is a key bottleneck when extending LMs with new vocabularies. Motivated by this diagnosis, we propose the \emph{Grounded Token Initialization Hypothesis}: linguistically grounding novel tokens in the pretrained embedding space before fine-tuning better enables the model to leverage its general-purpose knowledge for novel-token domains. We operationalize this hypothesis as GTI (Grounded Token Initialization), a lightweight grounding stage that, prior to fine-tuning, maps new tokens to distinct, semantically meaningful locations in the pretrained embedding space using only paired linguistic supervision. Despite its simplicity, GTI outperforms both mean initialization and existing auxiliary-task adaptation methods in the majority of evaluation settings across multiple generative recommendation benchmarks, including industry-scale and public datasets. Further analyses show that grounded embeddings produce richer inter-token structure that persists through fine-tuning, corroborating the hypothesis that initialization quality is a key bottleneck in vocabulary extension.
Semantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
User-Level Membership Inference Attack against Metric Embedding Learning
Mar 04, 2022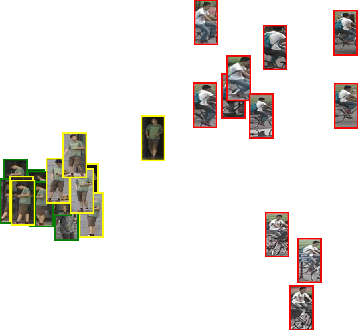

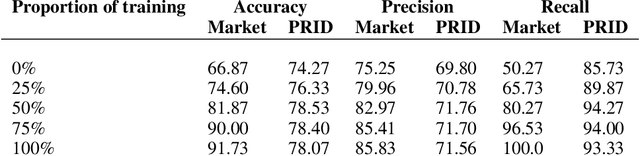
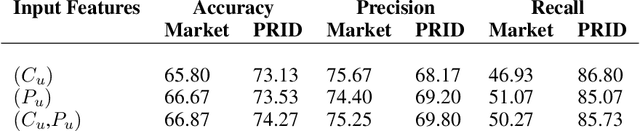
Membership inference (MI) determines if a sample was part of a victim model training set. Recent development of MI attacks focus on record-level membership inference which limits their application in many real-world scenarios. For example, in the person re-identification task, the attacker (or investigator) is interested in determining if a user's images have been used during training or not. However, the exact training images might not be accessible to the attacker. In this paper, we develop a user-level MI attack where the goal is to find if any sample from the target user has been used during training even when no exact training sample is available to the attacker. We focus on metric embedding learning due to its dominance in person re-identification, where user-level MI attack is more sensible. We conduct an extensive evaluation on several datasets and show that our approach achieves high accuracy on user-level MI task.