 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleBoost: A Systematic Alignment Framework for High-Fidelity, Controllable, and Robust Video Generation
Feb 07, 2026Post-training is the decisive step for converting a pretrained video generator into a production-oriented model that is instruction-following, controllable, and robust over long temporal horizons. This report presents a systematical post-training framework that organizes supervised policy shaping, reward-driven reinforcement learning, and preference-based refinement into a single stability-constrained optimization stack. The framework is designed around practical video-generation constraints, including high rollout cost, temporally compounding failure modes, and feedback that is heterogeneous, uncertain, and often weakly discriminative. By treating optimization as a staged, diagnostic-driven process rather than a collection of isolated tricks, the report summarizes a cohesive recipe for improving perceptual fidelity, temporal coherence, and prompt adherence while preserving the controllability established at initialization. The resulting framework provides a clear blueprint for building scalable post-training pipelines that remain stable, extensible, and effective in real-world deployment settings.
Point2Insert: Video Object Insertion via Sparse Point Guidance
Feb 04, 2026This paper introduces Point2Insert, a sparse-point-based framework for flexible and user-friendly object insertion in videos, motivated by the growing popularity of accurate, low-effort object placement. Existing approaches face two major challenges: mask-based insertion methods require labor-intensive mask annotations, while instruction-based methods struggle to place objects at precise locations. Point2Insert addresses these issues by requiring only a small number of sparse points instead of dense masks, eliminating the need for tedious mask drawing. Specifically, it supports both positive and negative points to indicate regions that are suitable or unsuitable for insertion, enabling fine-grained spatial control over object locations. The training of Point2Insert consists of two stages. In Stage 1, we train an insertion model that generates objects in given regions conditioned on either sparse-point prompts or a binary mask. In Stage 2, we further train the model on paired videos synthesized by an object removal model, adapting it to video insertion. Moreover, motivated by the higher insertion success rate of mask-guided editing, we leverage a mask-guided insertion model as a teacher to distill reliable insertion behavior into the point-guided model. Extensive experiments demonstrate that Point2Insert consistently outperforms strong baselines and even surpasses models with $\times$10 more parameters.
FSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
TeleStyle: Content-Preserving Style Transfer in Images and Videos
Jan 28, 2026Content-preserving style transfer, generating stylized outputs based on content and style references, remains a significant challenge for Diffusion Transformers (DiTs) due to the inherent entanglement of content and style features in their internal representations. In this technical report, we present TeleStyle, a lightweight yet effective model for both image and video stylization. Built upon Qwen-Image-Edit, TeleStyle leverages the base model's robust capabilities in content preservation and style customization. To facilitate effective training, we curated a high-quality dataset of distinct specific styles and further synthesized triplets using thousands of diverse, in-the-wild style categories. We introduce a Curriculum Continual Learning framework to train TeleStyle on this hybrid dataset of clean (curated) and noisy (synthetic) triplets. This approach enables the model to generalize to unseen styles without compromising precise content fidelity. Additionally, we introduce a video-to-video stylization module to enhance temporal consistency and visual quality. TeleStyle achieves state-of-the-art performance across three core evaluation metrics: style similarity, content consistency, and aesthetic quality. Code and pre-trained models are available at https://github.com/Tele-AI/TeleStyle
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
TempoMaster: Efficient Long Video Generation via Next-Frame-Rate Prediction
Nov 16, 2025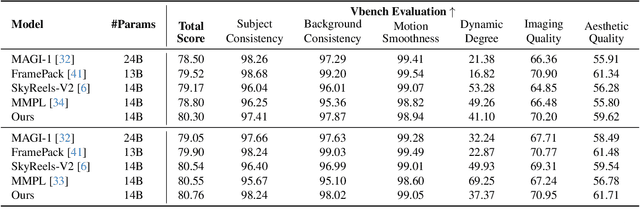
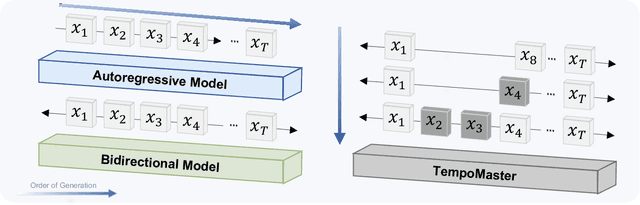
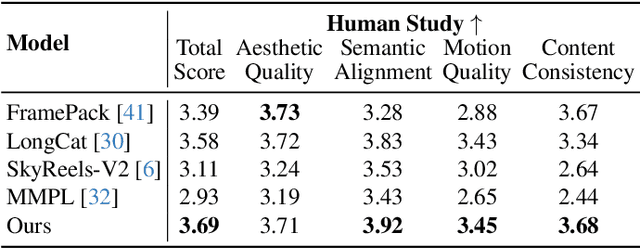
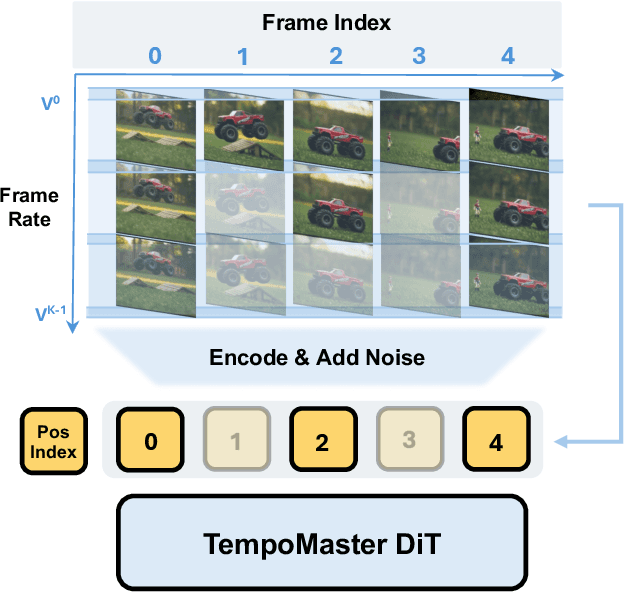
We present TempoMaster, a novel framework that formulates long video generation as next-frame-rate prediction. Specifically, we first generate a low-frame-rate clip that serves as a coarse blueprint of the entire video sequence, and then progressively increase the frame rate to refine visual details and motion continuity. During generation, TempoMaster employs bidirectional attention within each frame-rate level while performing autoregression across frame rates, thus achieving long-range temporal coherence while enabling efficient and parallel synthesis. Extensive experiments demonstrate that TempoMaster establishes a new state-of-the-art in long video generation, excelling in both visual and temporal quality.
Blind-Spot Guided Diffusion for Self-supervised Real-World Denoising
Sep 19, 2025In this work, we present Blind-Spot Guided Diffusion, a novel self-supervised framework for real-world image denoising. Our approach addresses two major challenges: the limitations of blind-spot networks (BSNs), which often sacrifice local detail and introduce pixel discontinuities due to spatial independence assumptions, and the difficulty of adapting diffusion models to self-supervised denoising. We propose a dual-branch diffusion framework that combines a BSN-based diffusion branch, generating semi-clean images, with a conventional diffusion branch that captures underlying noise distributions. To enable effective training without paired data, we use the BSN-based branch to guide the sampling process, capturing noise structure while preserving local details. Extensive experiments on the SIDD and DND datasets demonstrate state-of-the-art performance, establishing our method as a highly effective self-supervised solution for real-world denoising. Code and pre-trained models are released at: https://github.com/Sumching/BSGD.
MAGREF: Masked Guidance for Any-Reference Video Generation
May 29, 2025Video generation has made substantial strides with the emergence of deep generative models, especially diffusion-based approaches. However, video generation based on multiple reference subjects still faces significant challenges in maintaining multi-subject consistency and ensuring high generation quality. In this paper, we propose MAGREF, a unified framework for any-reference video generation that introduces masked guidance to enable coherent multi-subject video synthesis conditioned on diverse reference images and a textual prompt. Specifically, we propose (1) a region-aware dynamic masking mechanism that enables a single model to flexibly handle various subject inference, including humans, objects, and backgrounds, without architectural changes, and (2) a pixel-wise channel concatenation mechanism that operates on the channel dimension to better preserve appearance features. Our model delivers state-of-the-art video generation quality, generalizing from single-subject training to complex multi-subject scenarios with coherent synthesis and precise control over individual subjects, outperforming existing open-source and commercial baselines. To facilitate evaluation, we also introduce a comprehensive multi-subject video benchmark. Extensive experiments demonstrate the effectiveness of our approach, paving the way for scalable, controllable, and high-fidelity multi-subject video synthesis. Code and model can be found at: https://github.com/MAGREF-Video/MAGREF
ATI: Any Trajectory Instruction for Controllable Video Generation
May 28, 2025We propose a unified framework for motion control in video generation that seamlessly integrates camera movement, object-level translation, and fine-grained local motion using trajectory-based inputs. In contrast to prior methods that address these motion types through separate modules or task-specific designs, our approach offers a cohesive solution by projecting user-defined trajectories into the latent space of pre-trained image-to-video generation models via a lightweight motion injector. Users can specify keypoints and their motion paths to control localized deformations, entire object motion, virtual camera dynamics, or combinations of these. The injected trajectory signals guide the generative process to produce temporally consistent and semantically aligned motion sequences. Our framework demonstrates superior performance across multiple video motion control tasks, including stylized motion effects (e.g., motion brushes), dynamic viewpoint changes, and precise local motion manipulation. Experiments show that our method provides significantly better controllability and visual quality compared to prior approaches and commercial solutions, while remaining broadly compatible with various state-of-the-art video generation backbones. Project page: https://anytraj.github.io/.
CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance
Mar 13, 2025Video generation has witnessed remarkable progress with the advent of deep generative models, particularly diffusion models. While existing methods excel in generating high-quality videos from text prompts or single images, personalized multi-subject video generation remains a largely unexplored challenge. This task involves synthesizing videos that incorporate multiple distinct subjects, each defined by separate reference images, while ensuring temporal and spatial consistency. Current approaches primarily rely on mapping subject images to keywords in text prompts, which introduces ambiguity and limits their ability to model subject relationships effectively. In this paper, we propose CINEMA, a novel framework for coherent multi-subject video generation by leveraging Multimodal Large Language Model (MLLM). Our approach eliminates the need for explicit correspondences between subject images and text entities, mitigating ambiguity and reducing annotation effort. By leveraging MLLM to interpret subject relationships, our method facilitates scalability, enabling the use of large and diverse datasets for training. Furthermore, our framework can be conditioned on varying numbers of subjects, offering greater flexibility in personalized content creation. Through extensive evaluations, we demonstrate that our approach significantly improves subject consistency, and overall video coherence, paving the way for advanced applications in storytelling, interactive media, and personalized video generation.