 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating from Benign to Dynamic Adversarial: A Squid Game for Large Language Models
Nov 12, 2025



Contemporary benchmarks are struggling to keep pace with the development of large language models (LLMs). Although they are indispensable to evaluate model performance on various tasks, it is uncertain whether the models trained on Internet data have genuinely learned how to solve problems or merely seen the questions before. This potential data contamination issue presents a fundamental challenge to establishing trustworthy evaluation frameworks. Meanwhile, existing benchmarks predominantly assume benign, resource-rich settings, leaving the behavior of LLMs under pressure unexplored. In this paper, we introduce Squid Game, a dynamic and adversarial evaluation environment with resource-constrained and asymmetric information settings elaborated to evaluate LLMs through interactive gameplay against other LLM opponents. Notably, Squid Game consists of six elimination-style levels, focusing on multi-faceted abilities, such as instruction-following, code, reasoning, planning, and safety alignment. We evaluate over 50 LLMs on Squid Game, presenting the largest behavioral evaluation study of general LLMs on dynamic adversarial scenarios. We observe a clear generational phase transition on performance in the same model lineage and find evidence that some models resort to speculative shortcuts to win the game, indicating the possibility of higher-level evaluation paradigm contamination in static benchmarks. Furthermore, we compare prominent LLM benchmarks and Squid Game with correlation analyses, highlighting that dynamic evaluation can serve as a complementary part for static evaluations. The code and data will be released in the future.
One Battle After Another: Probing LLMs' Limits on Multi-Turn Instruction Following with a Benchmark Evolving Framework
Nov 05, 2025Understanding how well large language models can follow users' instructions throughout a dialogue spanning multiple topics is of great importance for data-intensive conversational applications. Existing benchmarks are often limited to a fixed number of turns, making them susceptible to saturation and failing to account for the user's interactive experience. In this work, we propose an extensible framework for assessing multi-turn instruction-following ability. At its core, our framework decouples linguistic surface forms from user intent simulation through a three-layer mechanism that tracks constraints, instructions, and topics. This framework mimics User-LLM interaction by enabling the dynamic construction of benchmarks with state changes and tracebacks, terminating a conversation only when the model exhausts a simulated user's patience. We define a suite of metrics capturing the quality of the interaction process. Using this framework, we construct EvolIF, an evolving instruction-following benchmark incorporating nine distinct constraint types. Our results indicate that GPT-5 exhibits superior instruction-following performance. It sustains an average of 18.54 conversational turns and demonstrates 70.31% robustness, outperforming Gemini-2.5-Pro by a significant margin of 11.41%, while other models lag far behind. All of the data and code will be made publicly available online.
$\text{G}^2$RPO: Granular GRPO for Precise Reward in Flow Models
Oct 02, 2025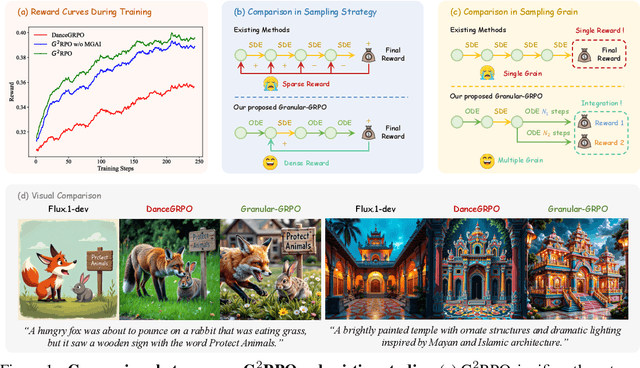
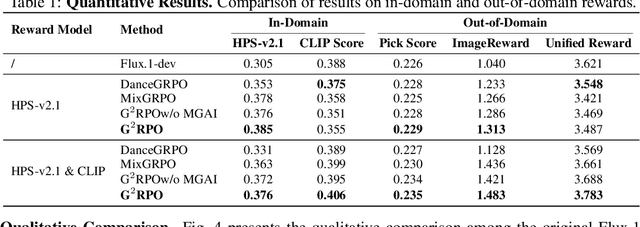
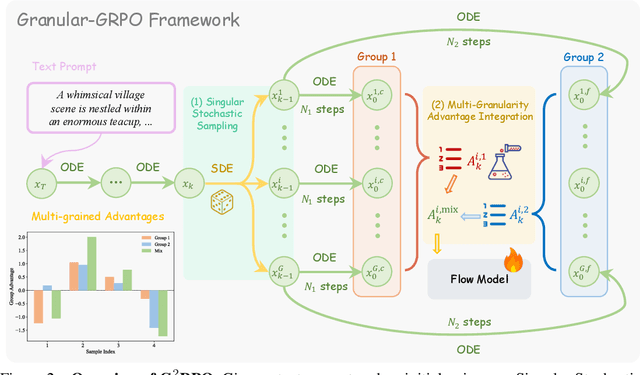
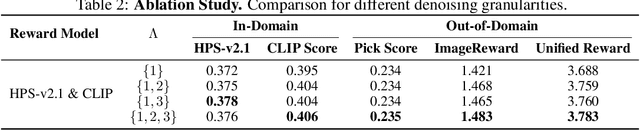
The integration of online reinforcement learning (RL) into diffusion and flow models has recently emerged as a promising approach for aligning generative models with human preferences. Stochastic sampling via Stochastic Differential Equations (SDE) is employed during the denoising process to generate diverse denoising directions for RL exploration. While existing methods effectively explore potential high-value samples, they suffer from sub-optimal preference alignment due to sparse and narrow reward signals. To address these challenges, we propose a novel Granular-GRPO ($\text{G}^2$RPO ) framework that achieves precise and comprehensive reward assessments of sampling directions in reinforcement learning of flow models. Specifically, a Singular Stochastic Sampling strategy is introduced to support step-wise stochastic exploration while enforcing a high correlation between the reward and the injected noise, thereby facilitating a faithful reward for each SDE perturbation. Concurrently, to eliminate the bias inherent in fixed-granularity denoising, we introduce a Multi-Granularity Advantage Integration module that aggregates advantages computed at multiple diffusion scales, producing a more comprehensive and robust evaluation of the sampling directions. Experiments conducted on various reward models, including both in-domain and out-of-domain evaluations, demonstrate that our $\text{G}^2$RPO significantly outperforms existing flow-based GRPO baselines,highlighting its effectiveness and robustness.
A Multi-To-One Interview Paradigm for Efficient MLLM Evaluation
Sep 18, 2025The rapid progress of Multi-Modal Large Language Models (MLLMs) has spurred the creation of numerous benchmarks. However, conventional full-coverage Question-Answering evaluations suffer from high redundancy and low efficiency. Inspired by human interview processes, we propose a multi-to-one interview paradigm for efficient MLLM evaluation. Our framework consists of (i) a two-stage interview strategy with pre-interview and formal interview phases, (ii) dynamic adjustment of interviewer weights to ensure fairness, and (iii) an adaptive mechanism for question difficulty-level chosen. Experiments on different benchmarks show that the proposed paradigm achieves significantly higher correlation with full-coverage results than random sampling, with improvements of up to 17.6% in PLCC and 16.7% in SRCC, while reducing the number of required questions. These findings demonstrate that the proposed paradigm provides a reliable and efficient alternative for large-scale MLLM benchmarking.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
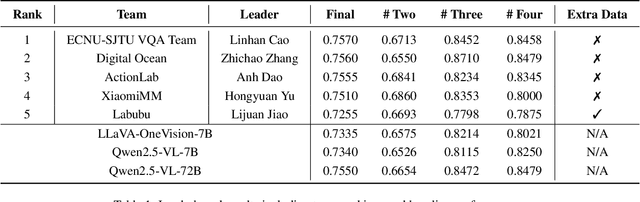
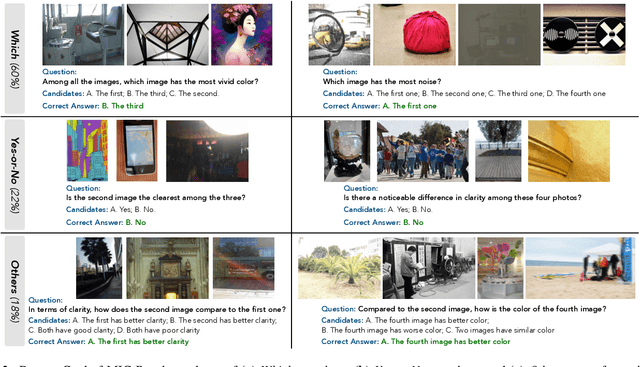
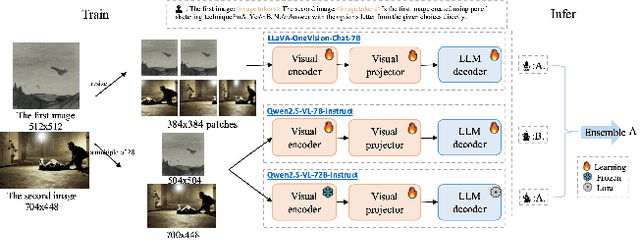
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
MMReID-Bench: Unleashing the Power of MLLMs for Effective and Versatile Person Re-identification
Aug 09, 2025Person re-identification (ReID) aims to retrieve the images of an interested person in the gallery images, with wide applications in medical rehabilitation, abnormal behavior detection, and public security. However, traditional person ReID models suffer from uni-modal capability, leading to poor generalization ability in multi-modal data, such as RGB, thermal, infrared, sketch images, textual descriptions, etc. Recently, the emergence of multi-modal large language models (MLLMs) shows a promising avenue for addressing this problem. Despite this potential, existing methods merely regard MLLMs as feature extractors or caption generators, which do not fully unleash their reasoning, instruction-following, and cross-modal understanding capabilities. To bridge this gap, we introduce MMReID-Bench, the first multi-task multi-modal benchmark specifically designed for person ReID. The MMReID-Bench includes 20,710 multi-modal queries and gallery images covering 10 different person ReID tasks. Comprehensive experiments demonstrate the remarkable capabilities of MLLMs in delivering effective and versatile person ReID. Nevertheless, they also have limitations in handling a few modalities, particularly thermal and infrared data. We hope MMReID-Bench can facilitate the community to develop more robust and generalizable multimodal foundation models for person ReID.
Can Large Models Fool the Eye? A New Turing Test for Biological Animation
Aug 08, 2025Evaluating the abilities of large models and manifesting their gaps are challenging. Current benchmarks adopt either ground-truth-based score-form evaluation on static datasets or indistinct textual chatbot-style human preferences collection, which may not provide users with immediate, intuitive, and perceptible feedback on performance differences. In this paper, we introduce BioMotion Arena, a novel framework for evaluating large language models (LLMs) and multimodal large language models (MLLMs) via visual animation. Our methodology draws inspiration from the inherent visual perception of motion patterns characteristic of living organisms that utilizes point-light source imaging to amplify the performance discrepancies between models. Specifically, we employ a pairwise comparison evaluation and collect more than 45k votes for 53 mainstream LLMs and MLLMs on 90 biological motion variants. Data analyses show that the crowd-sourced human votes are in good agreement with those of expert raters, demonstrating the superiority of our BioMotion Arena in offering discriminative feedback. We also find that over 90\% of evaluated models, including the cutting-edge open-source InternVL3 and proprietary Claude-4 series, fail to produce fundamental humanoid point-light groups, much less smooth and biologically plausible motions. This enables BioMotion Arena to serve as a challenging benchmark for performance visualization and a flexible evaluation framework without restrictions on ground-truth.
AU-IQA: A Benchmark Dataset for Perceptual Quality Assessment of AI-Enhanced User-Generated Content
Aug 07, 2025AI-based image enhancement techniques have been widely adopted in various visual applications, significantly improving the perceptual quality of user-generated content (UGC). However, the lack of specialized quality assessment models has become a significant limiting factor in this field, limiting user experience and hindering the advancement of enhancement methods. While perceptual quality assessment methods have shown strong performance on UGC and AIGC individually, their effectiveness on AI-enhanced UGC (AI-UGC) which blends features from both, remains largely unexplored. To address this gap, we construct AU-IQA, a benchmark dataset comprising 4,800 AI-UGC images produced by three representative enhancement types which include super-resolution, low-light enhancement, and denoising. On this dataset, we further evaluate a range of existing quality assessment models, including traditional IQA methods and large multimodal models. Finally, we provide a comprehensive analysis of how well current approaches perform in assessing the perceptual quality of AI-UGC. The access link to the AU-IQA is https://github.com/WNNGGU/AU-IQA-Dataset.
LayerT2V: Interactive Multi-Object Trajectory Layering for Video Generation
Aug 06, 2025Controlling object motion trajectories in Text-to-Video (T2V) generation is a challenging and relatively under-explored area, particularly in scenarios involving multiple moving objects. Most community models and datasets in the T2V domain are designed for single-object motion, limiting the performance of current generative models in multi-object tasks. Additionally, existing motion control methods in T2V either lack support for multi-object motion scenes or experience severe performance degradation when object trajectories intersect, primarily due to the semantic conflicts in colliding regions. To address these limitations, we introduce LayerT2V, the first approach for generating video by compositing background and foreground objects layer by layer. This layered generation enables flexible integration of multiple independent elements within a video, positioning each element on a distinct "layer" and thus facilitating coherent multi-object synthesis while enhancing control over the generation process. Extensive experiments demonstrate the superiority of LayerT2V in generating complex multi-object scenarios, showcasing 1.4x and 4.5x improvements in mIoU and AP50 metrics over state-of-the-art (SOTA) methods. Project page and code are available at https://kr-panghu.github.io/LayerT2V/ .
TR-PTS: Task-Relevant Parameter and Token Selection for Efficient Tuning
Jul 30, 2025Large pre-trained models achieve remarkable performance in vision tasks but are impractical for fine-tuning due to high computational and storage costs. Parameter-Efficient Fine-Tuning (PEFT) methods mitigate this issue by updating only a subset of parameters; however, most existing approaches are task-agnostic, failing to fully exploit task-specific adaptations, which leads to suboptimal efficiency and performance. To address this limitation, we propose Task-Relevant Parameter and Token Selection (TR-PTS), a task-driven framework that enhances both computational efficiency and accuracy. Specifically, we introduce Task-Relevant Parameter Selection, which utilizes the Fisher Information Matrix (FIM) to identify and fine-tune only the most informative parameters in a layer-wise manner, while keeping the remaining parameters frozen. Simultaneously, Task-Relevant Token Selection dynamically preserves the most informative tokens and merges redundant ones, reducing computational overhead. By jointly optimizing parameters and tokens, TR-PTS enables the model to concentrate on task-discriminative information. We evaluate TR-PTS on benchmark, including FGVC and VTAB-1k, where it achieves state-of-the-art performance, surpassing full fine-tuning by 3.40% and 10.35%, respectively. The code are available at https://github.com/synbol/TR-PTS.