 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMReID-Bench: Unleashing the Power of MLLMs for Effective and Versatile Person Re-identification
Aug 09, 2025Person re-identification (ReID) aims to retrieve the images of an interested person in the gallery images, with wide applications in medical rehabilitation, abnormal behavior detection, and public security. However, traditional person ReID models suffer from uni-modal capability, leading to poor generalization ability in multi-modal data, such as RGB, thermal, infrared, sketch images, textual descriptions, etc. Recently, the emergence of multi-modal large language models (MLLMs) shows a promising avenue for addressing this problem. Despite this potential, existing methods merely regard MLLMs as feature extractors or caption generators, which do not fully unleash their reasoning, instruction-following, and cross-modal understanding capabilities. To bridge this gap, we introduce MMReID-Bench, the first multi-task multi-modal benchmark specifically designed for person ReID. The MMReID-Bench includes 20,710 multi-modal queries and gallery images covering 10 different person ReID tasks. Comprehensive experiments demonstrate the remarkable capabilities of MLLMs in delivering effective and versatile person ReID. Nevertheless, they also have limitations in handling a few modalities, particularly thermal and infrared data. We hope MMReID-Bench can facilitate the community to develop more robust and generalizable multimodal foundation models for person ReID.
Can Large Models Fool the Eye? A New Turing Test for Biological Animation
Aug 08, 2025Evaluating the abilities of large models and manifesting their gaps are challenging. Current benchmarks adopt either ground-truth-based score-form evaluation on static datasets or indistinct textual chatbot-style human preferences collection, which may not provide users with immediate, intuitive, and perceptible feedback on performance differences. In this paper, we introduce BioMotion Arena, a novel framework for evaluating large language models (LLMs) and multimodal large language models (MLLMs) via visual animation. Our methodology draws inspiration from the inherent visual perception of motion patterns characteristic of living organisms that utilizes point-light source imaging to amplify the performance discrepancies between models. Specifically, we employ a pairwise comparison evaluation and collect more than 45k votes for 53 mainstream LLMs and MLLMs on 90 biological motion variants. Data analyses show that the crowd-sourced human votes are in good agreement with those of expert raters, demonstrating the superiority of our BioMotion Arena in offering discriminative feedback. We also find that over 90\% of evaluated models, including the cutting-edge open-source InternVL3 and proprietary Claude-4 series, fail to produce fundamental humanoid point-light groups, much less smooth and biologically plausible motions. This enables BioMotion Arena to serve as a challenging benchmark for performance visualization and a flexible evaluation framework without restrictions on ground-truth.
One-Step Two-Critic Deep Reinforcement Learning for Inverter-based Volt-Var Control in Active Distribution Networks
Mar 30, 2022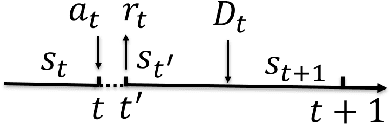
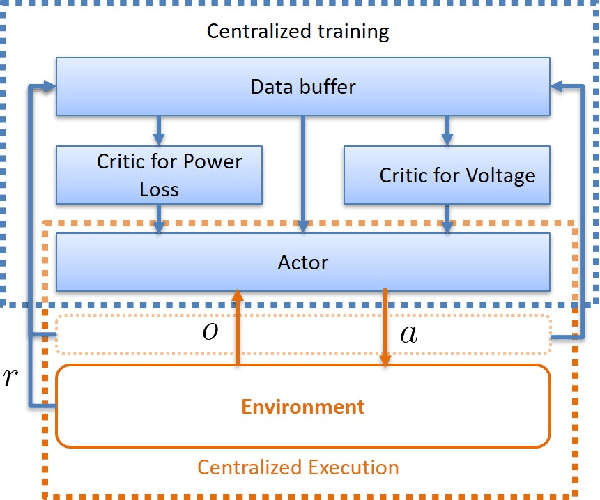
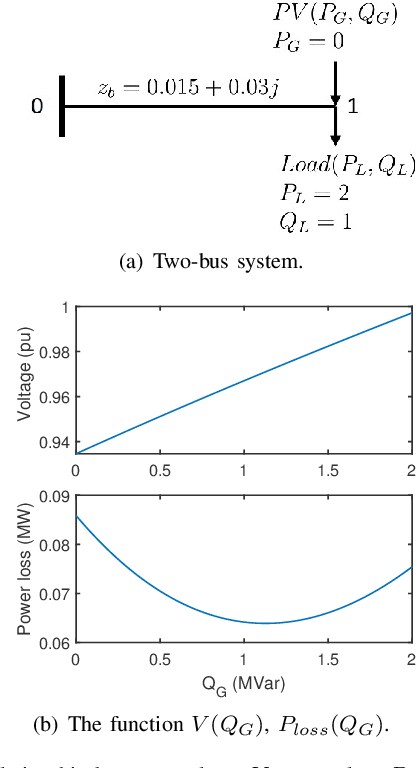
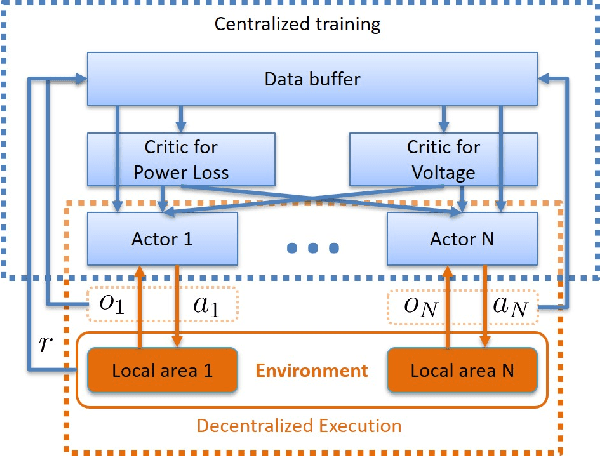
A one-step two-critic deep reinforcement learning (OSTC-DRL) approach for inverter-based volt-var control (IB-VVC) in active distribution networks is proposed in this paper. Firstly, considering IB-VVC can be formulated as a single-period optimization problem, we formulate the IB-VVC as a one-step Markov decision process rather than the standard Markov decision process, which simplifies the DRL learning task. Then we design the one-step actor-critic DRL scheme which is a simplified version of recent DRL algorithms, and it avoids the issue of Q value overestimation successfully. Furthermore, considering two objectives of VVC: minimizing power loss and eliminating voltage violation, we utilize two critics to approximate the rewards of two objectives separately. It simplifies the approximation tasks of each critic, and avoids the interaction effect between two objectives in the learning process of critic. The OSTC-DRL approach integrates the one-step actor-critic DRL scheme and the two-critic technology. Based on the OSTC-DRL, we design two centralized DRL algorithms. Further, we extend the OSTC-DRL to multi-agent OSTC-DRL for decentralized IB-VVC and design two multi-agent DRL algorithms. Simulations demonstrate that the proposed OSTC-DRL has a faster convergence rate and a better control performance, and the multi-agent OSTC-DRL works well for decentralized IB-VVC problems.