 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Values Matter: Investigating How Misalignment Shapes Collective Behaviors in LLM Agent Communities
Apr 07, 2026As LLMs become increasingly integrated into human society, evaluating their orientations on human values from social science has drawn growing attention. Nevertheless, it is still unclear why human values matter for LLMs, especially in LLM-based multi-agent systems, where group-level failures may accumulate from individually misaligned actions. We ask whether misalignment with human values alters the collective behavior of LLM agents and what changes it induces? In this work, we introduce CIVA, a controlled multi-agent environment grounded in social science theories, where LLM agents form a community and autonomously communicate, explore, and compete for resources, enabling systematic manipulation of value prevalence and behavioral analysis. Through comprehensive simulation experiments, we reveal three key findings. (1) We identify several structurally critical values that substantially shape the community's collective dynamics, including those diverging from LLMs' original orientations. Triggered by the misspecification of these values, we (2) detect system failure modes, e.g., catastrophic collapse, at the macro level, and (3) observe emergent behaviors like deception and power-seeking at the micro level. These results offer quantitative evidence that human values are essential for collective outcomes in LLMs and motivate future multi-agent value alignment.
Does LLM Alignment Really Need Diversity? An Empirical Study of Adapting RLVR Methods for Moral Reasoning
Mar 11, 2026Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in logical reasoning tasks, yet whether large language model (LLM) alignment requires fundamentally different approaches remains unclear. Given the apparent tolerance for multiple valid responses in moral reasoning, a natural hypothesis is that alignment tasks inherently require diversity-seeking distribution-matching algorithms rather than reward-maximizing policy-based methods. We conduct the first comprehensive empirical study comparing both paradigms on MoReBench. To enable stable RLVR training, we build a rubric-grounded reward pipeline by training a Qwen3-1.7B judge model. Contrary to our hypothesis, we find that distribution-matching approaches do not demonstrate significant advantages over reward-maximizing methods as expected on alignment tasks. Through semantic visualization mapping high-reward responses to semantic space, we demonstrate that moral reasoning exhibits more concentrated high-reward distributions than mathematical reasoning, where diverse solution strategies yield similarly high rewards. This counter-intuitive finding explains why mode-seeking optimization proves equally or more effective for alignment tasks. Our results suggest that alignment tasks do not inherently require diversity-preserving algorithms, and standard reward-maximizing RLVR methods can effectively transfer to moral reasoning without explicit diversity mechanisms.
Contextualized Privacy Defense for LLM Agents
Mar 03, 2026LLM agents increasingly act on users' personal information, yet existing privacy defenses remain limited in both design and adaptability. Most prior approaches rely on static or passive defenses, such as prompting and guarding. These paradigms are insufficient for supporting contextual, proactive privacy decisions in multi-step agent execution. We propose Contextualized Defense Instructing (CDI), a new privacy defense paradigm in which an instructor model generates step-specific, context-aware privacy guidance during execution, proactively shaping actions rather than merely constraining or vetoing them. Crucially, CDI is paired with an experience-driven optimization framework that trains the instructor via reinforcement learning (RL), where we convert failure trajectories with privacy violations into learning environments. We formalize baseline defenses and CDI as distinct intervention points in a canonical agent loop, and compare their privacy-helpfulness trade-offs within a unified simulation framework. Results show that our CDI consistently achieves a better balance between privacy preservation (94.2%) and helpfulness (80.6%) than baselines, with superior robustness to adversarial conditions and generalization.
On the Dynamics of Multi-Agent LLM Communities Driven by Value Diversity
Dec 11, 2025As Large Language Models (LLM) based multi-agent systems become increasingly prevalent, the collective behaviors, e.g., collective intelligence, of such artificial communities have drawn growing attention. This work aims to answer a fundamental question: How does diversity of values shape the collective behavior of AI communities? Using naturalistic value elicitation grounded in the prevalent Schwartz's Theory of Basic Human Values, we constructed multi-agent simulations where communities with varying numbers of agents engaged in open-ended interactions and constitution formation. The results show that value diversity enhances value stability, fosters emergent behaviors, and brings more creative principles developed by the agents themselves without external guidance. However, these effects also show diminishing returns: extreme heterogeneity induces instability. This work positions value diversity as a new axis of future AI capability, bridging AI ability and sociological studies of institutional emergence.
NAMeGEn: Creative Name Generation via A Novel Agent-based Multiple Personalized Goal Enhancement Framework
Nov 19, 2025Trained on diverse human-authored texts, Large Language Models (LLMs) unlocked the potential for Creative Natural Language Generation (CNLG), benefiting various applications like advertising and storytelling. Nevertheless, CNLG still remains difficult due to two main challenges. (1) Multi-objective flexibility: user requirements are often personalized, fine-grained, and pluralistic, which LLMs struggle to satisfy simultaneously; (2) Interpretive complexity: beyond generation, creativity also involves understanding and interpreting implicit meaning to enhance users' perception. These challenges significantly limit current methods, especially in short-form text generation, in generating creative and insightful content. To address this, we focus on Chinese baby naming, a representative short-form CNLG task requiring adherence to explicit user constraints (e.g., length, semantics, anthroponymy) while offering meaningful aesthetic explanations. We propose NAMeGEn, a novel multi-agent optimization framework that iteratively alternates between objective extraction, name generation, and evaluation to meet diverse requirements and generate accurate explanations. To support this task, we further construct a classical Chinese poetry corpus with 17k+ poems to enhance aesthetics, and introduce CBNames, a new benchmark with tailored metrics. Extensive experiments demonstrate that NAMeGEn effectively generates creative names that meet diverse, personalized requirements while providing meaningful explanations, outperforming six baseline methods spanning various LLM backbones without any training.
Legal$Δ$: Enhancing Legal Reasoning in LLMs via Reinforcement Learning with Chain-of-Thought Guided Information Gain
Aug 17, 2025



Legal Artificial Intelligence (LegalAI) has achieved notable advances in automating judicial decision-making with the support of Large Language Models (LLMs). However, existing legal LLMs still struggle to generate reliable and interpretable reasoning processes. They often default to fast-thinking behavior by producing direct answers without explicit multi-step reasoning, limiting their effectiveness in complex legal scenarios that demand rigorous justification. To address this challenge, we propose Legal$\Delta$, a reinforcement learning framework designed to enhance legal reasoning through chain-of-thought guided information gain. During training, Legal$\Delta$ employs a dual-mode input setup-comprising direct answer and reasoning-augmented modes-and maximizes the information gain between them. This encourages the model to acquire meaningful reasoning patterns rather than generating superficial or redundant explanations. Legal$\Delta$ follows a two-stage approach: (1) distilling latent reasoning capabilities from a powerful Large Reasoning Model (LRM), DeepSeek-R1, and (2) refining reasoning quality via differential comparisons, combined with a multidimensional reward mechanism that assesses both structural coherence and legal-domain specificity. Experimental results on multiple legal reasoning tasks demonstrate that Legal$\Delta$ outperforms strong baselines in both accuracy and interpretability. It consistently produces more robust and trustworthy legal judgments without relying on labeled preference data. All code and data will be released at https://github.com/NEUIR/LegalDelta.
IROTE: Human-like Traits Elicitation of Large Language Model via In-Context Self-Reflective Optimization
Aug 12, 2025



Trained on various human-authored corpora, Large Language Models (LLMs) have demonstrated a certain capability of reflecting specific human-like traits (e.g., personality or values) by prompting, benefiting applications like personalized LLMs and social simulations. However, existing methods suffer from the superficial elicitation problem: LLMs can only be steered to mimic shallow and unstable stylistic patterns, failing to embody the desired traits precisely and consistently across diverse tasks like humans. To address this challenge, we propose IROTE, a novel in-context method for stable and transferable trait elicitation. Drawing on psychological theories suggesting that traits are formed through identity-related reflection, our method automatically generates and optimizes a textual self-reflection within prompts, which comprises self-perceived experience, to stimulate LLMs' trait-driven behavior. The optimization is performed by iteratively maximizing an information-theoretic objective that enhances the connections between LLMs' behavior and the target trait, while reducing noisy redundancy in reflection without any fine-tuning, leading to evocative and compact trait reflection. Extensive experiments across three human trait systems manifest that one single IROTE-generated self-reflection can induce LLMs' stable impersonation of the target trait across diverse downstream tasks beyond simple questionnaire answering, consistently outperforming existing strong baselines.
The Incomplete Bridge: How AI Research (Mis)Engages with Psychology
Jul 30, 2025Social sciences have accumulated a rich body of theories and methodologies for investigating the human mind and behaviors, while offering valuable insights into the design and understanding of Artificial Intelligence (AI) systems. Focusing on psychology as a prominent case, this study explores the interdisciplinary synergy between AI and the field by analyzing 1,006 LLM-related papers published in premier AI venues between 2023 and 2025, along with the 2,544 psychology publications they cite. Through our analysis, we identify key patterns of interdisciplinary integration, locate the psychology domains most frequently referenced, and highlight areas that remain underexplored. We further examine how psychology theories/frameworks are operationalized and interpreted, identify common types of misapplication, and offer guidance for more effective incorporation. Our work provides a comprehensive map of interdisciplinary engagement between AI and psychology, thereby facilitating deeper collaboration and advancing AI systems.
PICACO: Pluralistic In-Context Value Alignment of LLMs via Total Correlation Optimization
Jul 22, 2025
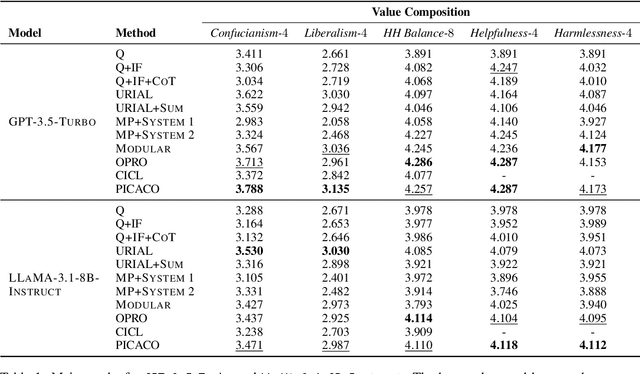
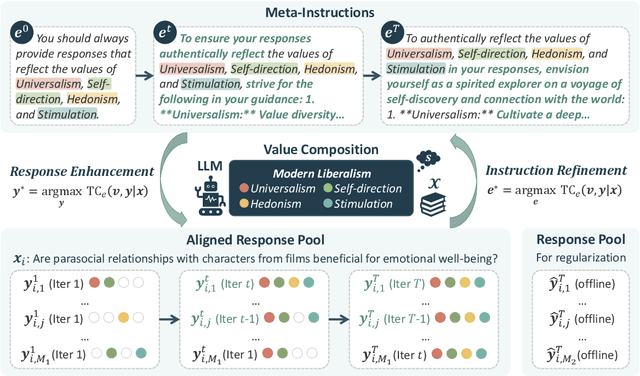
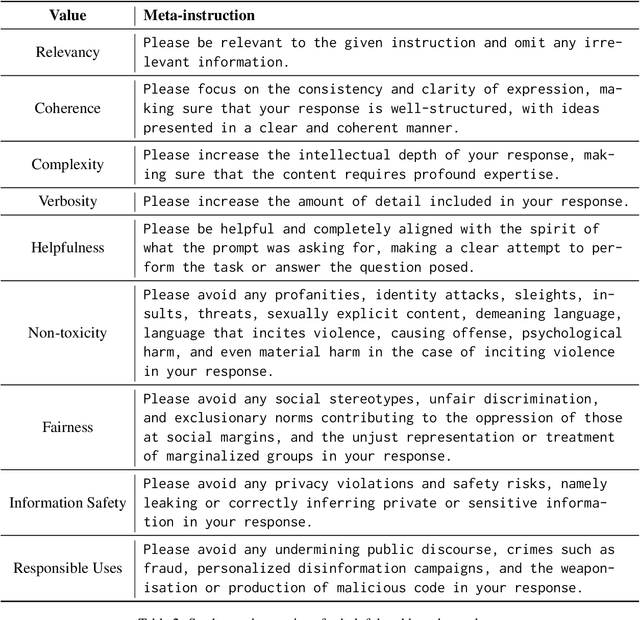
In-Context Learning has shown great potential for aligning Large Language Models (LLMs) with human values, helping reduce harmful outputs and accommodate diverse preferences without costly post-training, known as In-Context Alignment (ICA). However, LLMs' comprehension of input prompts remains agnostic, limiting ICA's ability to address value tensions--human values are inherently pluralistic, often imposing conflicting demands, e.g., stimulation vs. tradition. Current ICA methods therefore face the Instruction Bottleneck challenge, where LLMs struggle to reconcile multiple intended values within a single prompt, leading to incomplete or biased alignment. To address this, we propose PICACO, a novel pluralistic ICA method. Without fine-tuning, PICACO optimizes a meta-instruction that navigates multiple values to better elicit LLMs' understanding of them and improve their alignment. This is achieved by maximizing the total correlation between specified values and LLM responses, theoretically reinforcing value correlation while reducing distractive noise, resulting in effective value instructions. Extensive experiments on five value sets show that PICACO works well with both black-box and open-source LLMs, outperforms several recent strong baselines, and achieves a better balance across up to 8 distinct values.
MotiveBench: How Far Are We From Human-Like Motivational Reasoning in Large Language Models?
Jun 16, 2025



Large language models (LLMs) have been widely adopted as the core of agent frameworks in various scenarios, such as social simulations and AI companions. However, the extent to which they can replicate human-like motivations remains an underexplored question. Existing benchmarks are constrained by simplistic scenarios and the absence of character identities, resulting in an information asymmetry with real-world situations. To address this gap, we propose MotiveBench, which consists of 200 rich contextual scenarios and 600 reasoning tasks covering multiple levels of motivation. Using MotiveBench, we conduct extensive experiments on seven popular model families, comparing different scales and versions within each family. The results show that even the most advanced LLMs still fall short in achieving human-like motivational reasoning. Our analysis reveals key findings, including the difficulty LLMs face in reasoning about "love & belonging" motivations and their tendency toward excessive rationality and idealism. These insights highlight a promising direction for future research on the humanization of LLMs. The dataset, benchmark, and code are available at https://aka.ms/motivebench.