 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneExpander: Expanding 3D Scenes with Free-Form Inserted Views
Mar 31, 2026World building with 3D scene representations is increasingly important for content creation, simulation, and interactive experiences, yet real workflows are inherently iterative: creators must repeatedly extend an existing scene under user control. Motivated by this research gap, we study 3D scene expansion in a user-centric workflow: starting from a real scene captured by multi-view images, we extend its coverage by inserting an additional view synthesized by a generative model. Unlike simple object editing or style transfer in a fixed scene, the inserted view is often 3D-misaligned with the original reconstruction, introducing geometry shifts, hallucinated content, or view-dependent artifacts that break global multi-view consistency. To address the challenge, we propose SceneExpander, which applies test-time adaptation to a parametric feed-forward 3D reconstruction model with two complementary distillation signals: anchor distillation stabilizes the original scene by distilling geometric cues from the captured views, while inserted-view self-distillation preserves observation-supported predictions yet adapts latent geometry and appearance to accommodate the misaligned inserted view. Experiments on ETH scenes and online data demonstrate improved expansion behavior and reconstruction quality under misalignment.
ContextDrag: Precise Drag-Based Image Editing via Context-Preserving Token Injection and Position-Consistent Attention
Dec 09, 2025Drag-based image editing aims to modify visual content followed by user-specified drag operations. Despite existing methods having made notable progress, they still fail to fully exploit the contextual information in the reference image, including fine-grained texture details, leading to edits with limited coherence and fidelity. To address this challenge, we introduce ContextDrag, a new paradigm for drag-based editing that leverages the strong contextual modeling capability of editing models, such as FLUX-Kontext. By incorporating VAE-encoded features from the reference image, ContextDrag can leverage rich contextual cues and preserve fine-grained details, without the need for finetuning or inversion. Specifically, ContextDrag introduced a novel Context-preserving Token Injection (CTI) that injects noise-free reference features into their correct destination locations via a Latent-space Reverse Mapping (LRM) algorithm. This strategy enables precise drag control while preserving consistency in both semantics and texture details. Second, ContextDrag adopts a novel Position-Consistent Attention (PCA), which positional re-encodes the reference tokens and applies overlap-aware masking to eliminate interference from irrelevant reference features. Extensive experiments on DragBench-SR and DragBench-DR demonstrate that our approach surpasses all existing SOTA methods. Code will be publicly available.
Mod-Adapter: Tuning-Free and Versatile Multi-concept Personalization via Modulation Adapter
May 24, 2025Personalized text-to-image generation aims to synthesize images of user-provided concepts in diverse contexts. Despite recent progress in multi-concept personalization, most are limited to object concepts and struggle to customize abstract concepts (e.g., pose, lighting). Some methods have begun exploring multi-concept personalization supporting abstract concepts, but they require test-time fine-tuning for each new concept, which is time-consuming and prone to overfitting on limited training images. In this work, we propose a novel tuning-free method for multi-concept personalization that can effectively customize both object and abstract concepts without test-time fine-tuning. Our method builds upon the modulation mechanism in pretrained Diffusion Transformers (DiTs) model, leveraging the localized and semantically meaningful properties of the modulation space. Specifically, we propose a novel module, Mod-Adapter, to predict concept-specific modulation direction for the modulation process of concept-related text tokens. It incorporates vision-language cross-attention for extracting concept visual features, and Mixture-of-Experts (MoE) layers that adaptively map the concept features into the modulation space. Furthermore, to mitigate the training difficulty caused by the large gap between the concept image space and the modulation space, we introduce a VLM-guided pretraining strategy that leverages the strong image understanding capabilities of vision-language models to provide semantic supervision signals. For a comprehensive comparison, we extend a standard benchmark by incorporating abstract concepts. Our method achieves state-of-the-art performance in multi-concept personalization, supported by quantitative, qualitative, and human evaluations.
UAV-Aided Progressive Interference Source Localization Based on Improved Trust Region Optimization
Apr 27, 2025



Trust region optimization-based received signal strength indicator (RSSI) interference source localization methods have been widely used in low-altitude research. However, these methods often converge to local optima in complex environments, degrading the positioning performance. This paper presents a novel unmanned aerial vehicle (UAV)-aided progressive interference source localization method based on improved trust region optimization. By combining the Levenberg-Marquardt (LM) algorithm with particle swarm optimization (PSO), our proposed method can effectively enhance the success rate of localization. We also propose a confidence quantification approach based on the UAV-to-ground channel model. This approach considers the surrounding environmental information of the sampling points and dynamically adjusts the weight of the sampling data during the data fusion. As a result, the overall positioning accuracy can be significantly improved. Experimental results demonstrate the proposed method can achieve high-precision interference source localization in noisy and interference-prone environments.
Style-Preserving Lip Sync via Audio-Aware Style Reference
Aug 10, 2024



Audio-driven lip sync has recently drawn significant attention due to its widespread application in the multimedia domain. Individuals exhibit distinct lip shapes when speaking the same utterance, attributed to the unique speaking styles of individuals, posing a notable challenge for audio-driven lip sync. Earlier methods for such task often bypassed the modeling of personalized speaking styles, resulting in sub-optimal lip sync conforming to the general styles. Recent lip sync techniques attempt to guide the lip sync for arbitrary audio by aggregating information from a style reference video, yet they can not preserve the speaking styles well due to their inaccuracy in style aggregation. This work proposes an innovative audio-aware style reference scheme that effectively leverages the relationships between input audio and reference audio from style reference video to address the style-preserving audio-driven lip sync. Specifically, we first develop an advanced Transformer-based model adept at predicting lip motion corresponding to the input audio, augmented by the style information aggregated through cross-attention layers from style reference video. Afterwards, to better render the lip motion into realistic talking face video, we devise a conditional latent diffusion model, integrating lip motion through modulated convolutional layers and fusing reference facial images via spatial cross-attention layers. Extensive experiments validate the efficacy of the proposed approach in achieving precise lip sync, preserving speaking styles, and generating high-fidelity, realistic talking face videos.
High-fidelity and Lip-synced Talking Face Synthesis via Landmark-based Diffusion Model
Aug 10, 2024



Audio-driven talking face video generation has attracted increasing attention due to its huge industrial potential. Some previous methods focus on learning a direct mapping from audio to visual content. Despite progress, they often struggle with the ambiguity of the mapping process, leading to flawed results. An alternative strategy involves facial structural representations (e.g., facial landmarks) as intermediaries. This multi-stage approach better preserves the appearance details but suffers from error accumulation due to the independent optimization of different stages. Moreover, most previous methods rely on generative adversarial networks, prone to training instability and mode collapse. To address these challenges, our study proposes a novel landmark-based diffusion model for talking face generation, which leverages facial landmarks as intermediate representations while enabling end-to-end optimization. Specifically, we first establish the less ambiguous mapping from audio to landmark motion of lip and jaw. Then, we introduce an innovative conditioning module called TalkFormer to align the synthesized motion with the motion represented by landmarks via differentiable cross-attention, which enables end-to-end optimization for improved lip synchronization. Besides, TalkFormer employs implicit feature warping to align the reference image features with the target motion for preserving more appearance details. Extensive experiments demonstrate that our approach can synthesize high-fidelity and lip-synced talking face videos, preserving more subject appearance details from the reference image.
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
May 15, 2023



Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker's videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker's face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face's pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.
Sparse Bayesian Learning-Based 3D Spectrum Environment Map Construction-Sampling Optimization, Scenario-Dependent Dictionary Construction and Sparse Recovery
Feb 25, 2023



The spectrum environment map (SEM), which can visualize the information of invisible electromagnetic spectrum, is vital for monitoring, management, and security of spectrum resources in cognitive radio (CR) networks. In view of a limited number of spectrum sensors and constrained sampling time, this paper presents a new three-dimensional (3D) SEM construction scheme based on sparse Bayesian learning (SBL). Firstly, we construct a scenario-dependent channel dictionary matrix by considering the propagation characteristic of the interested scenario. To improve sampling efficiency, a maximum mutual information (MMI)-based optimization algorithm is developed for the layout of sampling sensors. Then, a maximum and minimum distance (MMD) clustering-based SBL algorithm is proposed to recover the spectrum data at the unsampled positions and construct the whole 3D SEM. We finally use the simulation data of the campus scenario to construct the 3D SEMs and compare the proposed method with the state-of-the-art. The recovery performance and the impact of different sparsity on the constructed SEMs are also analyzed. Numerical results show that the proposed scheme can reduce the required spectrum sensor number and has higher accuracy under the low sampling rate.
A Realistic 3D Non-Stationary Channel Model for UAV-to-Vehicle Communications Incorporating Fuselage Posture
Sep 19, 2022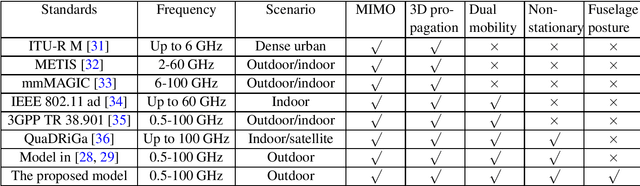
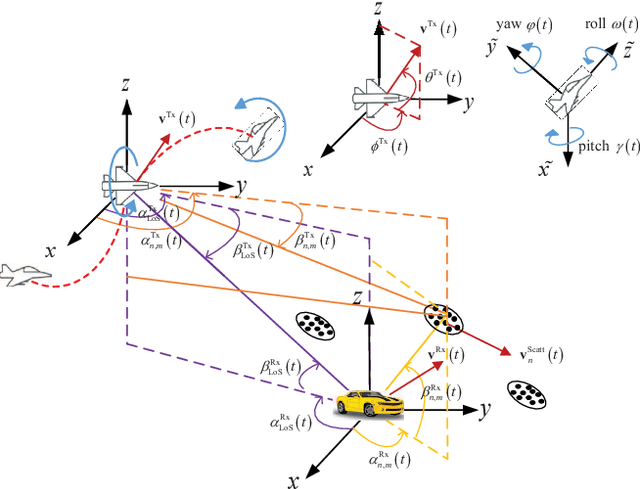
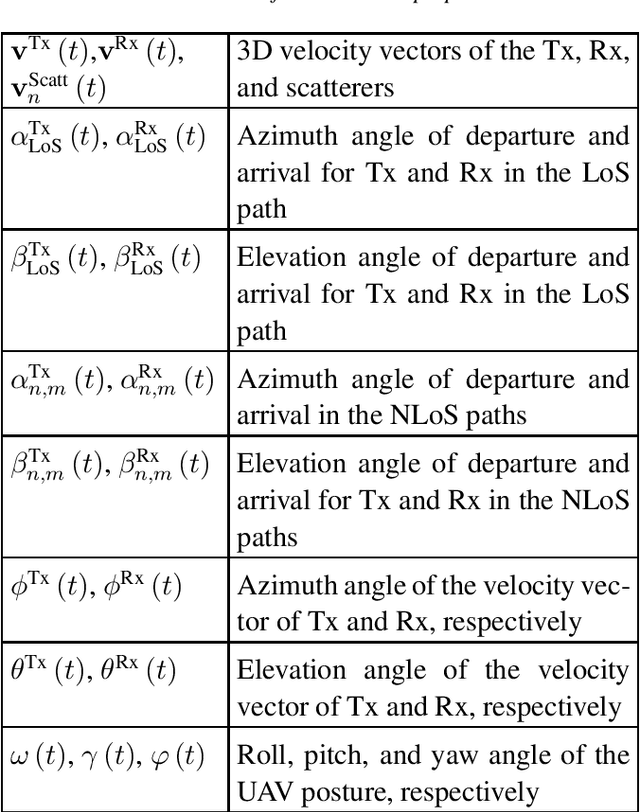
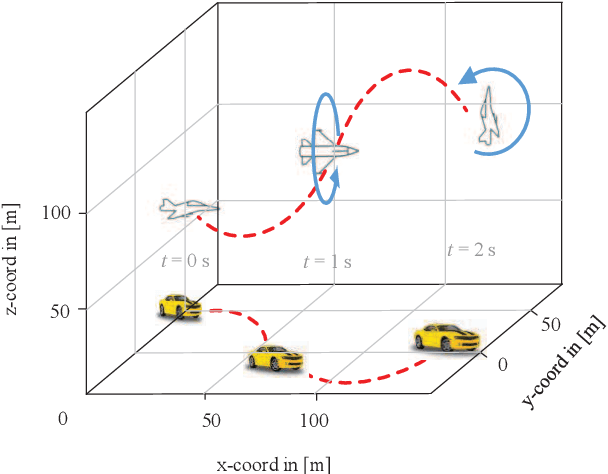
Considering the unmanned aerial vehicle (UAV) three-dimensional (3D) posture, a novel 3D non-stationary geometry-based stochastic model (GBSM) is proposed for multiple-input multiple-output (MIMO) UAV-to-vehicle (U2V) channels. It consists of a line-of-sight (LoS) and non-line-of-sight (NLoS) components. The factor of fuselage posture is considered by introducing a time-variant 3D posture matrix. Some important statistical properties, i.e. the temporal autocorrelation function (ACF) and spatial cross correlation function (CCF), are derived and investigated. Simulation results show that the fuselage posture has significant impact on the U2V channel characteristic and aggravate the non-stationarity. The agreements between analytical, simulated, and measured results verify the correctness of proposed model and derivations. Moreover, it is demonstrated that the proposed model is also compatible to the existing GBSM without considering fuselage posture.
Geometry-Based Stochastic Line-of-Sight Probability Model for A2G Channels under Urban Scenarios
Sep 06, 2021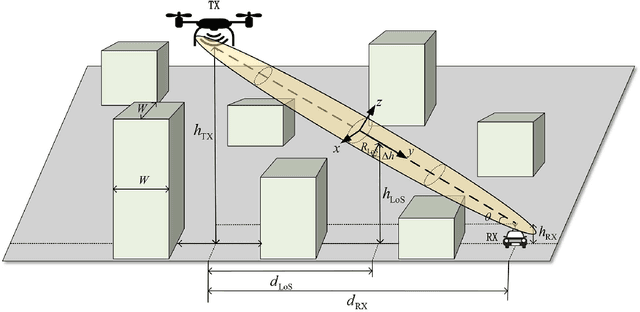
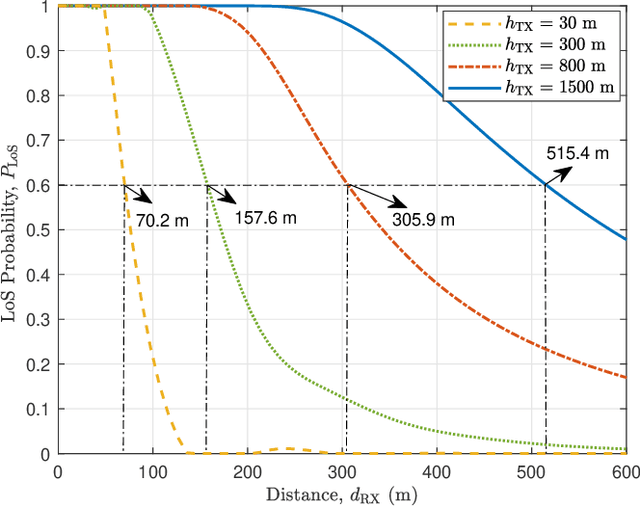
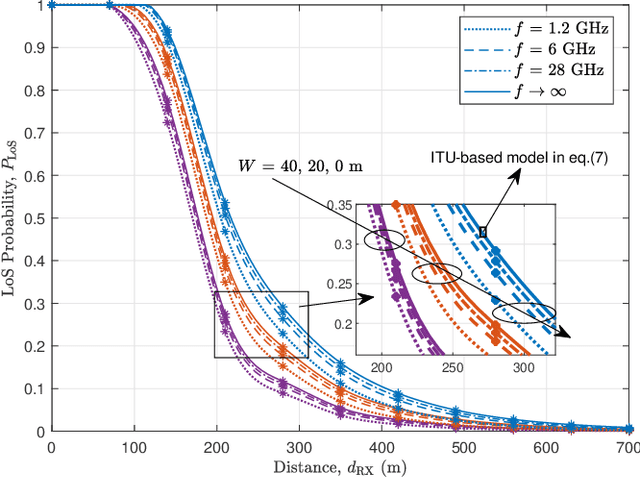
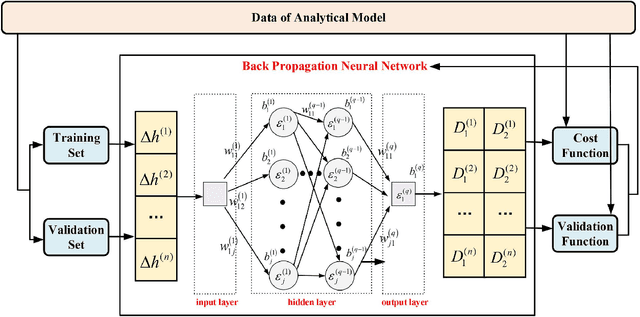
Line-of-sight (LoS) path is essential for the reliability of air-to-ground (A2G) communications, but the existence of LoS path is difficult to predict due to random obstacles on the ground. Based on the statistical geographic information and Fresnel clearance zone, a general stochastic LoS probability model for three-dimensional (3D) A2G channels under urban scenarios is developed. By considering the factors, i.e., building height distribution, building width, building space, carrier frequency, and transceiver's heights, the proposed model is suitable for different frequencies and altitudes. Moreover, in order to get a closed-form expression and reduce the computational complexity, an approximate parametric model is also built with the machine-learning (ML) method to estimate model parameters. The simulation results show that the proposed model has good consistency with existing models at the low altitude. When the altitude increases, it has better performance by comparing with that of the ray-tracing Monte-Carlo simulation data. The analytical results of proposed model are helpful for the channel modeling and performance analysis such as cell coverage, outage probability, and bit error rate in A2G communications.