 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical-Inspired Cytological Whole Slide Image Screening with Just Slide-Level Labels
Jun 06, 2023



Cytology test is effective, non-invasive, convenient, and inexpensive for clinical cancer screening. ThinPrep, a commonly used liquid-based specimen, can be scanned to generate digital whole slide images (WSIs) for cytology testing. However, WSIs classification with gigapixel resolutions is highly resource-intensive, posing significant challenges for automated medical image analysis. In order to circumvent this computational impasse, existing methods emphasize learning features at the cell or patch level, typically requiring labor-intensive and detailed manual annotations, such as labels at the cell or patch level. Here we propose a novel automated Label-Efficient WSI Screening method, dubbed LESS, for cytology-based diagnosis with only slide-level labels. Firstly, in order to achieve label efficiency, we suggest employing variational positive-unlabeled (VPU) learning, enhancing patch-level feature learning using WSI-level labels. Subsequently, guided by the clinical approach of scrutinizing WSIs at varying fields of view and scales, we employ a cross-attention vision transformer (CrossViT) to fuse multi-scale patch-level data and execute WSI-level classification. We validate the proposed label-efficient method on a urine cytology WSI dataset encompassing 130 samples (13,000 patches) and FNAC 2019 dataset with 212 samples (21,200 patches). The experiment shows that the proposed LESS reaches 84.79%, 85.43%, 91.79% and 78.30% on a urine cytology WSI dataset, and 96.53%, 96.37%, 99.31%, 94.95% on FNAC 2019 dataset in terms of accuracy, AUC, sensitivity and specificity. It outperforms state-of-the-art methods and realizes automatic cytology-based bladder cancer screening.
JEPOO: Highly Accurate Joint Estimation of Pitch, Onset and Offset for Music Information Retrieval
Jun 02, 2023Melody extraction is a core task in music information retrieval, and the estimation of pitch, onset and offset are key sub-tasks in melody extraction. Existing methods have limited accuracy, and work for only one type of data, either single-pitch or multipitch. In this paper, we propose a highly accurate method for joint estimation of pitch, onset and offset, named JEPOO. We address the challenges of joint learning optimization and handling both single-pitch and multi-pitch data through novel model design and a new optimization technique named Pareto modulated loss with loss weight regularization. This is the first method that can accurately handle both single-pitch and multi-pitch music data, and even a mix of them. A comprehensive experimental study on a wide range of real datasets shows that JEPOO outperforms state-ofthe-art methods by up to 10.6%, 8.3% and 10.3% for the prediction of Pitch, Onset and Offset, respectively, and JEPOO is robust for various types of data and instruments. The ablation study shows the effectiveness of each component of JEPOO.
Flexible Job Shop Scheduling via Dual Attention Network Based Reinforcement Learning
May 09, 2023



Flexible manufacturing has given rise to complex scheduling problems such as the flexible job shop scheduling problem (FJSP). In FJSP, operations can be processed on multiple machines, leading to intricate relationships between operations and machines. Recent works have employed deep reinforcement learning (DRL) to learn priority dispatching rules (PDRs) for solving FJSP. However, the quality of solutions still has room for improvement relative to that by the exact methods such as OR-Tools. To address this issue, this paper presents a novel end-to-end learning framework that weds the merits of self-attention models for deep feature extraction and DRL for scalable decision-making. The complex relationships between operations and machines are represented precisely and concisely, for which a dual-attention network (DAN) comprising several interconnected operation message attention blocks and machine message attention blocks is proposed. The DAN exploits the complicated relationships to construct production-adaptive operation and machine features to support high-quality decisionmaking. Experimental results using synthetic data as well as public benchmarks corroborate that the proposed approach outperforms both traditional PDRs and the state-of-the-art DRL method. Moreover, it achieves results comparable to exact methods in certain cases and demonstrates favorable generalization ability to large-scale and real-world unseen FJSP tasks.
Efficient and Robust Time-Optimal Trajectory Planning and Control for Agile Quadrotor Flight
May 04, 2023Agile quadrotor flight relies on rapidly planning and accurately tracking time-optimal trajectories, a technology critical to their application in the wild. However, the computational burden of computing time-optimal trajectories based on the full quadrotor dynamics (typically on the order of minutes or even hours) can hinder its ability to respond quickly to changing scenarios. Additionally, modeling errors and external disturbances can lead to deviations from the desired trajectory during tracking in real time. This letter proposes a novel approach to computing time-optimal trajectories, by fixing the nodes with waypoint constraints and adopting separate sampling intervals for trajectories between waypoints, which significantly accelerates trajectory planning. Furthermore, the planned paths are tracked via a time-adaptive model predictive control scheme whose allocated tracking time can be adaptively adjusted on-the-fly, therefore enhancing the tracking accuracy and robustness. We evaluate our approach through simulations and experimentally validate its performance in dynamic waypoint scenarios for time-optimal trajectory replanning and trajectory tracking.
FedGH: Heterogeneous Federated Learning with Generalized Global Header
Mar 23, 2023Federated learning (FL) is an emerging machine learning paradigm that allows multiple parties to train a shared model collaboratively in a privacy-preserving manner. Existing horizontal FL methods generally assume that the FL server and clients hold the same model structure. However, due to system heterogeneity and the need for personalization, enabling clients to hold models with diverse structures has become an important direction. Existing model-heterogeneous FL approaches often require publicly available datasets and incur high communication and/or computational costs, which limit their performances. To address these limitations, we propose the Federated Global prediction Header (FedGH) approach. It is a communication and computation-efficient model-heterogeneous FL framework which trains a shared generalized global prediction header with representations extracted by heterogeneous extractors for clients' models at the FL server. The trained generalized global prediction header learns from different clients. The acquired global knowledge is then transferred to clients to substitute each client's local prediction header. We derive the non-convex convergence rate of FedGH. Extensive experiments on two real-world datasets demonstrate that FedGH achieves significantly more advantageous performance in both model-homogeneous and -heterogeneous FL scenarios compared to seven state-of-the-art personalized FL models, beating the best-performing baseline by up to 8.87% (for model-homogeneous FL) and 1.83% (for model-heterogeneous FL) in terms of average test accuracy, while saving up to 85.53% of communication overhead.
P-MMF: Provider Max-min Fairness Re-ranking in Recommender System
Mar 12, 2023



In this paper, we address the issue of recommending fairly from the aspect of providers, which has become increasingly essential in multistakeholder recommender systems. Existing studies on provider fairness usually focused on designing proportion fairness (PF) metrics that first consider systematic fairness. However, sociological researches show that to make the market more stable, max-min fairness (MMF) is a better metric. The main reason is that MMF aims to improve the utility of the worst ones preferentially, guiding the system to support the providers in weak market positions. When applying MMF to recommender systems, how to balance user preferences and provider fairness in an online recommendation scenario is still a challenging problem. In this paper, we proposed an online re-ranking model named Provider Max-min Fairness Re-ranking (P-MMF) to tackle the problem. Specifically, P-MMF formulates provider fair recommendation as a resource allocation problem, where the exposure slots are considered the resources to be allocated to providers and the max-min fairness is used as the regularizer during the process. We show that the problem can be further represented as a regularized online optimizing problem and solved efficiently in its dual space. During the online re-ranking phase, a momentum gradient descent method is designed to conduct the dynamic re-ranking. Theoretical analysis showed that the regret of P-MMF can be bounded. Experimental results on four public recommender datasets demonstrated that P-MMF can outperformed the state-of-the-art baselines. Experimental results also show that P-MMF can retain small computationally costs on a corpus with the large number of items.
EdgeYOLO: An Edge-Real-Time Object Detector
Feb 15, 2023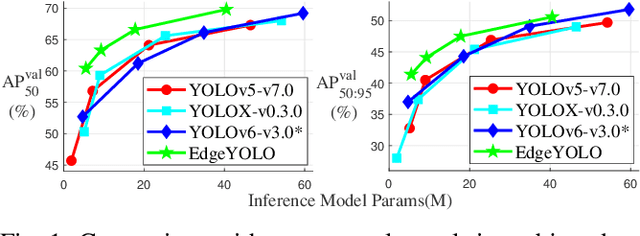
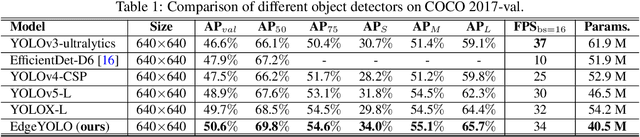

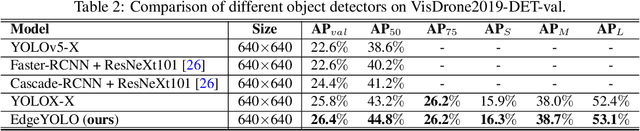
This paper proposes an efficient, low-complexity and anchor-free object detector based on the state-of-the-art YOLO framework, which can be implemented in real time on edge computing platforms. We develop an enhanced data augmentation method to effectively suppress overfitting during training, and design a hybrid random loss function to improve the detection accuracy of small objects. Inspired by FCOS, a lighter and more efficient decoupled head is proposed, and its inference speed can be improved with little loss of precision. Our baseline model can reach the accuracy of 50.6% AP50:95 and 69.8% AP50 in MS COCO2017 dataset, 26.4% AP50:95 and 44.8% AP50 in VisDrone2019-DET dataset, and it meets real-time requirements (FPS>=30) on edge-computing device Nvidia Jetson AGX Xavier. We also designed lighter models with less parameters for edge computing devices with lower computing power, which also show better performances. Our source code, hyper-parameters and model weights are all available at https://github.com/LSH9832/edgeyolo.
Time-attenuating Twin Delayed DDPG Reinforcement Learning for Trajectory Tracking Control of Quadrotors
Feb 13, 2023



Continuous trajectory tracking control of quadrotors is complicated when considering noise from the environment. Due to the difficulty in modeling the environmental dynamics, tracking methodologies based on conventional control theory, such as model predictive control, have limitations on tracking accuracy and response time. We propose a Time-attenuating Twin Delayed DDPG, a model-free algorithm that is robust to noise, to better handle the trajectory tracking task. A deep reinforcement learning framework is constructed, where a time decay strategy is designed to avoid trapping into local optima. The experimental results show that the tracking error is significantly small, and the operation time is one-tenth of that of a traditional algorithm. The OpenAI Mujoco tool is used to verify the proposed algorithm, and the simulation results show that, the proposed method can significantly improve the training efficiency and effectively improve the accuracy and convergence stability.
Minimum Error Entropy Rauch-Tung-Striebel Smoother
Jan 14, 2023Outliers and impulsive disturbances often cause heavy-tailed distributions in practical applications, and these will degrade the performance of Gaussian approximation smoothing algorithms. To improve the robustness of the Rauch-Tung-Striebel (RTS) smother against complicated non-Gaussian noises, a new RTS-smoother integrated with the minimum error entropy (MEE) criterion (MEE-RTS) is proposed for linear systems, which is also extended to the state estimation of nonlinear systems by utilizing the Taylor series linearization approach. The mean error behavior, the mean square error behavior, as well as the computational complexity of the MEE-RTS smoother are analyzed. According to simulation results, the proposed smoothers perform better than several robust solutions in terms of steady-state error.
State Estimation of Wireless Sensor Networks in the Presence of Data Packet Drops and Non-Gaussian Noise
Jan 14, 2023



Distributed Kalman filter approaches based on the maximum correntropy criterion have recently demonstrated superior state estimation performance to that of conventional distributed Kalman filters for wireless sensor networks in the presence of non-Gaussian impulsive noise. However, these algorithms currently fail to take account of data packet drops. The present work addresses this issue by proposing a distributed maximum correntropy Kalman filter that accounts for data packet drops (i.e., the DMCKF-DPD algorithm). The effectiveness and feasibility of the algorithm are verified by simulations conducted in a wireless sensor network with intermittent observations due to data packet drops under a non-Gaussian noise environment. Moreover, the computational complexity of the DMCKF-DPD algorithm is demonstrated to be moderate compared with that of a conventional distributed Kalman filter, and we provide a sufficient condition to ensure the convergence of the proposed algorithm.