 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAL: Regression-Aware Reinforcement Learning for LLM-as-a-Judge
Mar 17, 2026Large language models (LLMs) are increasingly deployed as automated evaluators that assign numeric scores to model outputs, a paradigm known as LLM-as-a-Judge. However, standard Reinforcement Learning (RL) methods typically rely on binary rewards (e.g., 0-1 accuracy), thereby ignoring the ordinal structure inherent in regression tasks; for instance, they fail to recognize that predicting 4 is significantly better than predicting 1 when the ground truth is 5. Conversely, existing regression-aware approaches are often confined to Supervised Fine-Tuning (SFT), limiting their ability to explore optimal reasoning paths. To bridge this gap, we propose \textbf{REAL} (\underline{RE}gression-\underline{A}ware Reinforcement \underline{L}earning), a principled RL framework designed to optimize regression rewards, and also proven to be optimal for correlation metrics. A key technical challenge is that the regression objective is explicitly policy-dependent, thus invalidating standard policy gradient methods. To address this, we employ the generalized policy gradient estimator, which naturally decomposes optimization into two complementary components: (1) exploration over Chain-of-Thought (CoT) trajectory, and (2) regression-aware prediction refinement of the final score. Extensive experiments across model scales (8B to 32B) demonstrate that REAL consistently outperforms both regression-aware SFT baselines and standard RL methods, exhibiting significantly better generalization on out-of-domain benchmarks. On Qwen3-32B specifically, we achieve gains of +8.40 Pearson and +7.20 Spearman correlation over the SFT baseline, and +18.30/+11.20 over the base model. These findings highlight the critical value of integrating regression objectives into RL exploration for accurate LLM evaluation.
Bipartite Ranking From Multiple Labels: On Loss Versus Label Aggregation
Apr 15, 2025
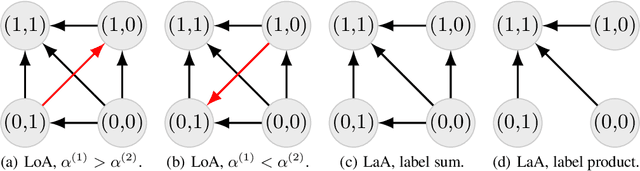

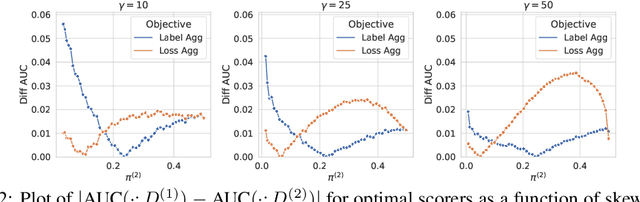
Bipartite ranking is a fundamental supervised learning problem, with the goal of learning a ranking over instances with maximal area under the ROC curve (AUC) against a single binary target label. However, one may often observe multiple binary target labels, e.g., from distinct human annotators. How can one synthesize such labels into a single coherent ranking? In this work, we formally analyze two approaches to this problem -- loss aggregation and label aggregation -- by characterizing their Bayes-optimal solutions. Based on this, we show that while both methods can yield Pareto-optimal solutions, loss aggregation can exhibit label dictatorship: one can inadvertently (and undesirably) favor one label over others. This suggests that label aggregation can be preferable to loss aggregation, which we empirically verify.
TRACT: Regression-Aware Fine-tuning Meets Chain-of-Thought Reasoning for LLM-as-a-Judge
Mar 06, 2025The LLM-as-a-judge paradigm uses large language models (LLMs) for automated text evaluation, where a numerical assessment is assigned by an LLM to the input text following scoring rubrics. Existing methods for LLM-as-a-judge use cross-entropy (CE) loss for fine-tuning, which neglects the numeric nature of score prediction. Recent work addresses numerical prediction limitations of LLM fine-tuning through regression-aware fine-tuning, which, however, does not consider chain-of-thought (CoT) reasoning for score prediction. In this paper, we introduce TRACT (Two-stage Regression-Aware fine-tuning with CoT), a method combining CoT reasoning with regression-aware training. TRACT consists of two stages: first, seed LLM is fine-tuned to generate CoTs, which serve as supervision for the second stage fine-tuning. The training objective of TRACT combines the CE loss for learning the CoT reasoning capabilities, and the regression-aware loss for the score prediction. Experiments across four LLM-as-a-judge datasets and two LLMs show that TRACT significantly outperforms existing methods. Extensive ablation studies validate the importance of each component in TRACT.
Metric-aware LLM inference
Mar 07, 2024Large language models (LLMs) have demonstrated strong results on a range of NLP tasks. Typically, outputs are obtained via autoregressive sampling from the LLM's underlying distribution. We show that this inference strategy can be suboptimal for a range of tasks and associated evaluation metrics. As a remedy, we propose metric aware LLM inference: a decision theoretic approach optimizing for custom metrics at inference time. We report improvements over baselines on academic benchmarks and publicly available models.
It's an Alignment, Not a Trade-off: Revisiting Bias and Variance in Deep Models
Oct 13, 2023



Classical wisdom in machine learning holds that the generalization error can be decomposed into bias and variance, and these two terms exhibit a \emph{trade-off}. However, in this paper, we show that for an ensemble of deep learning based classification models, bias and variance are \emph{aligned} at a sample level, where squared bias is approximately \emph{equal} to variance for correctly classified sample points. We present empirical evidence confirming this phenomenon in a variety of deep learning models and datasets. Moreover, we study this phenomenon from two theoretical perspectives: calibration and neural collapse. We first show theoretically that under the assumption that the models are well calibrated, we can observe the bias-variance alignment. Second, starting from the picture provided by the neural collapse theory, we show an approximate correlation between bias and variance.
What do larger image classifiers memorise?
Oct 09, 2023



The success of modern neural networks has prompted study of the connection between memorisation and generalisation: overparameterised models generalise well, despite being able to perfectly fit (memorise) completely random labels. To carefully study this issue, Feldman proposed a metric to quantify the degree of memorisation of individual training examples, and empirically computed the corresponding memorisation profile of a ResNet on image classification bench-marks. While an exciting first glimpse into what real-world models memorise, this leaves open a fundamental question: do larger neural models memorise more? We present a comprehensive empirical analysis of this question on image classification benchmarks. We find that training examples exhibit an unexpectedly diverse set of memorisation trajectories across model sizes: most samples experience decreased memorisation under larger models, while the rest exhibit cap-shaped or increasing memorisation. We show that various proxies for the Feldman memorization score fail to capture these fundamental trends. Lastly, we find that knowledge distillation, an effective and popular model compression technique, tends to inhibit memorisation, while also improving generalisation. Specifically, memorisation is mostly inhibited on examples with increasing memorisation trajectories, thus pointing at how distillation improves generalisation.
ResMem: Learn what you can and memorize the rest
Feb 03, 2023



The impressive generalization performance of modern neural networks is attributed in part to their ability to implicitly memorize complex training patterns. Inspired by this, we explore a novel mechanism to improve model generalization via explicit memorization. Specifically, we propose the residual-memorization (ResMem) algorithm, a new method that augments an existing prediction model (e.g. a neural network) by fitting the model's residuals with a $k$-nearest neighbor based regressor. The final prediction is then the sum of the original model and the fitted residual regressor. By construction, ResMem can explicitly memorize the training labels. Empirically, we show that ResMem consistently improves the test set generalization of the original prediction model across various standard vision and natural language processing benchmarks. Theoretically, we formulate a stylized linear regression problem and rigorously show that ResMem results in a more favorable test risk over the base predictor.
Large Language Models with Controllable Working Memory
Nov 09, 2022



Large language models (LLMs) have led to a series of breakthroughs in natural language processing (NLP), owing to their excellent understanding and generation abilities. Remarkably, what further sets these models apart is the massive amounts of world knowledge they internalize during pretraining. While many downstream applications provide the model with an informational context to aid its performance on the underlying task, how the model's world knowledge interacts with the factual information presented in the context remains under explored. As a desirable behavior, an LLM should give precedence to the context whenever it contains task-relevant information that conflicts with the model's memorized knowledge. This enables model predictions to be grounded in the context, which can then be used to update or correct specific model predictions without frequent retraining. By contrast, when the context is irrelevant to the task, the model should ignore it and fall back on its internal knowledge. In this paper, we undertake a first joint study of the aforementioned two properties, namely controllability and robustness, in the context of LLMs. We demonstrate that state-of-the-art T5 and PaLM (both pretrained and finetuned) could exhibit poor controllability and robustness, which do not scale with increasing model size. As a solution, we propose a novel method - Knowledge Aware FineTuning (KAFT) - to strengthen both controllability and robustness by incorporating counterfactual and irrelevant contexts to standard supervised datasets. Our comprehensive evaluation showcases the utility of KAFT across model architectures and sizes.
Preserving In-Context Learning ability in Large Language Model Fine-tuning
Nov 01, 2022Pretrained large language models (LLMs) are strong in-context learners that are able to perform few-shot learning without changing model parameters. However, as we show, fine-tuning an LLM on any specific task generally destroys its in-context ability. We discover an important cause of this loss, format specialization, where the model overfits to the format of the fine-tuned task and is unable to output anything beyond this format. We further show that format specialization happens at the beginning of fine-tuning. To solve this problem, we propose Prompt Tuning with MOdel Tuning (ProMoT), a simple yet effective two-stage fine-tuning framework that preserves in-context abilities of the pretrained model. ProMoT first trains a soft prompt for the fine-tuning target task, and then fine-tunes the model itself with this soft prompt attached. ProMoT offloads task-specific formats into the soft prompt that can be removed when doing other in-context tasks. We fine-tune mT5 XXL with ProMoT on natural language inference (NLI) and English-French translation and evaluate the in-context abilities of the resulting models on 8 different NLP tasks. ProMoT achieves similar performance on the fine-tuned tasks compared with vanilla fine-tuning, but with much less reduction of in-context learning performances across the board. More importantly, ProMoT shows remarkable generalization ability on tasks that have different formats, e.g. fine-tuning on a NLI binary classification task improves the model's in-context ability to do summarization (+0.53 Rouge-2 score compared to the pretrained model), making ProMoT a promising method to build general purpose capabilities such as grounding and reasoning into LLMs with small but high quality datasets. When extended to sequential or multi-task training, ProMoT can achieve even better out-of-domain generalization performance.
Robust Distillation for Worst-class Performance
Jun 13, 2022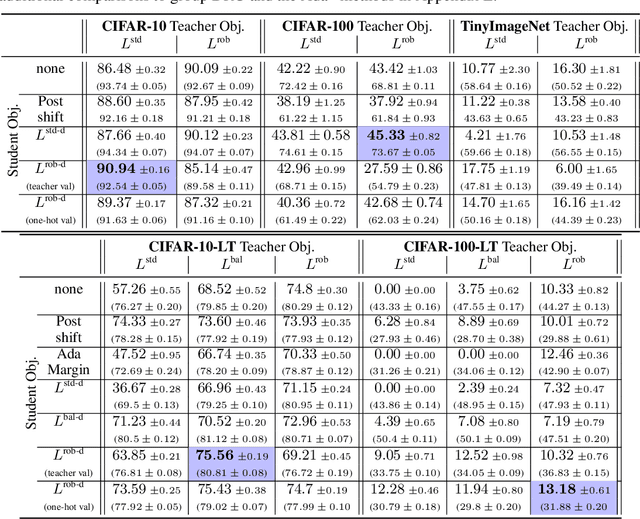
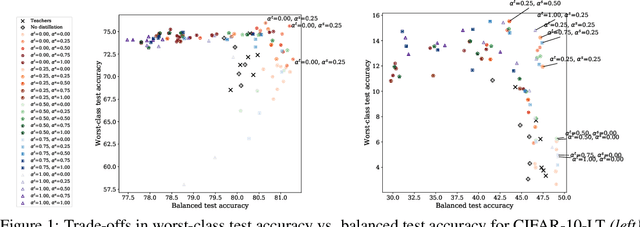
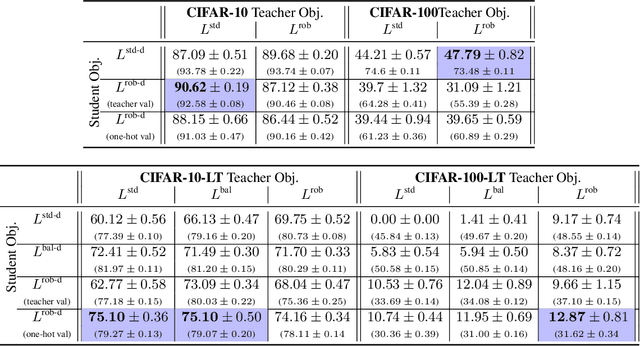
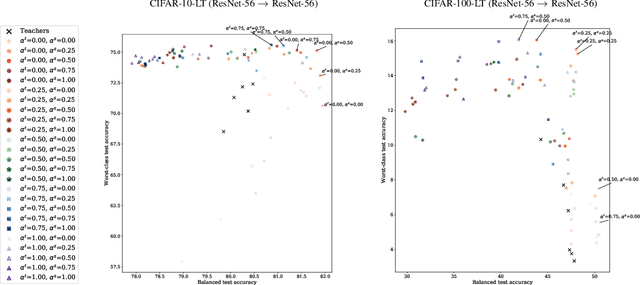
Knowledge distillation has proven to be an effective technique in improving the performance a student model using predictions from a teacher model. However, recent work has shown that gains in average efficiency are not uniform across subgroups in the data, and in particular can often come at the cost of accuracy on rare subgroups and classes. To preserve strong performance across classes that may follow a long-tailed distribution, we develop distillation techniques that are tailored to improve the student's worst-class performance. Specifically, we introduce robust optimization objectives in different combinations for the teacher and student, and further allow for training with any tradeoff between the overall accuracy and the robust worst-class objective. We show empirically that our robust distillation techniques not only achieve better worst-class performance, but also lead to Pareto improvement in the tradeoff between overall performance and worst-class performance compared to other baseline methods. Theoretically, we provide insights into what makes a good teacher when the goal is to train a robust student.