 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Prompt Tuning for Few-shot Text Classification
May 11, 2022
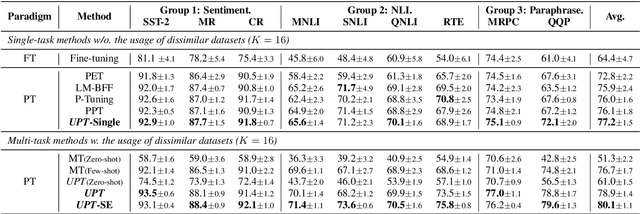
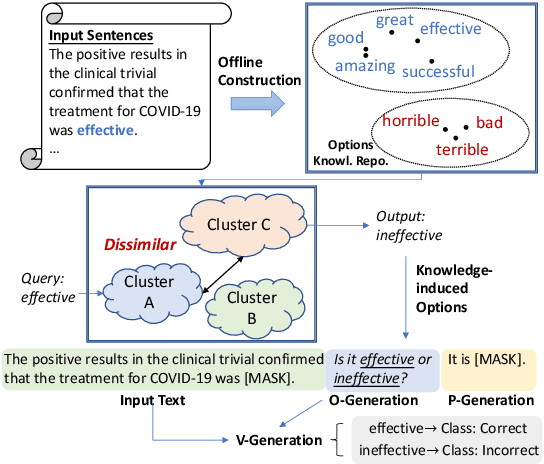
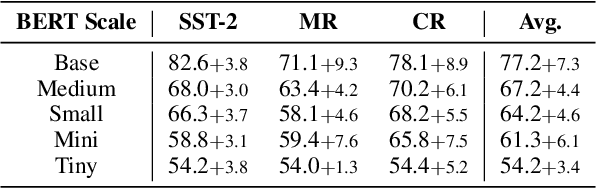
Prompt-based fine-tuning has boosted the performance of Pre-trained Language Models (PLMs) on few-shot text classification by employing task-specific prompts. Yet, PLMs are unfamiliar with prompt-style expressions during pre-training, which limits the few-shot learning performance on downstream tasks. It would be desirable if the models can acquire some prompting knowledge before adaptation to specific NLP tasks. We present the Unified Prompt Tuning (UPT) framework, leading to better few-shot text classification for BERT-style models by explicitly capturing prompting semantics from non-target NLP datasets. In UPT, a novel paradigm Prompt-Options-Verbalizer is proposed for joint prompt learning across different NLP tasks, forcing PLMs to capture task-invariant prompting knowledge. We further design a self-supervised task named Knowledge-enhanced Selective Masked Language Modeling to improve the PLM's generalization abilities for accurate adaptation to previously unseen tasks. After multi-task learning across multiple tasks, the PLM can be better prompt-tuned towards any dissimilar target tasks in low-resourced settings. Experiments over a variety of NLP tasks show that UPT consistently outperforms state-of-the-arts for prompt-based fine-tuning.
On Effectively Learning of Knowledge in Continual Pre-training
Apr 17, 2022
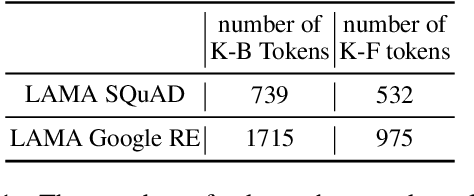
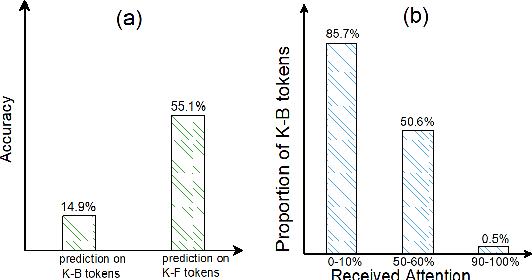

Pre-trained language models (PLMs) like BERT have made significant progress in various downstream NLP tasks. However, by asking models to do cloze-style tests, recent work finds that PLMs are short in acquiring knowledge from unstructured text. To understand the internal behaviour of PLMs in retrieving knowledge, we first define knowledge-baring (K-B) tokens and knowledge-free (K-F) tokens for unstructured text and ask professional annotators to label some samples manually. Then, we find that PLMs are more likely to give wrong predictions on K-B tokens and attend less attention to those tokens inside the self-attention module. Based on these observations, we develop two solutions to help the model learn more knowledge from unstructured text in a fully self-supervised manner. Experiments on knowledge-intensive tasks show the effectiveness of the proposed methods. To our best knowledge, we are the first to explore fully self-supervised learning of knowledge in continual pre-training.
Probing Structured Pruning on Multilingual Pre-trained Models: Settings, Algorithms, and Efficiency
Apr 06, 2022
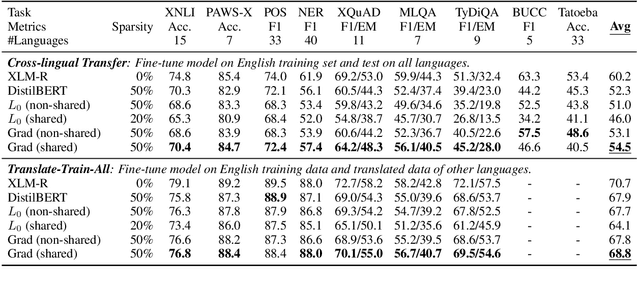
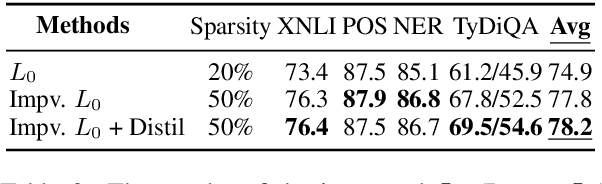
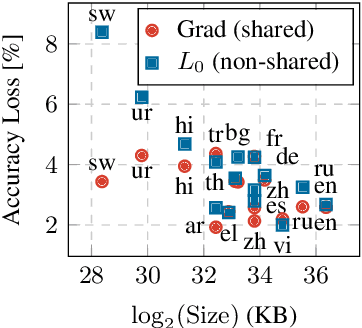
Structured pruning has been extensively studied on monolingual pre-trained language models and is yet to be fully evaluated on their multilingual counterparts. This work investigates three aspects of structured pruning on multilingual pre-trained language models: settings, algorithms, and efficiency. Experiments on nine downstream tasks show several counter-intuitive phenomena: for settings, individually pruning for each language does not induce a better result; for algorithms, the simplest method performs the best; for efficiency, a fast model does not imply that it is also small. To facilitate the comparison on all sparsity levels, we present Dynamic Sparsification, a simple approach that allows training the model once and adapting to different model sizes at inference. We hope this work fills the gap in the study of structured pruning on multilingual pre-trained models and sheds light on future research.
Making Pre-trained Language Models End-to-end Few-shot Learners with Contrastive Prompt Tuning
Apr 01, 2022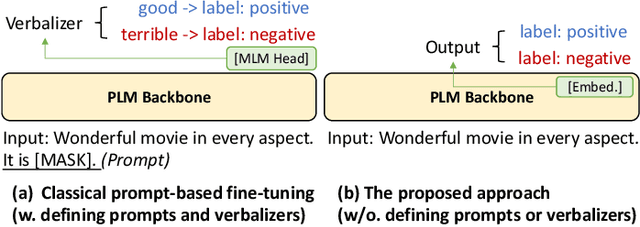

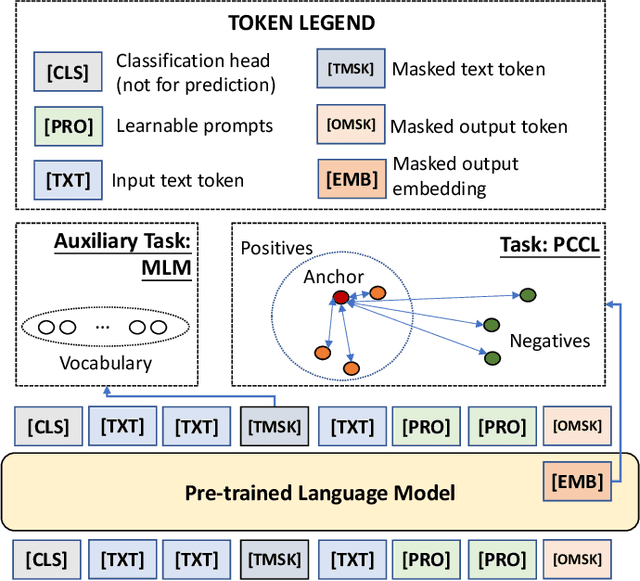
Pre-trained Language Models (PLMs) have achieved remarkable performance for various language understanding tasks in IR systems, which require the fine-tuning process based on labeled training data. For low-resource scenarios, prompt-based learning for PLMs exploits prompts as task guidance and turns downstream tasks into masked language problems for effective few-shot fine-tuning. In most existing approaches, the high performance of prompt-based learning heavily relies on handcrafted prompts and verbalizers, which may limit the application of such approaches in real-world scenarios. To solve this issue, we present CP-Tuning, the first end-to-end Contrastive Prompt Tuning framework for fine-tuning PLMs without any manual engineering of task-specific prompts and verbalizers. It is integrated with the task-invariant continuous prompt encoding technique with fully trainable prompt parameters. We further propose the pair-wise cost-sensitive contrastive learning procedure to optimize the model in order to achieve verbalizer-free class mapping and enhance the task-invariance of prompts. It explicitly learns to distinguish different classes and makes the decision boundary smoother by assigning different costs to easy and hard cases. Experiments over a variety of language understanding tasks used in IR systems and different PLMs show that CP-Tuning outperforms state-of-the-art methods.
From Dense to Sparse: Contrastive Pruning for Better Pre-trained Language Model Compression
Dec 14, 2021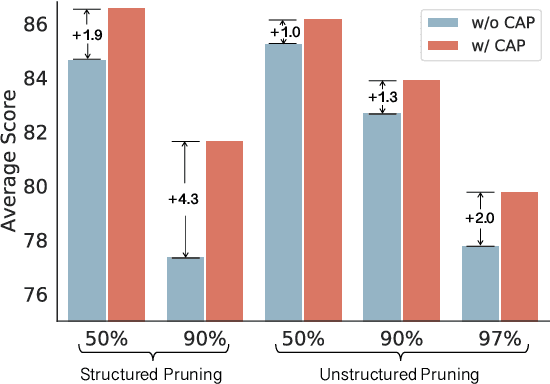
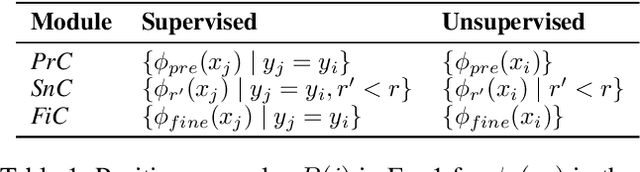
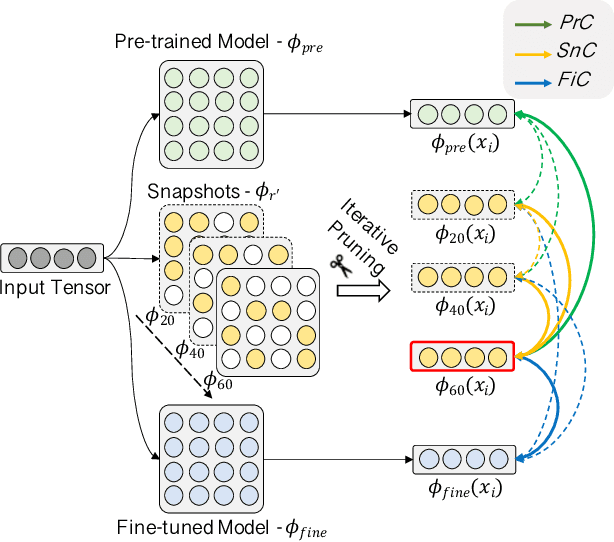
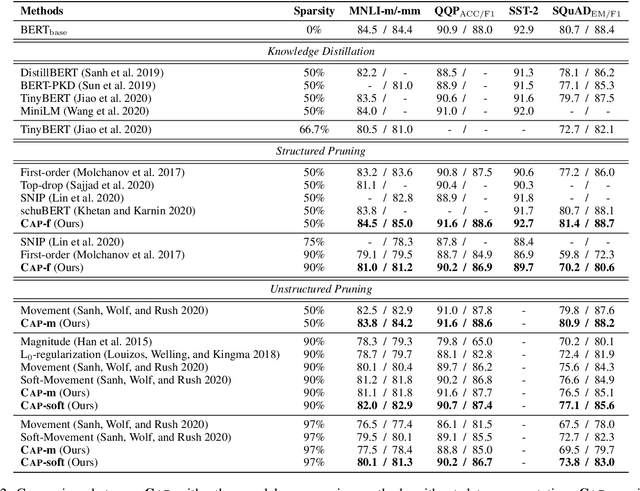
Pre-trained Language Models (PLMs) have achieved great success in various Natural Language Processing (NLP) tasks under the pre-training and fine-tuning paradigm. With large quantities of parameters, PLMs are computation-intensive and resource-hungry. Hence, model pruning has been introduced to compress large-scale PLMs. However, most prior approaches only consider task-specific knowledge towards downstream tasks, but ignore the essential task-agnostic knowledge during pruning, which may cause catastrophic forgetting problem and lead to poor generalization ability. To maintain both task-agnostic and task-specific knowledge in our pruned model, we propose ContrAstive Pruning (CAP) under the paradigm of pre-training and fine-tuning. It is designed as a general framework, compatible with both structured and unstructured pruning. Unified in contrastive learning, CAP enables the pruned model to learn from the pre-trained model for task-agnostic knowledge, and fine-tuned model for task-specific knowledge. Besides, to better retain the performance of the pruned model, the snapshots (i.e., the intermediate models at each pruning iteration) also serve as effective supervisions for pruning. Our extensive experiments show that adopting CAP consistently yields significant improvements, especially in extremely high sparsity scenarios. With only 3% model parameters reserved (i.e., 97% sparsity), CAP successfully achieves 99.2% and 96.3% of the original BERT performance in QQP and MNLI tasks. In addition, our probing experiments demonstrate that the model pruned by CAP tends to achieve better generalization ability.
Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning
Sep 13, 2021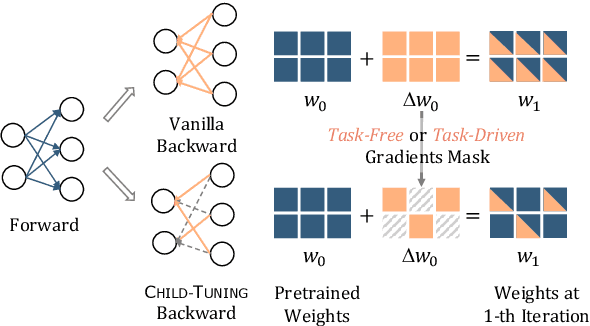
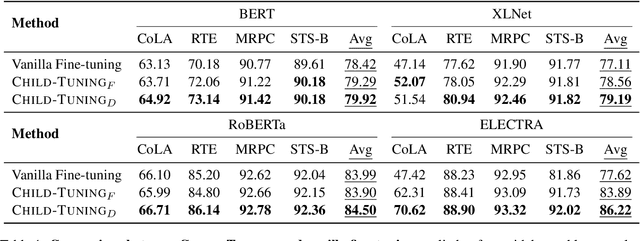
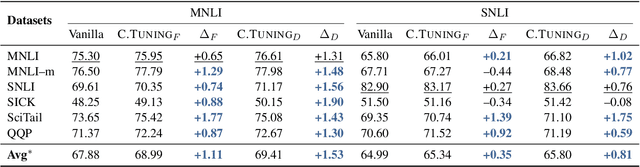
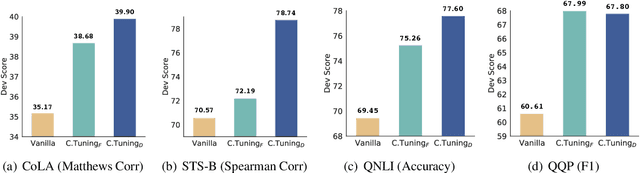
Recent pretrained language models extend from millions to billions of parameters. Thus the need to fine-tune an extremely large pretrained model with a limited training corpus arises in various downstream tasks. In this paper, we propose a straightforward yet effective fine-tuning technique, Child-Tuning, which updates a subset of parameters (called child network) of large pretrained models via strategically masking out the gradients of the non-child network during the backward process. Experiments on various downstream tasks in GLUE benchmark show that Child-Tuning consistently outperforms the vanilla fine-tuning by 1.5~8.6 average score among four different pretrained models, and surpasses the prior fine-tuning techniques by 0.6~1.3 points. Furthermore, empirical results on domain transfer and task transfer show that Child-Tuning can obtain better generalization performance by large margins.
SemVLP: Vision-Language Pre-training by Aligning Semantics at Multiple Levels
Mar 14, 2021
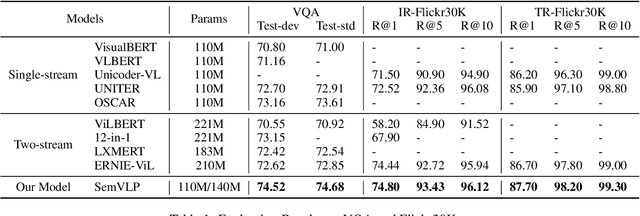
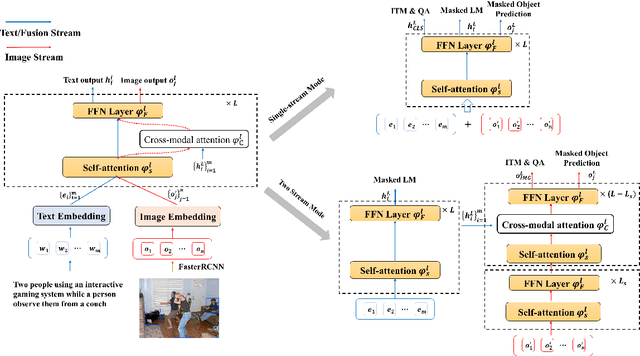

Vision-language pre-training (VLP) on large-scale image-text pairs has recently witnessed rapid progress for learning cross-modal representations. Existing pre-training methods either directly concatenate image representation and text representation at a feature level as input to a single-stream Transformer, or use a two-stream cross-modal Transformer to align the image-text representation at a high-level semantic space. In real-world image-text data, we observe that it is easy for some of the image-text pairs to align simple semantics on both modalities, while others may be related after higher-level abstraction. Therefore, in this paper, we propose a new pre-training method SemVLP, which jointly aligns both the low-level and high-level semantics between image and text representations. The model is pre-trained iteratively with two prevalent fashions: single-stream pre-training to align at a fine-grained feature level and two-stream pre-training to align high-level semantics, by employing a shared Transformer network with a pluggable cross-modal attention module. An extensive set of experiments have been conducted on four well-established vision-language understanding tasks to demonstrate the effectiveness of the proposed SemVLP in aligning cross-modal representations towards different semantic granularities.
CAPT: Contrastive Pre-Training for Learning Denoised Sequence Representations
Oct 30, 2020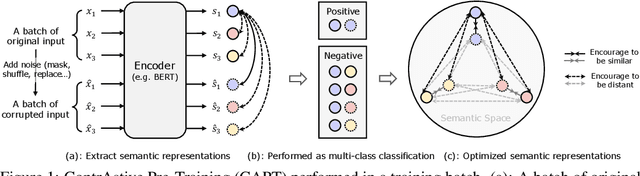
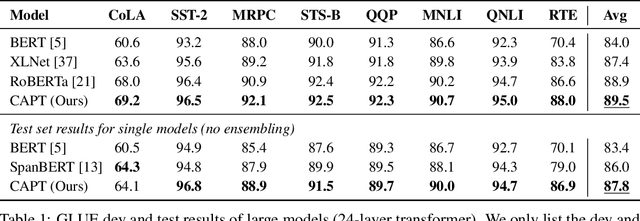
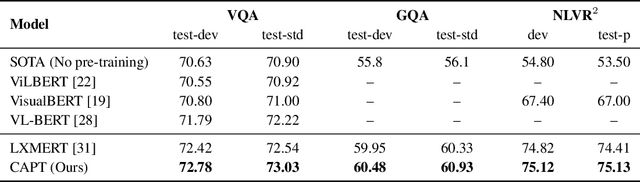
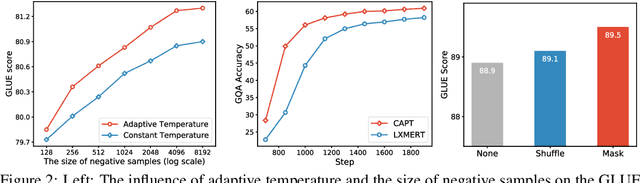
Pre-trained self-supervised models such as BERT have achieved striking success in learning sequence representations, especially for natural language processing. These models typically corrupt the given sequences with certain types of noise, such as masking, shuffling, or substitution, and then try to recover the original input. However, such pre-training approaches are prone to learning representations that are covariant with the noise, leading to the discrepancy between the pre-training and fine-tuning stage. To remedy this, we present ContrAstive Pre-Training (CAPT) to learn noise invariant sequence representations. The proposed CAPT encourages the consistency between representations of the original sequence and its corrupted version via unsupervised instance-wise training signals. In this way, it not only alleviates the pretrain-finetune discrepancy induced by the noise of pre-training, but also aids the pre-trained model in better capturing global semantics of the input via more effective sentence-level supervision. Different from most prior work that focuses on a particular modality, comprehensive empirical evidence on 11 natural language understanding and cross-modal tasks illustrates that CAPT is applicable for both language and vision-language tasks, and obtains surprisingly consistent improvement, including 0.6\% absolute gain on GLUE benchmarks and 0.8\% absolute increment on $\text{NLVR}^2$.
VECO: Variable Encoder-decoder Pre-training for Cross-lingual Understanding and Generation
Oct 30, 2020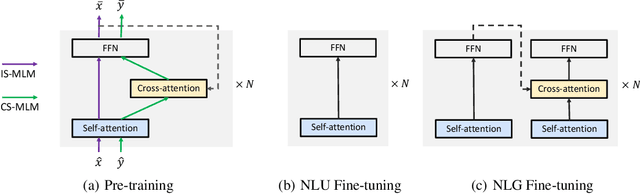
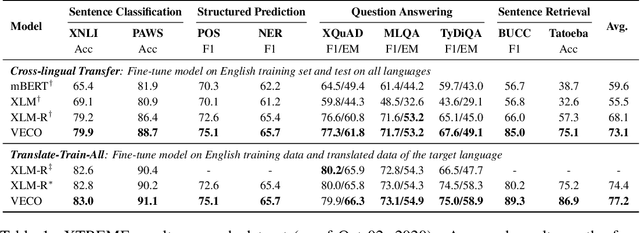

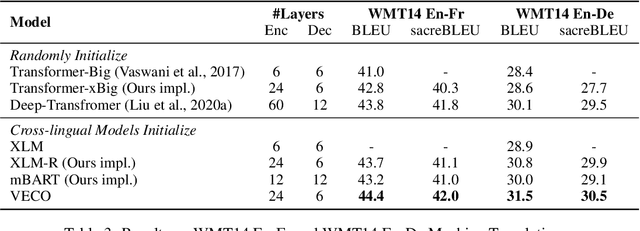
Recent studies about learning multilingual representations have achieved significant performance gains across a wide range of downstream cross-lingual tasks. They train either an encoder-only Transformer mainly for understanding tasks, or an encoder-decoder Transformer specifically for generation tasks, ignoring the correlation between the two tasks and frameworks. In contrast, this paper presents a variable encoder-decoder (VECO) pre-training approach to unify the two mainstreams in both model architectures and pre-training tasks. VECO splits the standard Transformer block into several sub-modules trained with both inner-sequence and cross-sequence masked language modeling, and correspondingly reorganizes certain sub-modules for understanding and generation tasks during inference. Such a workflow not only ensures to train the most streamlined parameters necessary for two kinds of tasks, but also enables them to boost each other via sharing common sub-modules. As a result, VECO delivers new state-of-the-art results on various cross-lingual understanding tasks of the XTREME benchmark covering text classification, sequence labeling, question answering, and sentence retrieval. For generation tasks, VECO also outperforms all existing cross-lingual models and state-of-the-art Transformer variants on WMT14 English-to-German and English-to-French translation datasets, with gains of up to 1$\sim$2 BLEU.
Inductively Representing Out-of-Knowledge-Graph Entities by Optimal Estimation Under Translational Assumptions
Sep 27, 2020
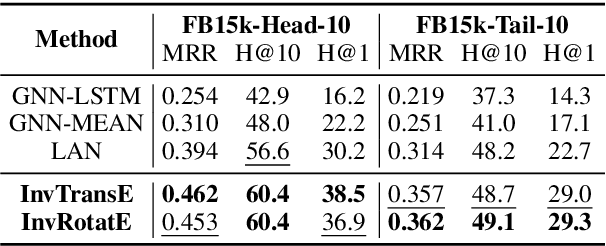
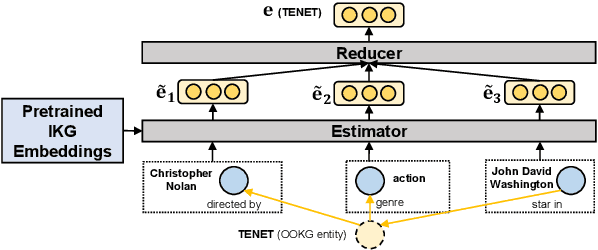
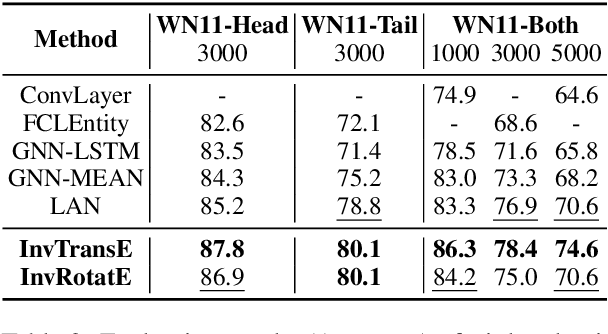
Conventional Knowledge Graph Completion (KGC) assumes that all test entities appear during training. However, in real-world scenarios, Knowledge Graphs (KG) evolve fast with out-of-knowledge-graph (OOKG) entities added frequently, and we need to represent these entities efficiently. Most existing Knowledge Graph Embedding (KGE) methods cannot represent OOKG entities without costly retraining on the whole KG. To enhance efficiency, we propose a simple and effective method that inductively represents OOKG entities by their optimal estimation under translational assumptions. Given pretrained embeddings of the in-knowledge-graph (IKG) entities, our method needs no additional learning. Experimental results show that our method outperforms the state-of-the-art methods with higher efficiency on two KGC tasks with OOKG entities.