 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning over Different Types of Knowledge Graphs: Static, Temporal and Multi-Modal
Dec 21, 2022



Knowledge graph reasoning (KGR), aiming to deduce new facts from existing facts based on mined logic rules underlying knowledge graphs (KGs), has become a fast-growing research direction. It has been proven to significantly benefit the usage of KGs in many AI applications, such as question answering and recommendation systems, etc. According to the graph types, the existing KGR models can be roughly divided into three categories, i.e., static models, temporal models, and multi-modal models. The early works in this domain mainly focus on static KGR and tend to directly apply general knowledge graph embedding models to the reasoning task. However, these models are not suitable for more complex but practical tasks, such as inductive static KGR, temporal KGR, and multi-modal KGR. To this end, multiple works have been developed recently, but no survey papers and open-source repositories comprehensively summarize and discuss models in this important direction. To fill the gap, we conduct a survey for knowledge graph reasoning tracing from static to temporal and then to multi-modal KGs. Concretely, the preliminaries, summaries of KGR models, and typical datasets are introduced and discussed consequently. Moreover, we discuss the challenges and potential opportunities. The corresponding open-source repository is shared on GitHub: https://github.com/LIANGKE23/Awesome-Knowledge-Graph-Reasoning.
Recognizing Object by Components with Human Prior Knowledge Enhances Adversarial Robustness of Deep Neural Networks
Dec 04, 2022Adversarial attacks can easily fool object recognition systems based on deep neural networks (DNNs). Although many defense methods have been proposed in recent years, most of them can still be adaptively evaded. One reason for the weak adversarial robustness may be that DNNs are only supervised by category labels and do not have part-based inductive bias like the recognition process of humans. Inspired by a well-known theory in cognitive psychology -- recognition-by-components, we propose a novel object recognition model ROCK (Recognizing Object by Components with human prior Knowledge). It first segments parts of objects from images, then scores part segmentation results with predefined human prior knowledge, and finally outputs prediction based on the scores. The first stage of ROCK corresponds to the process of decomposing objects into parts in human vision. The second stage corresponds to the decision process of the human brain. ROCK shows better robustness than classical recognition models across various attack settings. These results encourage researchers to rethink the rationality of currently widely-used DNN-based object recognition models and explore the potential of part-based models, once important but recently ignored, for improving robustness.
SRTNet: Time Domain Speech Enhancement Via Stochastic Refinement
Oct 30, 2022



Diffusion model, as a new generative model which is very popular in image generation and audio synthesis, is rarely used in speech enhancement. In this paper, we use the diffusion model as a module for stochastic refinement. We propose SRTNet, a novel method for speech enhancement via Stochastic Refinement in complete Time domain. Specifically, we design a joint network consisting of a deterministic module and a stochastic module, which makes up the ``enhance-and-refine'' paradigm. We theoretically demonstrate the feasibility of our method and experimentally prove that our method achieves faster training, faster sampling and higher quality. Our code and enhanced samples are available at https://github.com/zhibinQiu/SRTNet.git.
Learning 6-DoF Task-oriented Grasp Detection via Implicit Estimation and Visual Affordance
Oct 16, 2022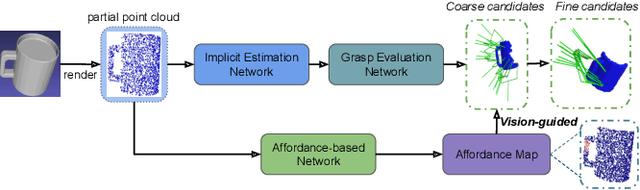

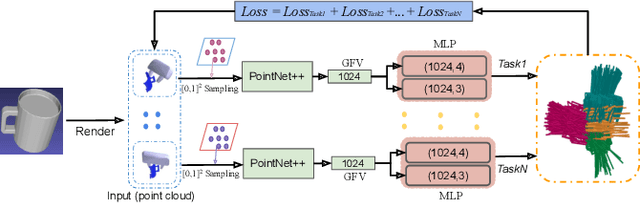
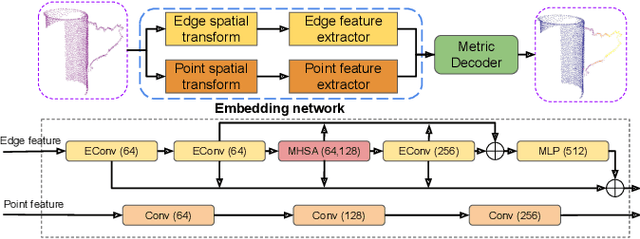
Currently, task-oriented grasp detection approaches are mostly based on pixel-level affordance detection and semantic segmentation. These pixel-level approaches heavily rely on the accuracy of a 2D affordance mask, and the generated grasp candidates are restricted to a small workspace. To mitigate these limitations, we first construct a novel affordance-based grasp dataset and propose a 6-DoF task-oriented grasp detection framework, which takes the observed object point cloud as input and predicts diverse 6-DoF grasp poses for different tasks. Specifically, our implicit estimation network and visual affordance network in this framework could directly predict coarse grasp candidates, and corresponding 3D affordance heatmap for each potential task, respectively. Furthermore, the grasping scores from coarse grasps are combined with heatmap values to generate more accurate and finer candidates. Our proposed framework shows significant improvements compared to baselines for existing and novel objects on our simulation dataset. Although our framework is trained based on the simulated objects and environment, the final generated grasp candidates can be accurately and stably executed in real robot experiments when the object is randomly placed on a support surface.
When to Update Your Model: Constrained Model-based Reinforcement Learning
Oct 15, 2022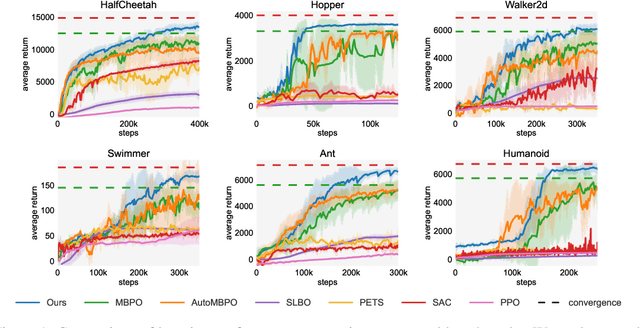

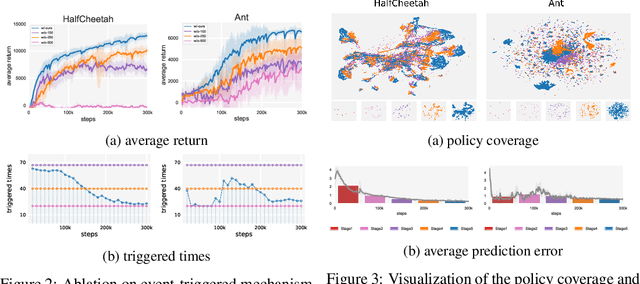
Designing and analyzing model-based RL (MBRL) algorithms with guaranteed monotonic improvement has been challenging, mainly due to the interdependence between policy optimization and model learning. Existing discrepancy bounds generally ignore the impacts of model shifts, and their corresponding algorithms are prone to degrade performance by drastic model updating. In this work, we first propose a novel and general theoretical scheme for a non-decreasing performance guarantee of MBRL. Our follow-up derived bounds reveal the relationship between model shifts and performance improvement. These discoveries encourage us to formulate a constrained lower-bound optimization problem to permit the monotonicity of MBRL. A further example demonstrates that learning models from a dynamically-varying number of explorations benefit the eventual returns. Motivated by these analyses, we design a simple but effective algorithm CMLO (Constrained Model-shift Lower-bound Optimization), by introducing an event-triggered mechanism that flexibly determines when to update the model. Experiments show that CMLO surpasses other state-of-the-art methods and produces a boost when various policy optimization methods are employed.
Pay Self-Attention to Audio-Visual Navigation
Oct 05, 2022
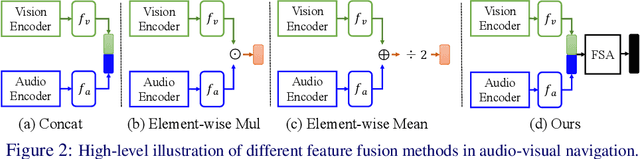
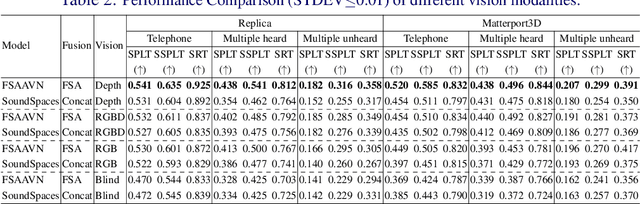
Audio-visual embodied navigation, as a hot research topic, aims training a robot to reach an audio target using egocentric visual (from the sensors mounted on the robot) and audio (emitted from the target) input. The audio-visual information fusion strategy is naturally important to the navigation performance, but the state-of-the-art methods still simply concatenate the visual and audio features, potentially ignoring the direct impact of context. Moreover, the existing approaches requires either phase-wise training or additional aid (e.g. topology graph and sound semantics). Up till this date, the work that deals with the more challenging setup with moving target(s) is still rare. As a result, we propose an end-to-end framework FSAAVN (feature self-attention audio-visual navigation) to learn chasing after a moving audio target using a context-aware audio-visual fusion strategy implemented as a self-attention module. Our thorough experiments validate the superior performance (both quantitatively and qualitatively) of FSAAVN in comparison with the state-of-the-arts, and also provide unique insights about the choice of visual modalities, visual/audio encoder backbones and fusion patterns.
Bridged Transformer for Vision and Point Cloud 3D Object Detection
Oct 04, 2022

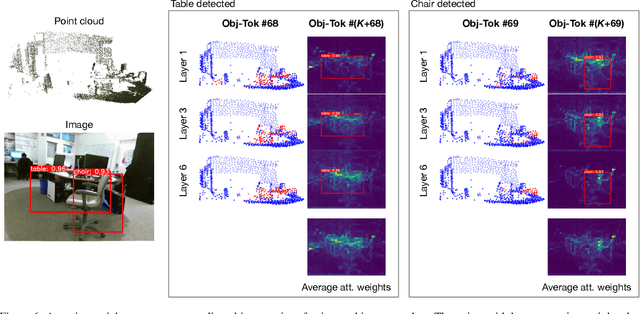
3D object detection is a crucial research topic in computer vision, which usually uses 3D point clouds as input in conventional setups. Recently, there is a trend of leveraging multiple sources of input data, such as complementing the 3D point cloud with 2D images that often have richer color and fewer noises. However, due to the heterogeneous geometrics of the 2D and 3D representations, it prevents us from applying off-the-shelf neural networks to achieve multimodal fusion. To that end, we propose Bridged Transformer (BrT), an end-to-end architecture for 3D object detection. BrT is simple and effective, which learns to identify 3D and 2D object bounding boxes from both points and image patches. A key element of BrT lies in the utilization of object queries for bridging 3D and 2D spaces, which unifies different sources of data representations in Transformer. We adopt a form of feature aggregation realized by point-to-patch projections which further strengthen the correlations between images and points. Moreover, BrT works seamlessly for fusing the point cloud with multi-view images. We experimentally show that BrT surpasses state-of-the-art methods on SUN RGB-D and ScanNetV2 datasets.
Disentangle and Remerge: Interventional Knowledge Distillation for Few-Shot Object Detection from A Conditional Causal Perspective
Aug 26, 2022
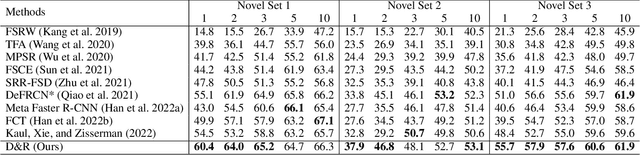
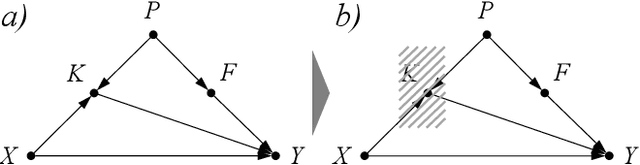
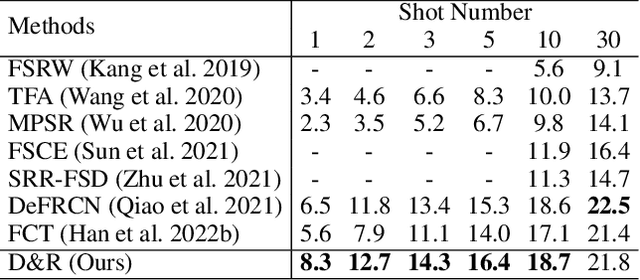
Few-shot learning models learn representations with limited human annotations, and such a learning paradigm demonstrates practicability in various tasks, e.g., image classification, object detection, etc. However, few-shot object detection methods suffer from an intrinsic defect that the limited training data makes the model cannot sufficiently explore semantic information. To tackle this, we introduce knowledge distillation to the few-shot object detection learning paradigm. We further run a motivating experiment, which demonstrates that in the process of knowledge distillation the empirical error of the teacher model degenerates the prediction performance of the few-shot object detection model, as the student. To understand the reasons behind this phenomenon, we revisit the learning paradigm of knowledge distillation on the few-shot object detection task from the causal theoretic standpoint, and accordingly, develop a Structural Causal Model. Following the theoretical guidance, we propose a backdoor adjustment-based knowledge distillation method for the few-shot object detection task, namely Disentangle and Remerge (D&R), to perform conditional causal intervention toward the corresponding Structural Causal Model. Theoretically, we provide an extended definition, i.e., general backdoor path, for the backdoor criterion, which can expand the theoretical application boundary of the backdoor criterion in specific cases. Empirically, the experiments on multiple benchmark datasets demonstrate that D&R can yield significant performance boosts in few-shot object detection.
Robust Causal Graph Representation Learning against Confounding Effects
Aug 18, 2022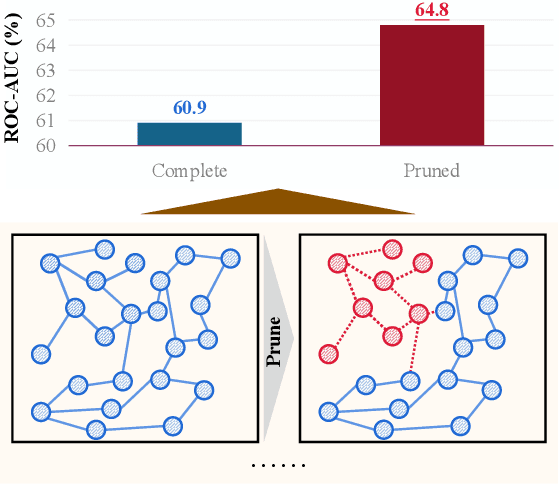
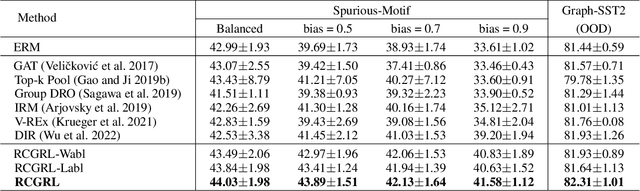
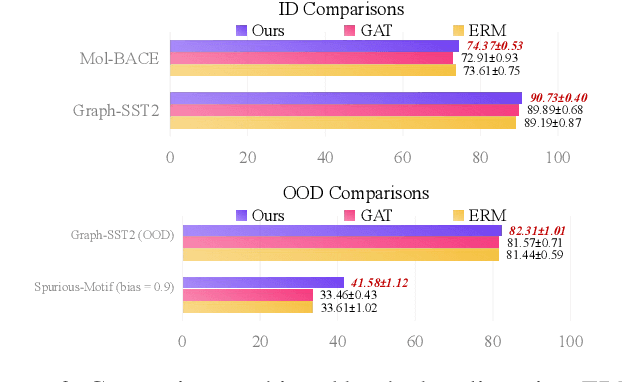
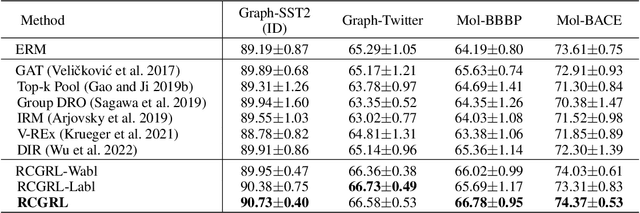
The prevailing graph neural network models have achieved significant progress in graph representation learning. However, in this paper, we uncover an ever-overlooked phenomenon: the pre-trained graph representation learning model tested with full graphs underperforms the model tested with well-pruned graphs. This observation reveals that there exist confounders in graphs, which may interfere with the model learning semantic information, and current graph representation learning methods have not eliminated their influence. To tackle this issue, we propose Robust Causal Graph Representation Learning (RCGRL) to learn robust graph representations against confounding effects. RCGRL introduces an active approach to generate instrumental variables under unconditional moment restrictions, which empowers the graph representation learning model to eliminate confounders, thereby capturing discriminative information that is causally related to downstream predictions. We offer theorems and proofs to guarantee the theoretical effectiveness of the proposed approach. Empirically, we conduct extensive experiments on a synthetic dataset and multiple benchmark datasets. The results demonstrate that compared with state-of-the-art methods, RCGRL achieves better prediction performance and generalization ability.
Scene Graph for Embodied Exploration in Cluttered Scenario
Jul 16, 2022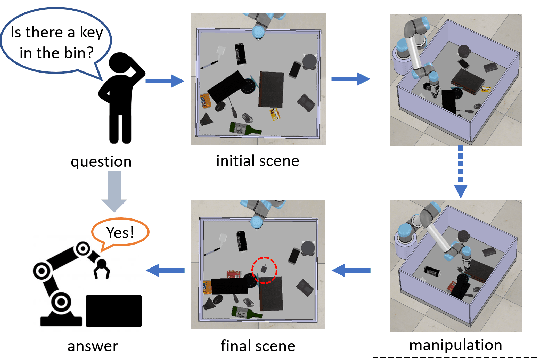
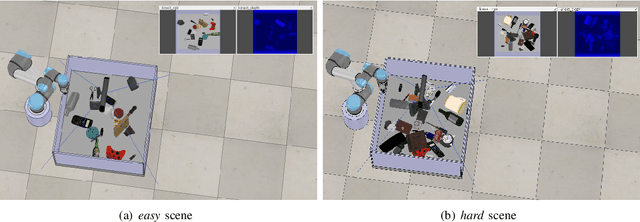
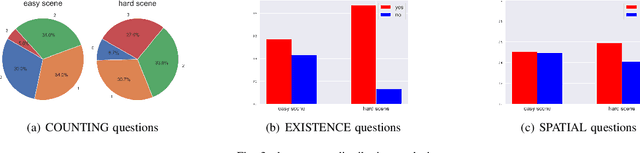
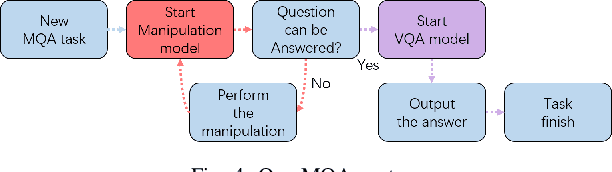
The ability to handle objects in cluttered environment has been long anticipated by robotic community. However, most of works merely focus on manipulation instead of rendering hidden semantic information in cluttered objects. In this work, we introduce the scene graph for embodied exploration in cluttered scenarios to solve this problem. To validate our method in cluttered scenario, we adopt the Manipulation Question Answering (MQA) tasks as our test benchmark, which requires an embodied robot to have the active exploration ability and semantic understanding ability of vision and language.As a general solution framework to the task, we propose an imitation learning method to generate manipulations for exploration. Meanwhile, a VQA model based on dynamic scene graph is adopted to comprehend a series of RGB frames from wrist camera of manipulator along with every step of manipulation is conducted to answer questions in our framework.The experiments on of MQA dataset with different interaction requirements demonstrate that our proposed framework is effective for MQA task a representative of tasks in cluttered scenario.