 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Language Model Evolution: An Iterated Learning Perspective
Apr 04, 2024



With the widespread adoption of Large Language Models (LLMs), the prevalence of iterative interactions among these models is anticipated to increase. Notably, recent advancements in multi-round self-improving methods allow LLMs to generate new examples for training subsequent models. At the same time, multi-agent LLM systems, involving automated interactions among agents, are also increasing in prominence. Thus, in both short and long terms, LLMs may actively engage in an evolutionary process. We draw parallels between the behavior of LLMs and the evolution of human culture, as the latter has been extensively studied by cognitive scientists for decades. Our approach involves leveraging Iterated Learning (IL), a Bayesian framework that elucidates how subtle biases are magnified during human cultural evolution, to explain some behaviors of LLMs. This paper outlines key characteristics of agents' behavior in the Bayesian-IL framework, including predictions that are supported by experimental verification with various LLMs. This theoretical framework could help to more effectively predict and guide the evolution of LLMs in desired directions.
Direct Language Model Alignment from Online AI Feedback
Feb 07, 2024



Direct alignment from preferences (DAP) methods, such as DPO, have recently emerged as efficient alternatives to reinforcement learning from human feedback (RLHF), that do not require a separate reward model. However, the preference datasets used in DAP methods are usually collected ahead of training and never updated, thus the feedback is purely offline. Moreover, responses in these datasets are often sampled from a language model distinct from the one being aligned, and since the model evolves over training, the alignment phase is inevitably off-policy. In this study, we posit that online feedback is key and improves DAP methods. Our method, online AI feedback (OAIF), uses an LLM as annotator: on each training iteration, we sample two responses from the current model and prompt the LLM annotator to choose which one is preferred, thus providing online feedback. Despite its simplicity, we demonstrate via human evaluation in several tasks that OAIF outperforms both offline DAP and RLHF methods. We further show that the feedback leveraged in OAIF is easily controllable, via instruction prompts to the LLM annotator.
Decoding-time Realignment of Language Models
Feb 05, 2024Aligning language models with human preferences is crucial for reducing errors and biases in these models. Alignment techniques, such as reinforcement learning from human feedback (RLHF), are typically cast as optimizing a tradeoff between human preference rewards and a proximity regularization term that encourages staying close to the unaligned model. Selecting an appropriate level of regularization is critical: insufficient regularization can lead to reduced model capabilities due to reward hacking, whereas excessive regularization hinders alignment. Traditional methods for finding the optimal regularization level require retraining multiple models with varying regularization strengths. This process, however, is resource-intensive, especially for large models. To address this challenge, we propose decoding-time realignment (DeRa), a simple method to explore and evaluate different regularization strengths in aligned models without retraining. DeRa enables control over the degree of alignment, allowing users to smoothly transition between unaligned and aligned models. It also enhances the efficiency of hyperparameter tuning by enabling the identification of effective regularization strengths using a validation dataset.
ICED: Zero-Shot Transfer in Reinforcement Learning via In-Context Environment Design
Feb 05, 2024Autonomous agents trained using deep reinforcement learning (RL) often lack the ability to successfully generalise to new environments, even when they share characteristics with the environments they have encountered during training. In this work, we investigate how the sampling of individual environment instances, or levels, affects the zero-shot generalisation (ZSG) ability of RL agents. We discover that, for deep actor-critic architectures sharing their base layers, prioritising levels according to their value loss minimises the mutual information between the agent's internal representation and the set of training levels in the generated training data. This provides a novel theoretical justification for the implicit regularisation achieved by certain adaptive sampling strategies. We then turn our attention to unsupervised environment design (UED) methods, which have more control over the data generation mechanism. We find that existing UED methods can significantly shift the training distribution, which translates to low ZSG performance. To prevent both overfitting and distributional shift, we introduce in-context environment design (ICED). ICED generates levels using a variational autoencoder trained over an initial set of level parameters, reducing distributional shift, and achieves significant improvements in ZSG over adaptive level sampling strategies and UED methods.
Sample Relationship from Learning Dynamics Matters for Generalisation
Jan 16, 2024



Although much research has been done on proposing new models or loss functions to improve the generalisation of artificial neural networks (ANNs), less attention has been directed to the impact of the training data on generalisation. In this work, we start from approximating the interaction between samples, i.e. how learning one sample would modify the model's prediction on other samples. Through analysing the terms involved in weight updates in supervised learning, we find that labels influence the interaction between samples. Therefore, we propose the labelled pseudo Neural Tangent Kernel (lpNTK) which takes label information into consideration when measuring the interactions between samples. We first prove that lpNTK asymptotically converges to the empirical neural tangent kernel in terms of the Frobenius norm under certain assumptions. Secondly, we illustrate how lpNTK helps to understand learning phenomena identified in previous work, specifically the learning difficulty of samples and forgetting events during learning. Moreover, we also show that using lpNTK to identify and remove poisoning training samples does not hurt the generalisation performance of ANNs.
How the level sampling process impacts zero-shot generalisation in deep reinforcement learning
Oct 05, 2023



A key limitation preventing the wider adoption of autonomous agents trained via deep reinforcement learning (RL) is their limited ability to generalise to new environments, even when these share similar characteristics with environments encountered during training. In this work, we investigate how a non-uniform sampling strategy of individual environment instances, or levels, affects the zero-shot generalisation (ZSG) ability of RL agents, considering two failure modes: overfitting and over-generalisation. As a first step, we measure the mutual information (MI) between the agent's internal representation and the set of training levels, which we find to be well-correlated to instance overfitting. In contrast to uniform sampling, adaptive sampling strategies prioritising levels based on their value loss are more effective at maintaining lower MI, which provides a novel theoretical justification for this class of techniques. We then turn our attention to unsupervised environment design (UED) methods, which adaptively generate new training levels and minimise MI more effectively than methods sampling from a fixed set. However, we find UED methods significantly shift the training distribution, resulting in over-generalisation and worse ZSG performance over the distribution of interest. To prevent both instance overfitting and over-generalisation, we introduce self-supervised environment design (SSED). SSED generates levels using a variational autoencoder, effectively reducing MI while minimising the shift with the distribution of interest, and leads to statistically significant improvements in ZSG over fixed-set level sampling strategies and UED methods.
How to prepare your task head for finetuning
Feb 11, 2023In deep learning, transferring information from a pretrained network to a downstream task by finetuning has many benefits. The choice of task head plays an important role in fine-tuning, as the pretrained and downstream tasks are usually different. Although there exist many different designs for finetuning, a full understanding of when and why these algorithms work has been elusive. We analyze how the choice of task head controls feature adaptation and hence influences the downstream performance. By decomposing the learning dynamics of adaptation, we find that the key aspect is the training accuracy and loss at the beginning of finetuning, which determines the "energy" available for the feature's adaptation. We identify a significant trend in the effect of changes in this initial energy on the resulting features after fine-tuning. Specifically, as the energy increases, the Euclidean and cosine distances between the resulting and original features increase, while their dot products (and the resulting features' norm) first increase and then decrease. Inspired by this, we give several practical principles that lead to better downstream performance. We analytically prove this trend in an overparamterized linear setting and verify its applicability to different experimental settings.
Deep Reinforcement Learning for Multi-Agent Interaction
Aug 02, 2022The development of autonomous agents which can interact with other agents to accomplish a given task is a core area of research in artificial intelligence and machine learning. Towards this goal, the Autonomous Agents Research Group develops novel machine learning algorithms for autonomous systems control, with a specific focus on deep reinforcement learning and multi-agent reinforcement learning. Research problems include scalable learning of coordinated agent policies and inter-agent communication; reasoning about the behaviours, goals, and composition of other agents from limited observations; and sample-efficient learning based on intrinsic motivation, curriculum learning, causal inference, and representation learning. This article provides a broad overview of the ongoing research portfolio of the group and discusses open problems for future directions.
Smoothing Matters: Momentum Transformer for Domain Adaptive Semantic Segmentation
Mar 15, 2022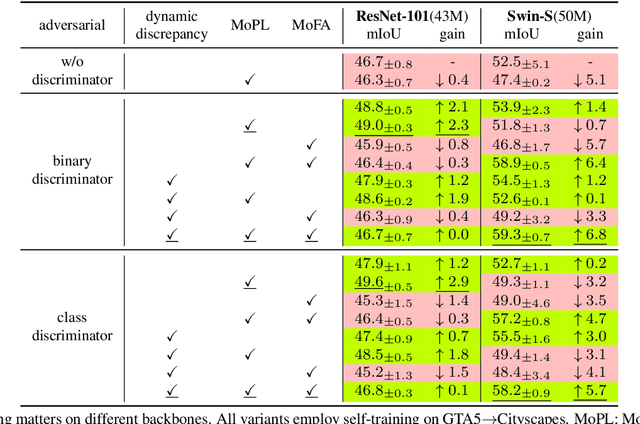
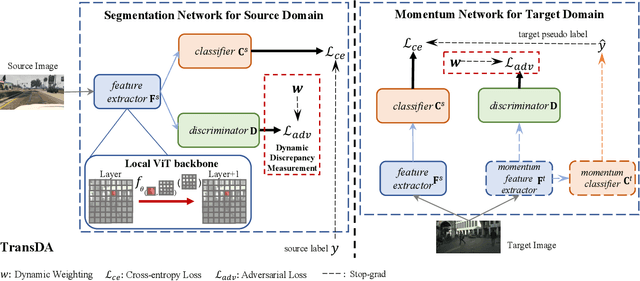

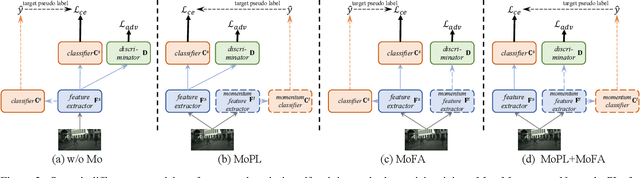
After the great success of Vision Transformer variants (ViTs) in computer vision, it has also demonstrated great potential in domain adaptive semantic segmentation. Unfortunately, straightforwardly applying local ViTs in domain adaptive semantic segmentation does not bring in expected improvement. We find that the pitfall of local ViTs is due to the severe high-frequency components generated during both the pseudo-label construction and features alignment for target domains. These high-frequency components make the training of local ViTs very unsmooth and hurt their transferability. In this paper, we introduce a low-pass filtering mechanism, momentum network, to smooth the learning dynamics of target domain features and pseudo labels. Furthermore, we propose a dynamic of discrepancy measurement to align the distributions in the source and target domains via dynamic weights to evaluate the importance of the samples. After tackling the above issues, extensive experiments on sim2real benchmarks show that the proposed method outperforms the state-of-the-art methods. Our codes are available at https://github.com/alpc91/TransDA