 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022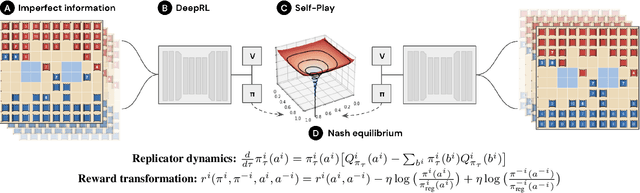
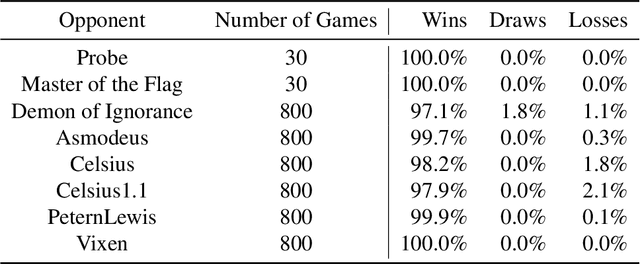
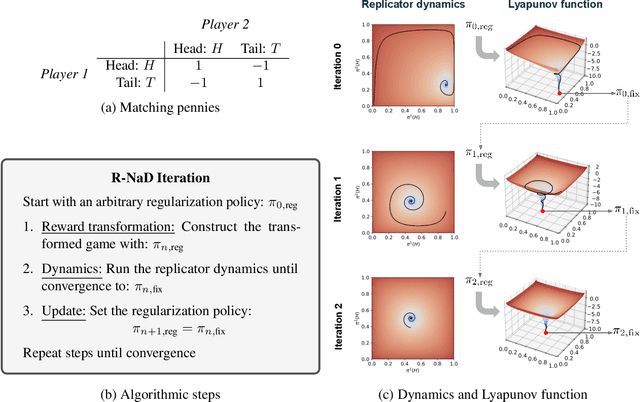

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Emergent Bartering Behaviour in Multi-Agent Reinforcement Learning
May 13, 2022
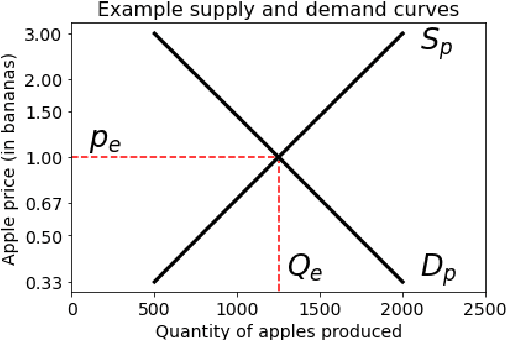
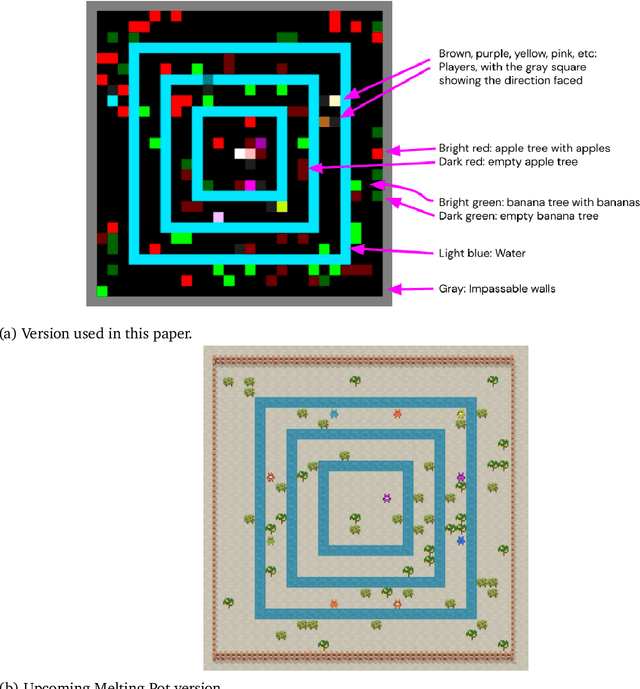

Advances in artificial intelligence often stem from the development of new environments that abstract real-world situations into a form where research can be done conveniently. This paper contributes such an environment based on ideas inspired by elementary Microeconomics. Agents learn to produce resources in a spatially complex world, trade them with one another, and consume those that they prefer. We show that the emergent production, consumption, and pricing behaviors respond to environmental conditions in the directions predicted by supply and demand shifts in Microeconomics. We also demonstrate settings where the agents' emergent prices for goods vary over space, reflecting the local abundance of goods. After the price disparities emerge, some agents then discover a niche of transporting goods between regions with different prevailing prices -- a profitable strategy because they can buy goods where they are cheap and sell them where they are expensive. Finally, in a series of ablation experiments, we investigate how choices in the environmental rewards, bartering actions, agent architecture, and ability to consume tradable goods can either aid or inhibit the emergence of this economic behavior. This work is part of the environment development branch of a research program that aims to build human-like artificial general intelligence through multi-agent interactions in simulated societies. By exploring which environment features are needed for the basic phenomena of elementary microeconomics to emerge automatically from learning, we arrive at an environment that differs from those studied in prior multi-agent reinforcement learning work along several dimensions. For example, the model incorporates heterogeneous tastes and physical abilities, and agents negotiate with one another as a grounded form of communication.
Reward-Respecting Subtasks for Model-Based Reinforcement Learning
Feb 09, 2022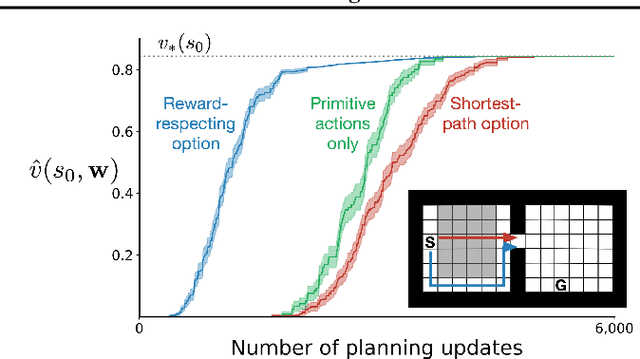
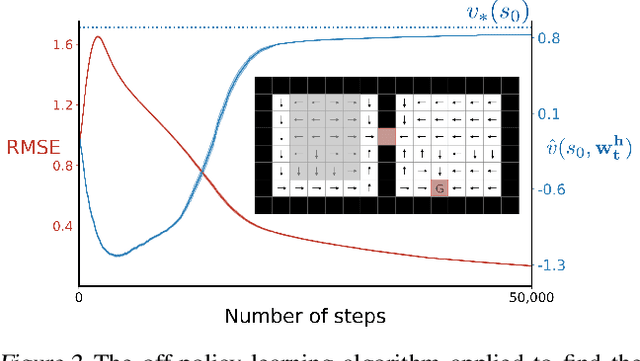
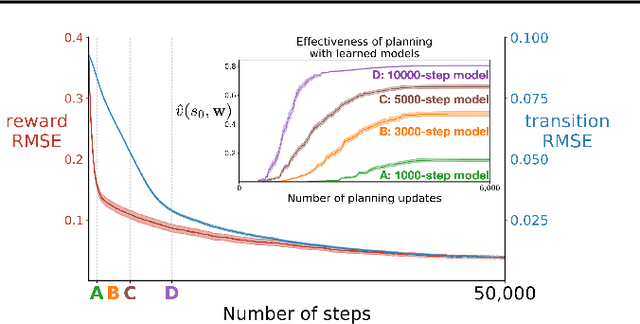
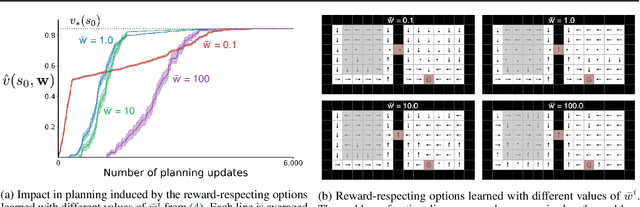
To achieve the ambitious goals of artificial intelligence, reinforcement learning must include planning with a model of the world that is abstract in state and time. Deep learning has made progress in state abstraction, but, although the theory of time abstraction has been extensively developed based on the options framework, in practice options have rarely been used in planning. One reason for this is that the space of possible options is immense and the methods previously proposed for option discovery do not take into account how the option models will be used in planning. Options are typically discovered by posing subsidiary tasks such as reaching a bottleneck state, or maximizing a sensory signal other than the reward. Each subtask is solved to produce an option, and then a model of the option is learned and made available to the planning process. The subtasks proposed in most previous work ignore the reward on the original problem, whereas we propose subtasks that use the original reward plus a bonus based on a feature of the state at the time the option stops. We show that options and option models obtained from such reward-respecting subtasks are much more likely to be useful in planning and can be learned online and off-policy using existing learning algorithms. Reward respecting subtasks strongly constrain the space of options and thereby also provide a partial solution to the problem of option discovery. Finally, we show how the algorithms for learning values, policies, options, and models can be unified using general value functions.
Player of Games
Dec 06, 2021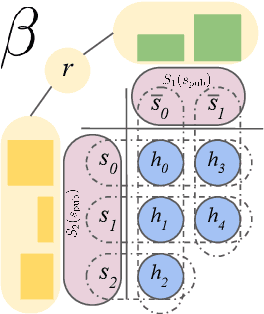

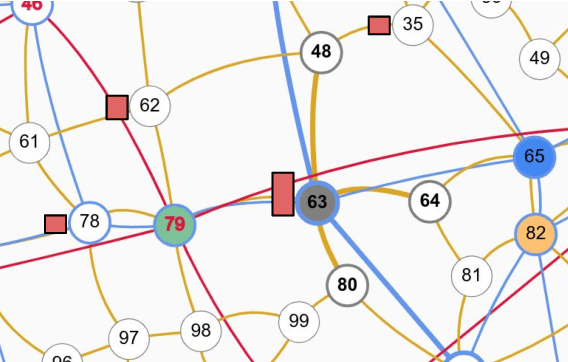
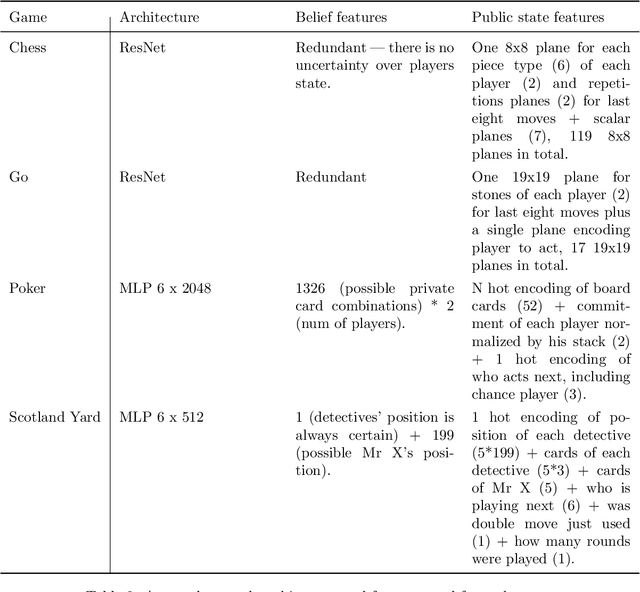
Games have a long history of serving as a benchmark for progress in artificial intelligence. Recently, approaches using search and learning have shown strong performance across a set of perfect information games, and approaches using game-theoretic reasoning and learning have shown strong performance for specific imperfect information poker variants. We introduce Player of Games, a general-purpose algorithm that unifies previous approaches, combining guided search, self-play learning, and game-theoretic reasoning. Player of Games is the first algorithm to achieve strong empirical performance in large perfect and imperfect information games -- an important step towards truly general algorithms for arbitrary environments. We prove that Player of Games is sound, converging to perfect play as available computation time and approximation capacity increases. Player of Games reaches strong performance in chess and Go, beats the strongest openly available agent in heads-up no-limit Texas hold'em poker (Slumbot), and defeats the state-of-the-art agent in Scotland Yard, an imperfect information game that illustrates the value of guided search, learning, and game-theoretic reasoning.
Solving Common-Payoff Games with Approximate Policy Iteration
Jan 11, 2021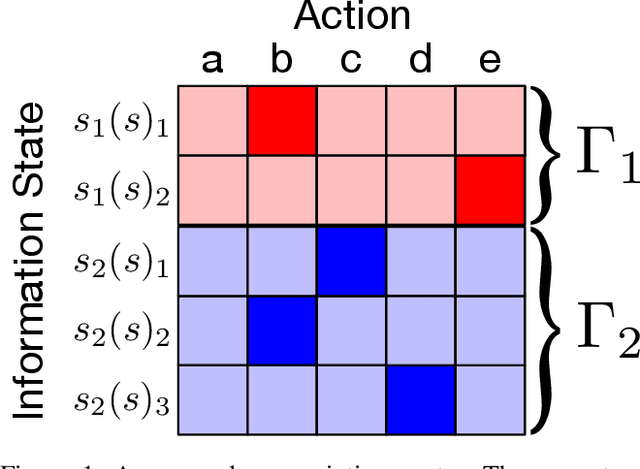
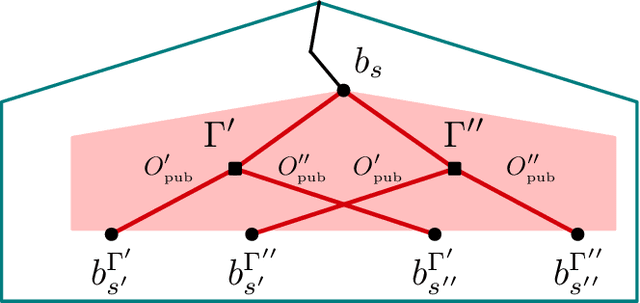
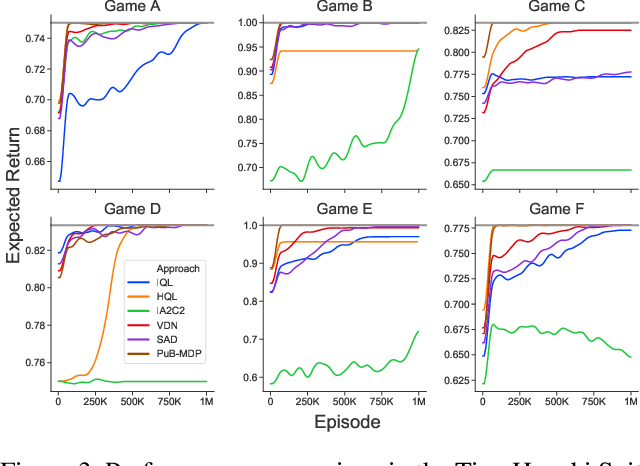
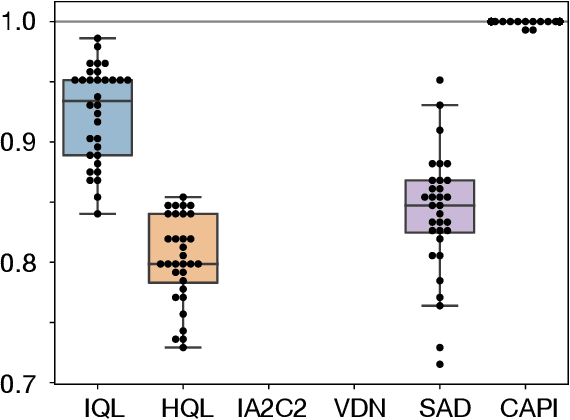
For artificially intelligent learning systems to have widespread applicability in real-world settings, it is important that they be able to operate decentrally. Unfortunately, decentralized control is difficult -- computing even an epsilon-optimal joint policy is a NEXP complete problem. Nevertheless, a recently rediscovered insight -- that a team of agents can coordinate via common knowledge -- has given rise to algorithms capable of finding optimal joint policies in small common-payoff games. The Bayesian action decoder (BAD) leverages this insight and deep reinforcement learning to scale to games as large as two-player Hanabi. However, the approximations it uses to do so prevent it from discovering optimal joint policies even in games small enough to brute force optimal solutions. This work proposes CAPI, a novel algorithm which, like BAD, combines common knowledge with deep reinforcement learning. However, unlike BAD, CAPI prioritizes the propensity to discover optimal joint policies over scalability. While this choice precludes CAPI from scaling to games as large as Hanabi, empirical results demonstrate that, on the games to which CAPI does scale, it is capable of discovering optimal joint policies even when other modern multi-agent reinforcement learning algorithms are unable to do so. Code is available at https://github.com/ssokota/capi .
The Advantage Regret-Matching Actor-Critic
Aug 27, 2020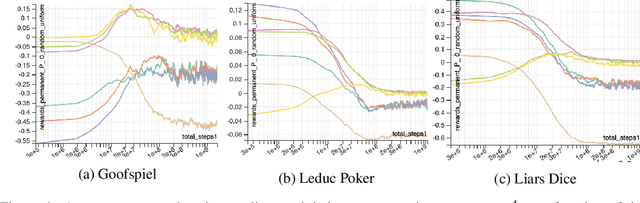
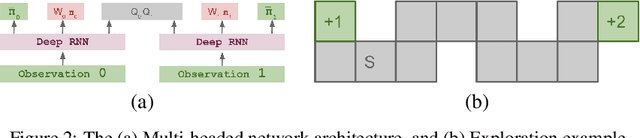
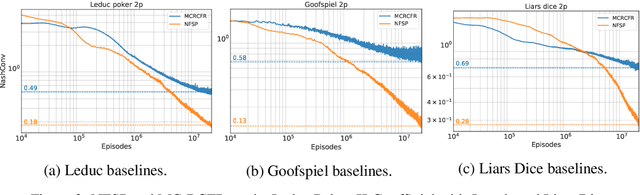
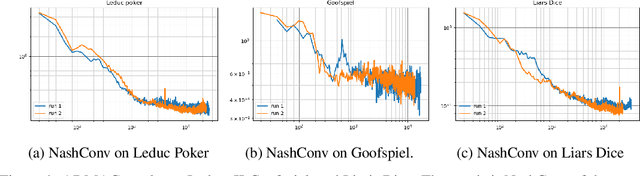
Regret minimization has played a key role in online learning, equilibrium computation in games, and reinforcement learning (RL). In this paper, we describe a general model-free RL method for no-regret learning based on repeated reconsideration of past behavior. We propose a model-free RL algorithm, the AdvantageRegret-Matching Actor-Critic (ARMAC): rather than saving past state-action data, ARMAC saves a buffer of past policies, replaying through them to reconstruct hindsight assessments of past behavior. These retrospective value estimates are used to predict conditional advantages which, combined with regret matching, produces a new policy. In particular, ARMAC learns from sampled trajectories in a centralized training setting, without requiring the application of importance sampling commonly used in Monte Carlo counterfactual regret (CFR) minimization; hence, it does not suffer from excessive variance in large environments. In the single-agent setting, ARMAC shows an interesting form of exploration by keeping past policies intact. In the multiagent setting, ARMAC in self-play approaches Nash equilibria on some partially-observable zero-sum benchmarks. We provide exploitability estimates in the significantly larger game of betting-abstracted no-limit Texas Hold'em.
Approximate exploitability: Learning a best response in large games
Apr 20, 2020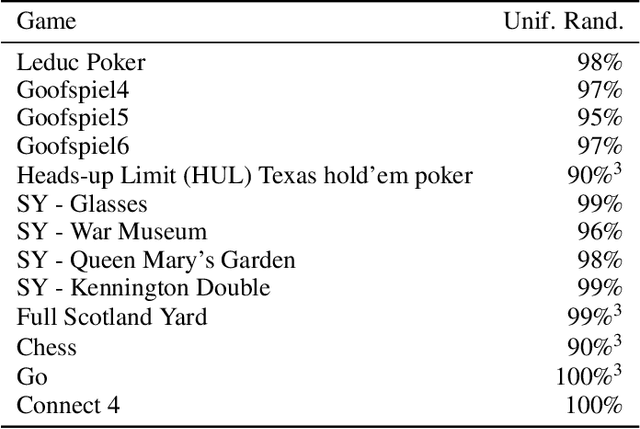
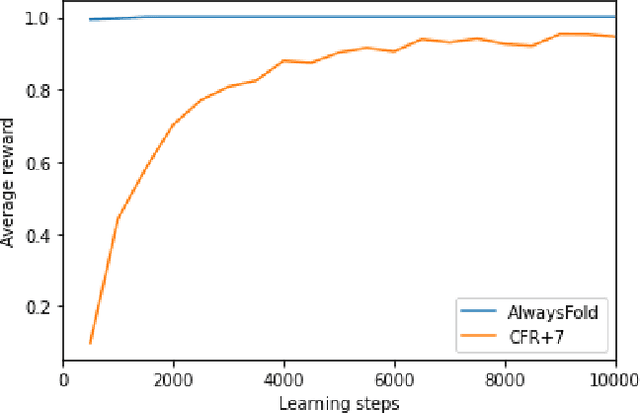

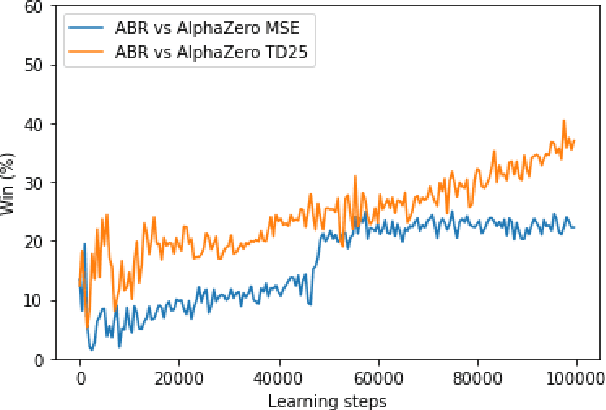
A common metric in games of imperfect information is exploitability, i.e. the performance of a policy against the worst-case opponent. This metric has many nice properties, but is intractable to compute in large games as it requires a full search of the game tree to calculate a best response to the given policy. We introduce a new metric, approximate exploitability, that calculates an analogous metric to exploitability using an approximate best response. This method scales to large games with tractable belief spaces. We focus only on the two-player, zero-sum case. Additionally, we provide empirical results for a specific instance of the method, demonstrating that it can effectively exploit agents in large games. We demonstrate that our method converges to exploitability in the tabular setting and the function approximation setting for small games, and demonstrate that it can consistently find exploits for weak policies in large games, showing results on Chess, Go, Heads-up No Limit Texas Hold'em, and other games.
OpenSpiel: A Framework for Reinforcement Learning in Games
Oct 10, 2019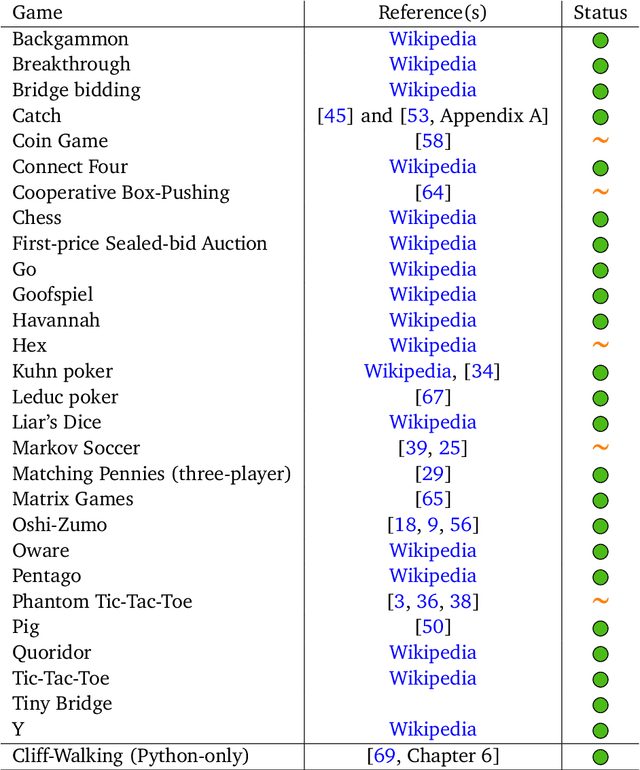
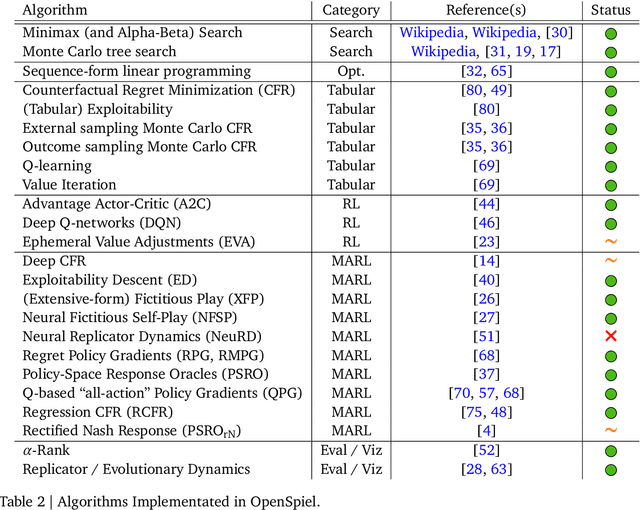
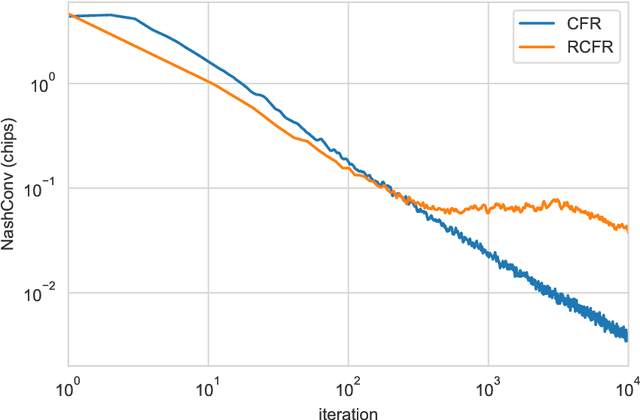
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. This document serves both as an overview of the code base and an introduction to the terminology, core concepts, and algorithms across the fields of reinforcement learning, computational game theory, and search.
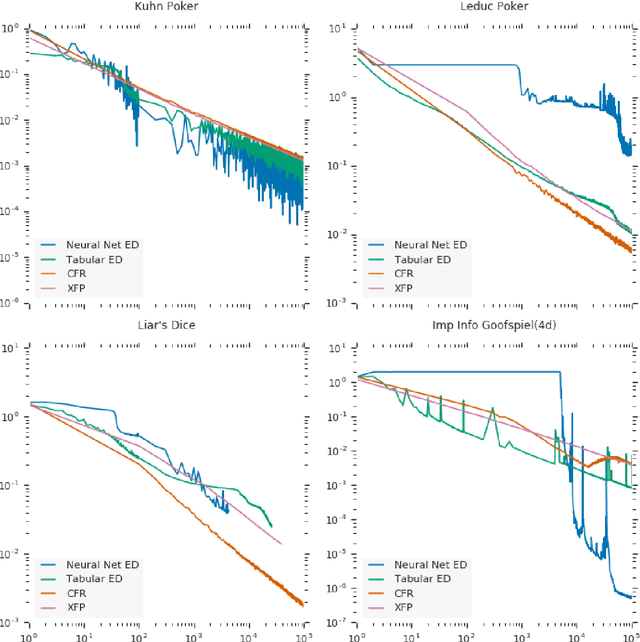
Computing Approximate Equilibria in Sequential Adversarial Games by Exploitability Descent
Mar 21, 2019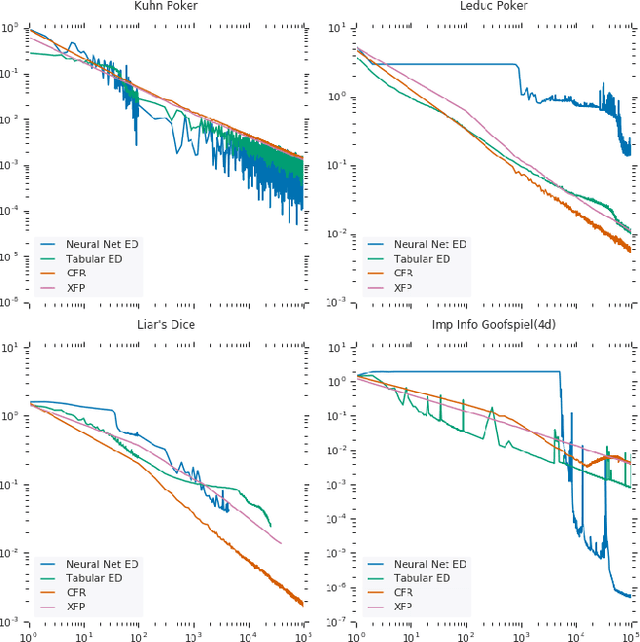
In this paper, we present exploitability descent, a new algorithm to compute approximate equilibria in two-player zero-sum extensive-form games with imperfect information, by direct policy optimization against worst-case opponents. We prove that when following this optimization, the exploitability of a player's strategy converges asymptotically to zero, and hence when both players employ this optimization, the joint policies converge to a Nash equilibrium. Unlike fictitious play (XFP) and counterfactual regret minimization (CFR), our convergence result pertains to the policies being optimized rather than the average policies. Our experiments demonstrate convergence rates comparable to XFP and CFR in four benchmark games in the tabular case. Using function approximation, we find that our algorithm outperforms the tabular version in two of the games, which, to the best of our knowledge, is the first such result in imperfect information games among this class of algorithms.