 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Agents That Reason About Their Computation
Oct 26, 2025While reinforcement learning agents can achieve superhuman performance in many complex tasks, they typically do not become more computationally efficient as they improve. In contrast, humans gradually require less cognitive effort as they become more proficient at a task. If agents could reason about their compute as they learn, could they similarly reduce their computation footprint? If they could, we could have more energy efficient agents or free up compute cycles for other processes like planning. In this paper, we experiment with showing agents the cost of their computation and giving them the ability to control when they use compute. We conduct our experiments on the Arcade Learning Environment, and our results demonstrate that with the same training compute budget, agents that reason about their compute perform better on 75% of games. Furthermore, these agents use three times less compute on average. We analyze individual games and show where agents gain these efficiencies.
Plasticity as the Mirror of Empowerment
May 15, 2025Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Our first finding is that plasticity is the mirror of empowerment: The agent's plasticity is identical to the empowerment of the environment, and vice versa. Our second finding establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Generalization in Monitored Markov Decision Processes (Mon-MDPs)
May 13, 2025Reinforcement learning (RL) typically models the interaction between the agent and environment as a Markov decision process (MDP), where the rewards that guide the agent's behavior are always observable. However, in many real-world scenarios, rewards are not always observable, which can be modeled as a monitored Markov decision process (Mon-MDP). Prior work on Mon-MDPs have been limited to simple, tabular cases, restricting their applicability to real-world problems. This work explores Mon-MDPs using function approximation (FA) and investigates the challenges involved. We show that combining function approximation with a learned reward model enables agents to generalize from monitored states with observable rewards, to unmonitored environment states with unobservable rewards. Therefore, we demonstrate that such generalization with a reward model achieves near-optimal policies in environments formally defined as unsolvable. However, we identify a critical limitation of such function approximation, where agents incorrectly extrapolate rewards due to overgeneralization, resulting in undesirable behaviors. To mitigate overgeneralization, we propose a cautious police optimization method leveraging reward uncertainty. This work serves as a step towards bridging this gap between Mon-MDP theory and real-world applications.
Approximating Nash Equilibria in General-Sum Games via Meta-Learning
Apr 26, 2025



Nash equilibrium is perhaps the best-known solution concept in game theory. Such a solution assigns a strategy to each player which offers no incentive to unilaterally deviate. While a Nash equilibrium is guaranteed to always exist, the problem of finding one in general-sum games is PPAD-complete, generally considered intractable. Regret minimization is an efficient framework for approximating Nash equilibria in two-player zero-sum games. However, in general-sum games, such algorithms are only guaranteed to converge to a coarse-correlated equilibrium (CCE), a solution concept where players can correlate their strategies. In this work, we use meta-learning to minimize the correlations in strategies produced by a regret minimizer. This encourages the regret minimizer to find strategies that are closer to a Nash equilibrium. The meta-learned regret minimizer is still guaranteed to converge to a CCE, but we give a bound on the distance to Nash equilibrium in terms of our meta-loss. We evaluate our approach in general-sum imperfect information games. Our algorithms provide significantly better approximations of Nash equilibria than state-of-the-art regret minimization techniques.
Meta-Learning in Self-Play Regret Minimization
Apr 26, 2025Regret minimization is a general approach to online optimization which plays a crucial role in many algorithms for approximating Nash equilibria in two-player zero-sum games. The literature mainly focuses on solving individual games in isolation. However, in practice, players often encounter a distribution of similar but distinct games. For example, when trading correlated assets on the stock market, or when refining the strategy in subgames of a much larger game. Recently, offline meta-learning was used to accelerate one-sided equilibrium finding on such distributions. We build upon this, extending the framework to the more challenging self-play setting, which is the basis for most state-of-the-art equilibrium approximation algorithms for domains at scale. When selecting the strategy, our method uniquely integrates information across all decision states, promoting global communication as opposed to the traditional local regret decomposition. Empirical evaluation on normal-form games and river poker subgames shows our meta-learned algorithms considerably outperform other state-of-the-art regret minimization algorithms.
KETCHUP: K-Step Return Estimation for Sequential Knowledge Distillation
Apr 26, 2025We propose a novel k-step return estimation method (called KETCHUP) for Reinforcement Learning(RL)-based knowledge distillation (KD) in text generation tasks. Our idea is to induce a K-step return by using the Bellman Optimality Equation for multiple steps. Theoretical analysis shows that this K-step formulation reduces the variance of the gradient estimates, thus leading to improved RL optimization especially when the student model size is large. Empirical evaluation on three text generation tasks demonstrates that our approach yields superior performance in both standard task metrics and large language model (LLM)-based evaluation. These results suggest that our K-step return induction offers a promising direction for enhancing RL-based KD in LLM research.
Rethinking the Foundations for Continual Reinforcement Learning
Apr 10, 2025Algorithms and approaches for continual reinforcement learning have gained increasing attention. Much of this early progress rests on the foundations and standard practices of traditional reinforcement learning, without questioning if they are well-suited to the challenges of continual learning agents. We suggest that many core foundations of traditional RL are, in fact, antithetical to the goals of continual reinforcement learning. We enumerate four such foundations: the Markov decision process formalism, a focus on optimal policies, the expected sum of rewards as the primary evaluation metric, and episodic benchmark environments that embrace the other three foundations. Shedding such sacredly held and taught concepts is not easy. They are self-reinforcing in that each foundation depends upon and holds up the others, making it hard to rethink each in isolation. We propose an alternative set of all four foundations that are better suited to the continual learning setting. We hope to spur on others in rethinking the traditional foundations, proposing and critiquing alternatives, and developing new algorithms and approaches enabled by better-suited foundations.
Model-Based Exploration in Monitored Markov Decision Processes
Feb 24, 2025A tenet of reinforcement learning is that rewards are always observed by the agent. However, this is not true in many realistic settings, e.g., a human observer may not always be able to provide rewards, a sensor to observe rewards may be limited or broken, or rewards may be unavailable during deployment. Monitored Markov decision processes (Mon-MDPs) have recently been proposed as a model of such settings. Yet, Mon-MDP algorithms developed thus far do not fully exploit the problem structure, cannot take advantage of a known monitor, have no worst-case guarantees for ``unsolvable'' Mon-MDPs without specific initialization, and only have asymptotic proofs of convergence. This paper makes three contributions. First, we introduce a model-based algorithm for Mon-MDPs that addresses all of these shortcomings. The algorithm uses two instances of model-based interval estimation, one to guarantee that observable rewards are indeed observed, and another to learn the optimal policy. Second, empirical results demonstrate these advantages, showing faster convergence than prior algorithms in over two dozen benchmark settings, and even more dramatic improvements when the monitor process is known. Third, we present the first finite-sample bound on performance and show convergence to an optimal worst-case policy when some rewards are never observable.
Agency Is Frame-Dependent
Feb 06, 2025
Agency is a system's capacity to steer outcomes toward a goal, and is a central topic of study across biology, philosophy, cognitive science, and artificial intelligence. Determining if a system exhibits agency is a notoriously difficult question: Dennett (1989), for instance, highlights the puzzle of determining which principles can decide whether a rock, a thermostat, or a robot each possess agency. We here address this puzzle from the viewpoint of reinforcement learning by arguing that agency is fundamentally frame-dependent: Any measurement of a system's agency must be made relative to a reference frame. We support this claim by presenting a philosophical argument that each of the essential properties of agency proposed by Barandiaran et al. (2009) and Moreno (2018) are themselves frame-dependent. We conclude that any basic science of agency requires frame-dependence, and discuss the implications of this claim for reinforcement learning.
On the Interplay Between Sparsity and Training in Deep Reinforcement Learning
Jan 28, 2025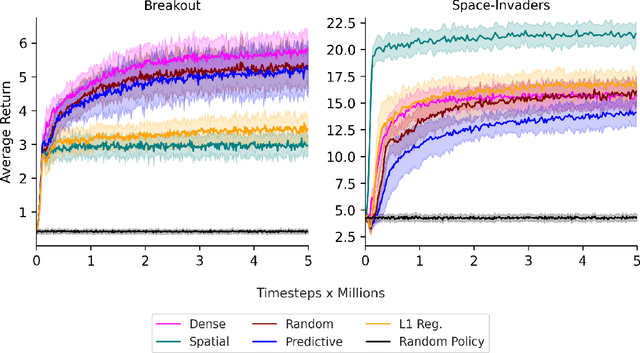
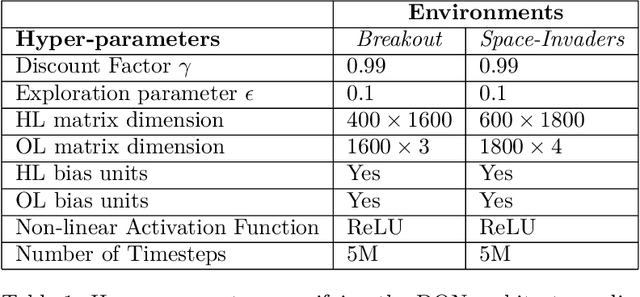
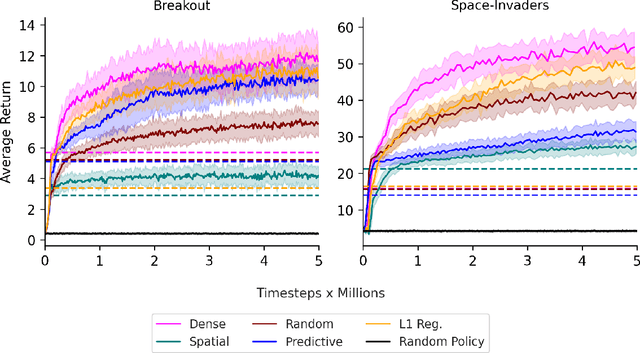

We study the benefits of different sparse architectures for deep reinforcement learning. In particular, we focus on image-based domains where spatially-biased and fully-connected architectures are common. Using these and several other architectures of equal capacity, we show that sparse structure has a significant effect on learning performance. We also observe that choosing the best sparse architecture for a given domain depends on whether the hidden layer weights are fixed or learned.