 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro Language Models Enable Instant Responses
Apr 21, 2026Edge devices such as smartwatches and smart glasses cannot continuously run even the smallest 100M-1B parameter language models due to power and compute constraints, yet cloud inference introduces multi-second latencies that break the illusion of a responsive assistant. We introduce micro language models ($μ$LMs): ultra-compact models (8M-30M parameters) that instantly generate the first 4-8 words of a contextually grounded response on-device, while a cloud model completes it; thus, masking the cloud latency. We show that useful language generation survives at this extreme scale with our models matching several 70M-256M-class existing models. We design a collaborative generation framework that reframes the cloud model as a continuator rather than a respondent, achieving seamless mid-sentence handoffs and structured graceful recovery via three error correction methods when the local opener goes wrong. Empirical results show that $μ$LMs can initiate responses that larger models complete seamlessly, demonstrating that orders-of-magnitude asymmetric collaboration is achievable and unlocking responsive AI for extremely resource-constrained devices. The model checkpoint and demo are available at https://github.com/Sensente/micro_language_model_swen_project.
A Hierarchical End-of-Turn Model with Primary Speaker Segmentation for Real-Time Conversational AI
Mar 10, 2026We present a real-time front-end for voice-based conversational AI to enable natural turn-taking in two-speaker scenarios by combining primary speaker segmentation with hierarchical End-of-Turn (EOT) detection. To operate robustly in multi-speaker environments, the system continuously identifies and tracks the primary user, ensuring that downstream EOT decisions are not confounded by background conversations. The tracked activity segments are fed to a hierarchical, causal EOT model that predicts the immediate conversational state by independently analyzing per-speaker speech features from both the primary speaker and the bot. Simultaneously, the model anticipates near-future states ($t{+}10/20/30$\,ms) through probabilistic predictions that are aware of the conversation partner's speech. Task-specific knowledge distillation compresses wav2vec~2.0 representations (768\,D) into a compact MFCC-based student (32\,D) for efficient deployment. The system achieves 82\% multi-class frame-level F1 and 70.6\% F1 on Backchannel detection, with 69.3\% F1 on a binary Final vs.\ Others task. On an end-to-end turn-detection benchmark, our model reaches 87.7\% recall vs.\ 58.9\% for Smart Turn~v3 while keeping a median detection latency of 36\,ms versus 800--1300\,ms. Despite using only 1.14\,M parameters, the proposed model matches or exceeds transformer-based baselines while substantially reducing latency and memory footprint, making it suitable for edge deployment.
Self-Refining Vision Language Model for Robotic Failure Detection and Reasoning
Feb 12, 2026Reasoning about failures is crucial for building reliable and trustworthy robotic systems. Prior approaches either treat failure reasoning as a closed-set classification problem or assume access to ample human annotations. Failures in the real world are typically subtle, combinatorial, and difficult to enumerate, whereas rich reasoning labels are expensive to acquire. We address this problem by introducing ARMOR: Adaptive Round-based Multi-task mOdel for Robotic failure detection and reasoning. We formulate detection and reasoning as a multi-task self-refinement process, where the model iteratively predicts detection outcomes and natural language reasoning conditioned on past outputs. During training, ARMOR learns from heterogeneous supervision - large-scale sparse binary labels and small-scale rich reasoning annotations - optimized via a combination of offline and online imitation learning. At inference time, ARMOR generates multiple refinement trajectories and selects the most confident prediction via a self-certainty metric. Experiments across diverse environments show that ARMOR achieves state-of-the-art performance by improving over the previous approaches by up to 30% on failure detection rate and up to 100% in reasoning measured through LLM fuzzy match score, demonstrating robustness to heterogeneous supervision and open-ended reasoning beyond predefined failure modes. We provide dditional visualizations on our website: https://sites.google.com/utexas.edu/armor
HyMAD: A Hybrid Multi-Activity Detection Approach for Border Surveillance and Monitoring
Nov 18, 2025



Seismic sensing has emerged as a promising solution for border surveillance and monitoring; the seismic sensors that are often buried underground are small and cannot be noticed easily, making them difficult for intruders to detect, avoid, or vandalize. This significantly enhances their effectiveness compared to highly visible cameras or fences. However, accurately detecting and distinguishing between overlapping activities that are happening simultaneously, such as human intrusions, animal movements, and vehicle rumbling, remains a major challenge due to the complex and noisy nature of seismic signals. Correctly identifying simultaneous activities is critical because failing to separate them can lead to misclassification, missed detections, and an incomplete understanding of the situation, thereby reducing the reliability of surveillance systems. To tackle this problem, we propose HyMAD (Hybrid Multi-Activity Detection), a deep neural architecture based on spatio-temporal feature fusion. The framework integrates spectral features extracted with SincNet and temporal dependencies modeled by a recurrent neural network (RNN). In addition, HyMAD employs self-attention layers to strengthen intra-modal representations and a cross-modal fusion module to achieve robust multi-label classification of seismic events. e evaluate our approach on a dataset constructed from real-world field recordings collected in the context of border surveillance and monitoring, demonstrating its ability to generalize to complex, simultaneous activity scenarios involving humans, animals, and vehicles. Our method achieves competitive performance and offers a modular framework for extending seismic-based activity recognition in real-world security applications.
RePose-NeRF: Robust Radiance Fields for Mesh Reconstruction under Noisy Camera Poses
Nov 11, 2025Accurate 3D reconstruction from multi-view images is essential for downstream robotic tasks such as navigation, manipulation, and environment understanding. However, obtaining precise camera poses in real-world settings remains challenging, even when calibration parameters are known. This limits the practicality of existing NeRF-based methods that rely heavily on accurate extrinsic estimates. Furthermore, their implicit volumetric representations differ significantly from the widely adopted polygonal meshes, making rendering and manipulation inefficient in standard 3D software. In this work, we propose a robust framework that reconstructs high-quality, editable 3D meshes directly from multi-view images with noisy extrinsic parameters. Our approach jointly refines camera poses while learning an implicit scene representation that captures fine geometric detail and photorealistic appearance. The resulting meshes are compatible with common 3D graphics and robotics tools, enabling efficient downstream use. Experiments on standard benchmarks demonstrate that our method achieves accurate and robust 3D reconstruction under pose uncertainty, bridging the gap between neural implicit representations and practical robotic applications.
SCA: Streaming Cross-attention Alignment for Echo Cancellation
Nov 01, 2022



End-to-End deep learning has shown promising results for speech enhancement tasks, such as noise suppression, dereverberation, and speech separation. However, most state-of-the-art methods for echo cancellation are either classical DSP-based or hybrid DSP-ML algorithms. Components such as the delay estimator and adaptive linear filter are based on traditional signal processing concepts, and deep learning algorithms typically only serve to replace the non-linear residual echo suppressor. This paper introduces an end-to-end echo cancellation network with a streaming cross-attention alignment (SCA). Our proposed method can handle unaligned inputs without requiring external alignment and generate high-quality speech without echoes. At the same time, the end-to-end algorithm simplifies the current echo cancellation pipeline for time-variant echo path cases. We test our proposed method on the ICASSP2022 and Interspeech2021 Microsoft deep echo cancellation challenge evaluation dataset, where our method outperforms some of the other hybrid and end-to-end methods.
Interspeech 2021 Deep Noise Suppression Challenge
Jan 10, 2021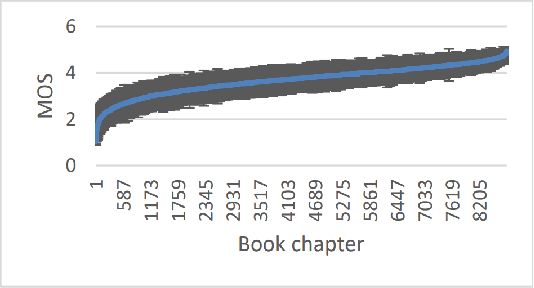
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. We recently organized a DNS challenge special session at INTERSPEECH and ICASSP 2020. We open-sourced training and test datasets for the wideband scenario. We also open-sourced a subjective evaluation framework based on ITU-T standard P.808, which was also used to evaluate participants of the challenge. Many researchers from academia and industry made significant contributions to push the field forward, yet even the best noise suppressor was far from achieving superior speech quality in challenging scenarios. In this version of the challenge organized at INTERSPEECH 2021, we are expanding both our training and test datasets to accommodate full band scenarios. The two tracks in this challenge will focus on real-time denoising for (i) wide band, and(ii) full band scenarios. We are also making available a reliable non-intrusive objective speech quality metric called DNSMOS for the participants to use during their development phase.
Resonance: Replacing Software Constants with Context-Aware Models in Real-time Communication
Nov 23, 2020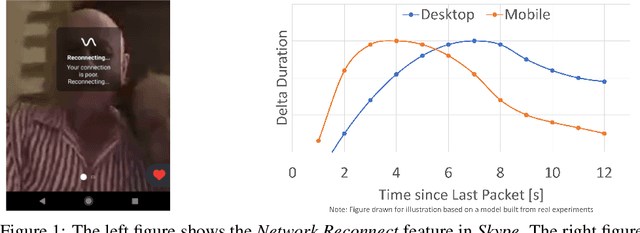


Large software systems tune hundreds of 'constants' to optimize their runtime performance. These values are commonly derived through intuition, lab tests, or A/B tests. A 'one-size-fits-all' approach is often sub-optimal as the best value depends on runtime context. In this paper, we provide an experimental approach to replace constants with learned contextual functions for Skype - a widely used real-time communication (RTC) application. We present Resonance, a system based on contextual bandits (CB). We describe experiences from three real-world experiments: applying it to the audio, video, and transport components in Skype. We surface a unique and practical challenge of performing machine learning (ML) inference in large software systems written using encapsulation principles. Finally, we open-source FeatureBroker, a library to reduce the friction in adopting ML models in such development environments
The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results
May 29, 2020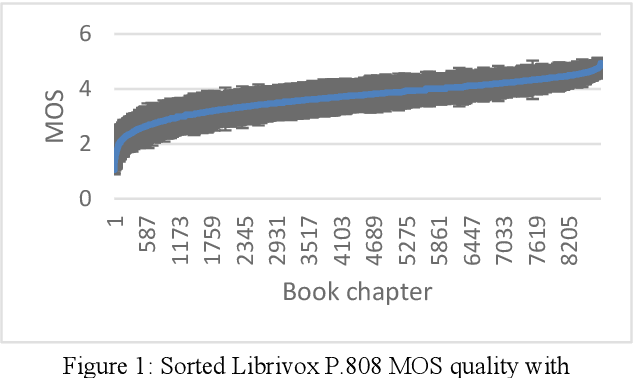

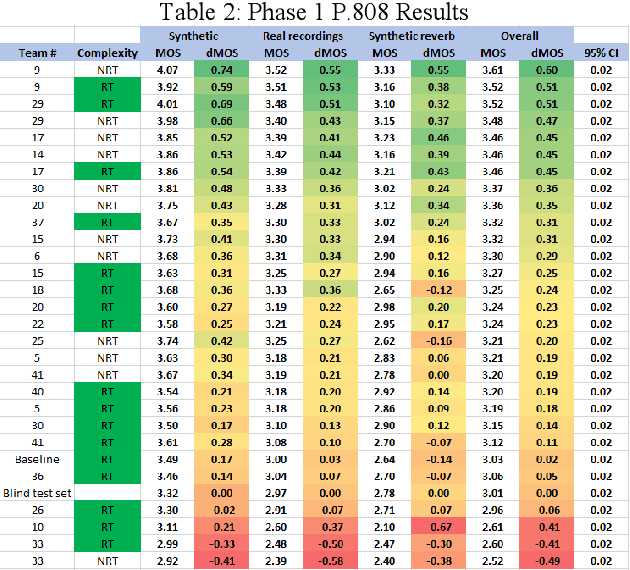
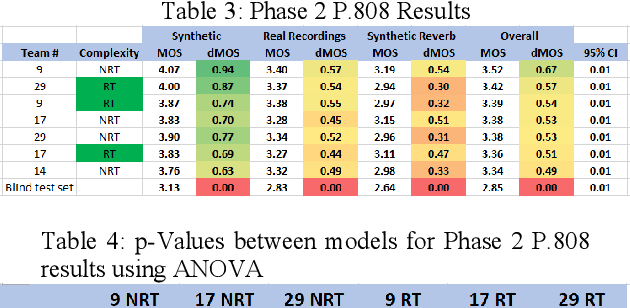
The INTERSPEECH 2020 Deep Noise Suppression (DNS) Challenge is intended to promote collaborative research in real-time single-channel Speech Enhancement aimed to maximize the subjective (perceptual) quality of the enhanced speech. A typical approach to evaluate the noise suppression methods is to use objective metrics on the test set obtained by splitting the original dataset. While the performance is good on the synthetic test set, often the model performance degrades significantly on real recordings. Also, most of the conventional objective metrics do not correlate well with subjective tests and lab subjective tests are not scalable for a large test set. In this challenge, we open-sourced a large clean speech and noise corpus for training the noise suppression models and a representative test set to real-world scenarios consisting of both synthetic and real recordings. We also open-sourced an online subjective test framework based on ITU-T P.808 for researchers to reliably test their developments. We evaluated the results using P.808 on a blind test set. The results and the key learnings from the challenge are discussed. The datasets and scripts can be found here for quick access https://github.com/microsoft/DNS-Challenge.
Estimating Aggregate Properties In Relational Networks With Unobserved Data
Jan 27, 2020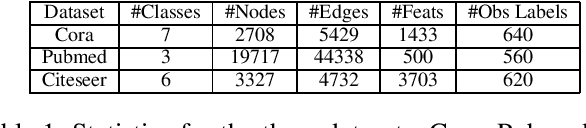
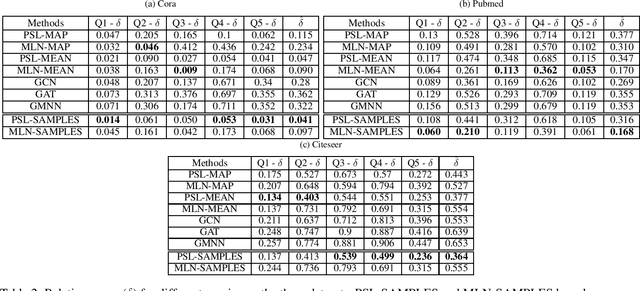
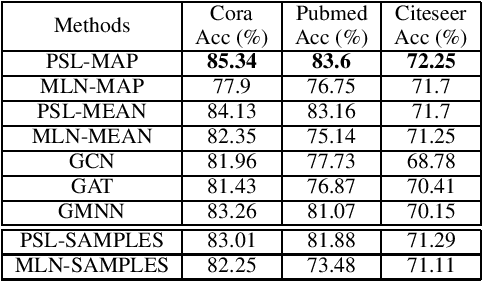
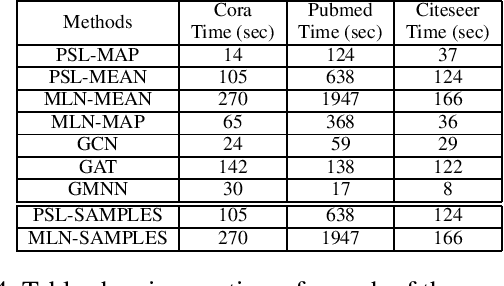
Aggregate network properties such as cluster cohesion and the number of bridge nodes can be used to glean insights about a network's community structure, spread of influence and the resilience of the network to faults. Efficiently computing network properties when the network is fully observed has received significant attention (Wasserman and Faust 1994; Cook and Holder 2006), however the problem of computing aggregate network properties when there is missing data attributes has received little attention. Computing these properties for networks with missing attributes involves performing inference over the network. Statistical relational learning (SRL) and graph neural networks (GNNs) are two classes of machine learning approaches well suited for inferring missing attributes in a graph. In this paper, we study the effectiveness of these approaches in estimating aggregate properties on networks with missing attributes. We compare two SRL approaches and three GNNs. For these approaches we estimate these properties using point estimates such as MAP and mean. For SRL-based approaches that can infer a joint distribution over the missing attributes, we also estimate these properties as an expectation over the distribution. To compute the expectation tractably for probabilistic soft logic, one of the SRL approaches that we study, we introduce a novel sampling framework. In the experimental evaluation, using three benchmark datasets, we show that SRL-based approaches tend to outperform GNN-based approaches both in computing aggregate properties and predictive accuracy. Specifically, we show that estimating the aggregate properties as an expectation over the joint distribution outperforms point estimates.