 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-MRL: Cross-view Aligned Evidence-driven Multimodal Reinforcement Learning for Reliable 3D Tumor Analysis
Jun 22, 2026While Vision-Language Models (VLMs) show great promise in volumetric medical report generation, they frequently suffer from visual hallucinations and a lack of grounding in 3D CT data. Current Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) strategies typically optimize text fidelity alone, essentially rewarding correct diagnoses derived from language priors rather than genuine visual perception. To address this, we propose cross-view aligned Evidence-driven Multimodal Reinforcement Learning (Evidence-MRL, noted as E-MRL), a reliable RL reasoning framework that formulates the generation process as a Markov Decision Process of "diagnosis-localization-verification". Unlike standard approaches, our model is explicitly trained to identify a "key evidence slice" alongside the global diagnostic report, grounding its findings in verifiable visual evidence. Crucially, we introduce a novel cross-view consistency reward, which validates the semantic alignment between the golden-standard report and a local visual re-query of the selected key slice, providing additional rewards for correctly-localized reasoning. Experiments on large-scale 3D CT tumor datasets demonstrate that E-MRL significantly reduces hallucinations and improves diagnostic accuracy compared to SFT and RL baselines, offering a clinically interpretable solution for visually-grounded and tumor analysis.
Scientific Graphics Program Synthesis via Dual Self-Consistency Reinforcement Learning
Apr 07, 2026Graphics Program Synthesis is pivotal for interpreting and editing visual data, effectively facilitating the reverse-engineering of static visuals into editable TikZ code. While TikZ is the de facto standard for scientific schematics due to its programmatic flexibility, its requirement for rigorous spatial precision presents a significant challenge for Multimodal Large Language Models. Progress is currently stifled by two primary gaps: (1) Data Quality Gap: existing image-TikZ corpora often lack strict executability and reliable visual alignment; (2) Evaluation Gap: a lack of benchmarks for both structural and visual fidelity. To address these, we present a closed-loop framework featuring: SciTikZ-230K, a large-scale, high-quality dataset from our Execution-Centric Data Engine covering 11 diverse scientific disciplines; SciTikZ-Bench, a multifaceted benchmark spanning from basic geometric constructs to intricate hierarchical schematics to evaluate both visual fidelity and structural logic. To further broaden the scope of visual-code optimization methodology, we introduce a novel Dual Self-Consistency Reinforcement Learning optimization paradigm, which utilizes Round-Trip Verification to penalize degenerate code and boost overall self-consistency. Empowered by these, our trained model SciTikZer-8B achieves state-of-the-art performance, consistently outperforming proprietary giants like Gemini-2.5-Pro and massive models like Qwen3-VL-235B-A22B-Instruct.
OmniCT: Towards a Unified Slice-Volume LVLM for Comprehensive CT Analysis
Feb 18, 2026Computed Tomography (CT) is one of the most widely used and diagnostically information-dense imaging modalities, covering critical organs such as the heart, lungs, liver, and colon. Clinical interpretation relies on both slice-driven local features (e.g., sub-centimeter nodules, lesion boundaries) and volume-driven spatial representations (e.g., tumor infiltration, inter-organ anatomical relations). However, existing Large Vision-Language Models (LVLMs) remain fragmented in CT slice versus volumetric understanding: slice-driven LVLMs show strong generalization but lack cross-slice spatial consistency, while volume-driven LVLMs explicitly capture volumetric semantics but suffer from coarse granularity and poor compatibility with slice inputs. The absence of a unified modeling paradigm constitutes a major bottleneck for the clinical translation of medical LVLMs. We present OmniCT, a powerful unified slice-volume LVLM for CT scenarios, which makes three contributions: (i) Spatial Consistency Enhancement (SCE): volumetric slice composition combined with tri-axial positional embedding that introduces volumetric consistency, and an MoE hybrid projection enables efficient slice-volume adaptation; (ii) Organ-level Semantic Enhancement (OSE): segmentation and ROI localization explicitly align anatomical regions, emphasizing lesion- and organ-level semantics; (iii) MedEval-CT: the largest slice-volume CT dataset and hybrid benchmark integrates comprehensive metrics for unified evaluation. OmniCT consistently outperforms existing methods with a substantial margin across diverse clinical tasks and satisfies both micro-level detail sensitivity and macro-level spatial reasoning. More importantly, it establishes a new paradigm for cross-modal medical imaging understanding.
Heartcare Suite: Multi-dimensional Understanding of ECG with Raw Multi-lead Signal Modeling
Jun 06, 2025We present Heartcare Suite, a multimodal comprehensive framework for finegrained electrocardiogram (ECG) understanding. It comprises three key components: (i) Heartcare-220K, a high-quality, structured, and comprehensive multimodal ECG dataset covering essential tasks such as disease diagnosis, waveform morphology analysis, and rhythm interpretation. (ii) Heartcare-Bench, a systematic and multi-dimensional benchmark designed to evaluate diagnostic intelligence and guide the optimization of Medical Multimodal Large Language Models (Med-MLLMs) in ECG scenarios. and (iii) HeartcareGPT with a tailored tokenizer Bidirectional ECG Abstract Tokenization (Beat), which compresses raw multi-lead signals into semantically rich discrete tokens via duallevel vector quantization and query-guided bidirectional diffusion mechanism. Built upon Heartcare-220K, HeartcareGPT achieves strong generalization and SoTA performance across multiple clinically meaningful tasks. Extensive experiments demonstrate that Heartcare Suite is highly effective in advancing ECGspecific multimodal understanding and evaluation. Our project is available at https://github.com/Wznnnnn/Heartcare-Suite .
EyecareGPT: Boosting Comprehensive Ophthalmology Understanding with Tailored Dataset, Benchmark and Model
Apr 18, 2025Medical Large Vision-Language Models (Med-LVLMs) demonstrate significant potential in healthcare, but their reliance on general medical data and coarse-grained global visual understanding limits them in intelligent ophthalmic diagnosis. Currently, intelligent ophthalmic diagnosis faces three major challenges: (i) Data. The lack of deeply annotated, high-quality, multi-modal ophthalmic visual instruction data; (ii) Benchmark. The absence of a comprehensive and systematic benchmark for evaluating diagnostic performance; (iii) Model. The difficulty of adapting holistic visual architectures to fine-grained, region-specific ophthalmic lesion identification. In this paper, we propose the Eyecare Kit, which systematically tackles the aforementioned three key challenges with the tailored dataset, benchmark and model: First, we construct a multi-agent data engine with real-life ophthalmology data to produce Eyecare-100K, a high-quality ophthalmic visual instruction dataset. Subsequently, we design Eyecare-Bench, a benchmark that comprehensively evaluates the overall performance of LVLMs on intelligent ophthalmic diagnosis tasks across multiple dimensions. Finally, we develop the EyecareGPT, optimized for fine-grained ophthalmic visual understanding thoroughly, which incorporates an adaptive resolution mechanism and a layer-wise dense connector. Extensive experimental results indicate that the EyecareGPT achieves state-of-the-art performance in a range of ophthalmic tasks, underscoring its significant potential for the advancement of open research in intelligent ophthalmic diagnosis. Our project is available at https://github.com/DCDmllm/EyecareGPT.
Astrea: A MOE-based Visual Understanding Model with Progressive Alignment
Mar 12, 2025



Vision-Language Models (VLMs) based on Mixture-of-Experts (MoE) architectures have emerged as a pivotal paradigm in multimodal understanding, offering a powerful framework for integrating visual and linguistic information. However, the increasing complexity and diversity of tasks present significant challenges in coordinating load balancing across heterogeneous visual experts, where optimizing one specialist's performance often compromises others' capabilities. To address task heterogeneity and expert load imbalance, we propose Astrea, a novel multi-expert collaborative VLM architecture based on progressive pre-alignment. Astrea introduces three key innovations: 1) A heterogeneous expert coordination mechanism that integrates four specialized models (detection, segmentation, classification, captioning) into a comprehensive expert matrix covering essential visual comprehension elements; 2) A dynamic knowledge fusion strategy featuring progressive pre-alignment to harmonize experts within the VLM latent space through contrastive learning, complemented by probabilistically activated stochastic residual connections to preserve knowledge continuity; 3) An enhanced optimization framework utilizing momentum contrastive learning for long-range dependency modeling and adaptive weight allocators for real-time expert contribution calibration. Extensive evaluations across 12 benchmark tasks spanning VQA, image captioning, and cross-modal retrieval demonstrate Astrea's superiority over state-of-the-art models, achieving an average performance gain of +4.7\%. This study provides the first empirical demonstration that progressive pre-alignment strategies enable VLMs to overcome task heterogeneity limitations, establishing new methodological foundations for developing general-purpose multimodal agents.
A data-driven approach for multiscale elliptic PDEs with random coefficients based on intrinsic dimension reduction
Jul 01, 2019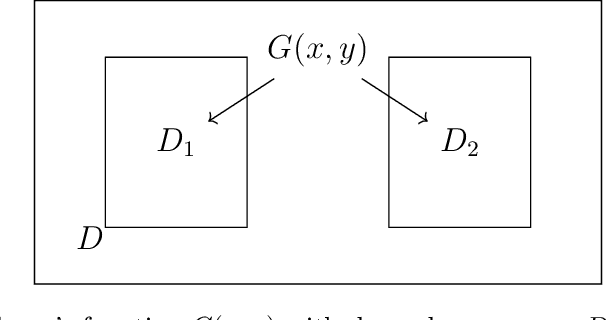
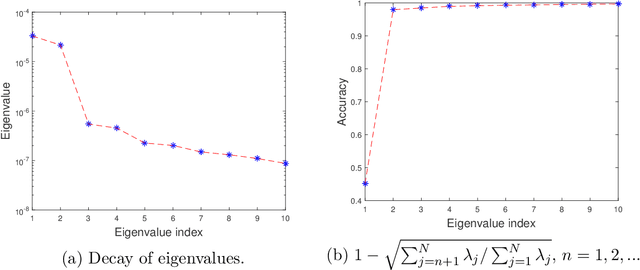
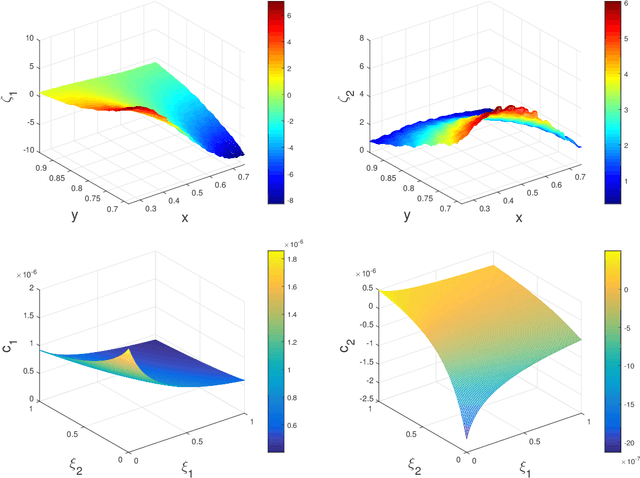
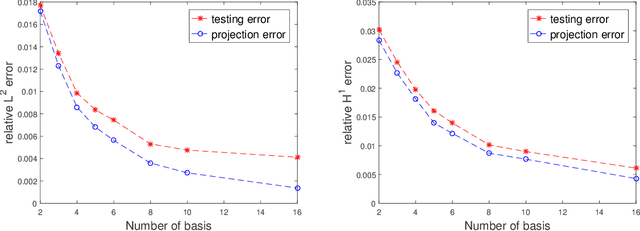
We propose a data-driven approach to solve multiscale elliptic PDEs with random coefficients based on the intrinsic low dimension structure of the underlying elliptic differential operators. Our method consists of offline and online stages. At the offline stage, a low dimension space and its basis are extracted from the data to achieve significant dimension reduction in the solution space. At the online stage, the extracted basis will be used to solve a new multiscale elliptic PDE efficiently. The existence of low dimension structure is established by showing the high separability of the underlying Green's functions. Different online construction methods are proposed depending on the problem setup. We provide error analysis based on the sampling error and the truncation threshold in building the data-driven basis. Finally, we present numerical examples to demonstrate the accuracy and efficiency of the proposed method.