 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark and Empirical Analysis for Replay Strategies in Continual Learning
Aug 04, 2022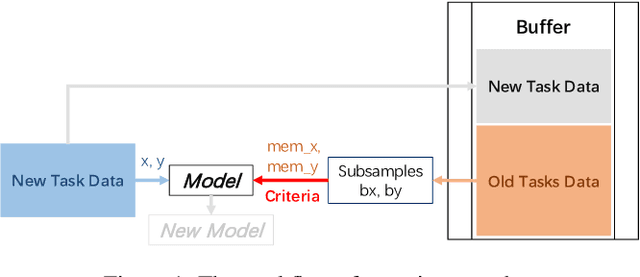
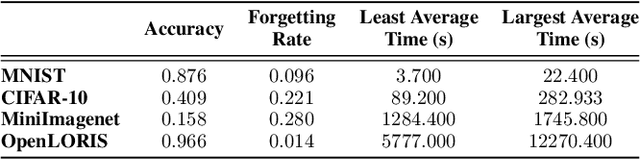
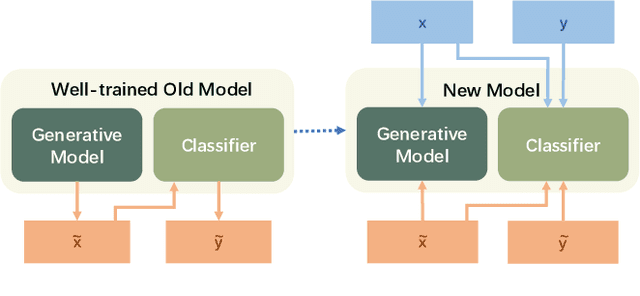

With the capacity of continual learning, humans can continuously acquire knowledge throughout their lifespan. However, computational systems are not, in general, capable of learning tasks sequentially. This long-standing challenge for deep neural networks (DNNs) is called catastrophic forgetting. Multiple solutions have been proposed to overcome this limitation. This paper makes an in-depth evaluation of the memory replay methods, exploring the efficiency, performance, and scalability of various sampling strategies when selecting replay data. All experiments are conducted on multiple datasets under various domains. Finally, a practical solution for selecting replay methods for various data distributions is provided.
Factored Adaptation for Non-Stationary Reinforcement Learning
Mar 30, 2022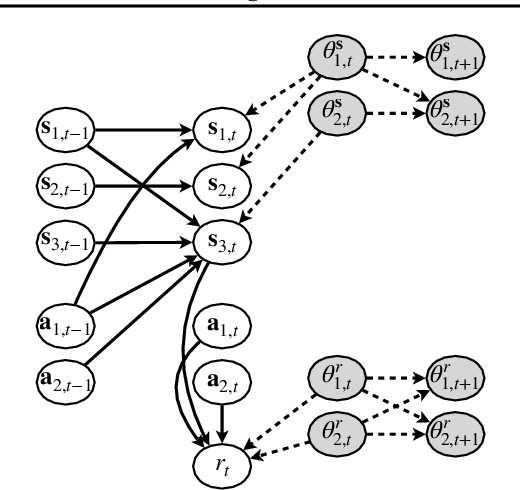
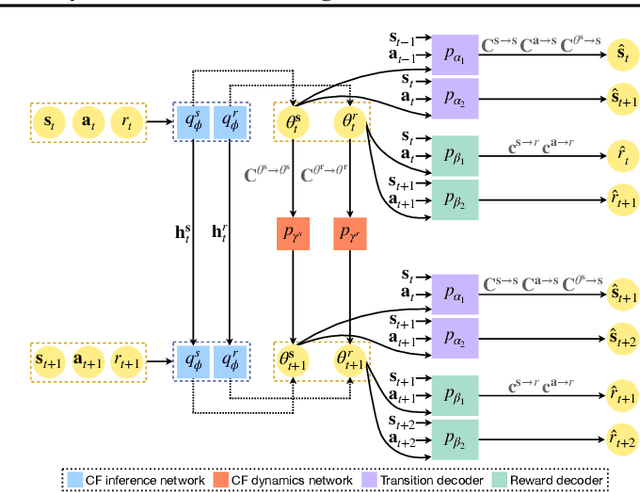

Dealing with non-stationarity in environments (i.e., transition dynamics) and objectives (i.e., reward functions) is a challenging problem that is crucial in real-world applications of reinforcement learning (RL). Most existing approaches only focus on families of stationary MDPs, in which the non-stationarity is episodic, i.e., the change is only possible across episodes. The few works that do consider non-stationarity without a specific boundary, i.e., also allow for changes within an episode, model the changes monolithically in a single shared embedding vector. In this paper, we propose Factored Adaptation for Non-Stationary RL (FANS-RL), a factored adaption approach that explicitly learns the individual latent change factors affecting the transition dynamics and reward functions. FANS-RL learns jointly the structure of a factored MDP and a factored representation of the time-varying change factors, as well as the specific state components that they affect, via a factored non-stationary variational autoencoder. Through this general framework, we can consider general non-stationary scenarios with different changing function types and changing frequency. Experimental results demonstrate that FANS-RL outperforms existing approaches in terms of rewards, compactness of the latent state representation and robustness to varying degrees of non-stationarity.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021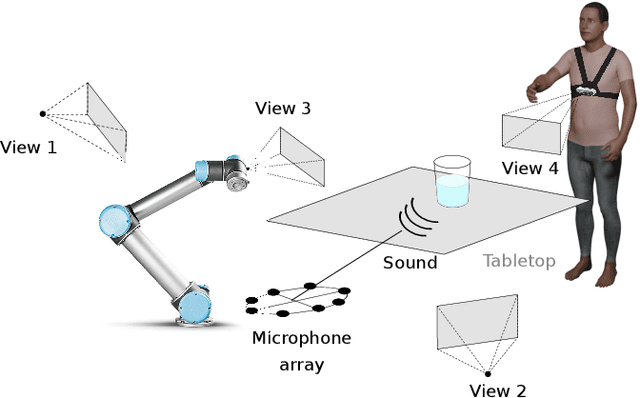


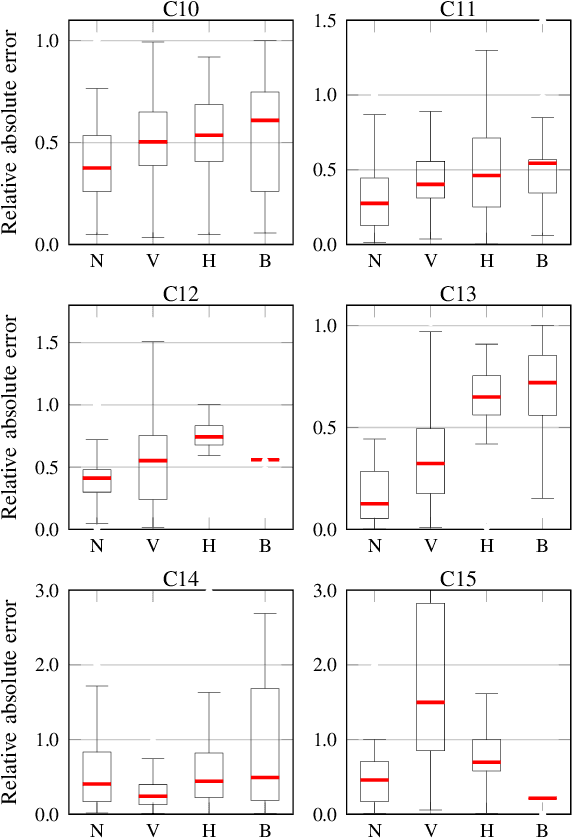
Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.
AdaRL: What, Where, and How to Adapt in Transfer Reinforcement Learning
Jul 07, 2021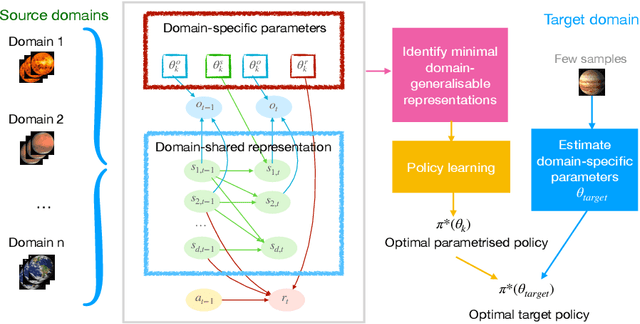
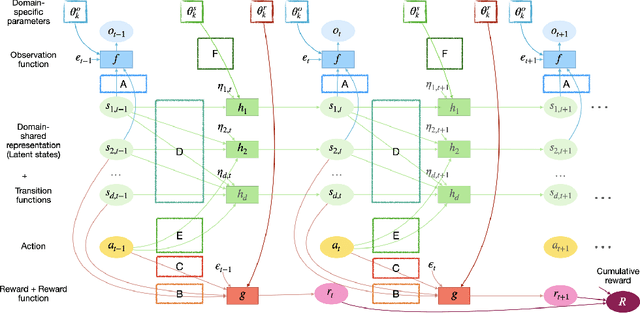
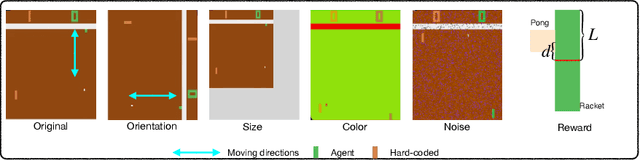

Most approaches in reinforcement learning (RL) are data-hungry and specific to fixed environments. In this paper, we propose a principled framework for adaptive RL, called AdaRL, that adapts reliably to changes across domains. Specifically, we construct a generative environment model for the structural relationships among variables in the system and embed the changes in a compact way, which provides a clear and interpretable picture for locating what and where the changes are and how to adapt. Based on the environment model, we characterize a minimal set of representations, including both domain-specific factors and domain-shared state representations, that suffice for reliable and low-cost transfer. Moreover, we show that by explicitly leveraging a compact representation to encode changes, we can adapt the policy with only a few samples without further policy optimization in the target domain. We illustrate the efficacy of AdaRL through a series of experiments that allow for changes in different components of Cartpole and Atari games.
Serial-EMD: Fast Empirical Mode Decomposition Method for Multi-dimensional Signals Based on Serialization
Jun 22, 2021


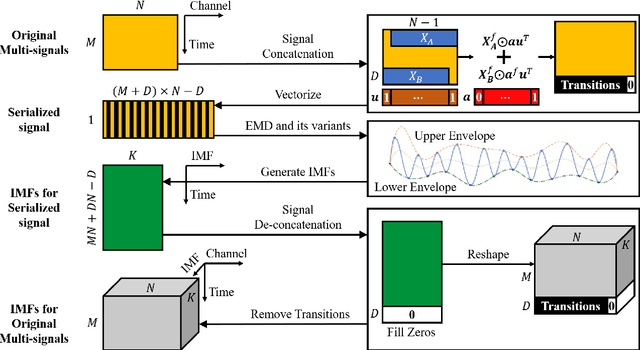
Empirical mode decomposition (EMD) has developed into a prominent tool for adaptive, scale-based signal analysis in various fields like robotics, security and biomedical engineering. Since the dramatic increase in amount of data puts forward higher requirements for the capability of real-time signal analysis, it is difficult for existing EMD and its variants to trade off the growth of data dimension and the speed of signal analysis. In order to decompose multi-dimensional signals at a faster speed, we present a novel signal-serialization method (serial-EMD), which concatenates multi-variate or multi-dimensional signals into a one-dimensional signal and uses various one-dimensional EMD algorithms to decompose it. To verify the effects of the proposed method, synthetic multi-variate time series, artificial 2D images with various textures and real-world facial images are tested. Compared with existing multi-EMD algorithms, the decomposition time becomes significantly reduced. In addition, the results of facial recognition with Intrinsic Mode Functions (IMFs) extracted using our method can achieve a higher accuracy than those obtained by existing multi-EMD algorithms, which demonstrates the superior performance of our method in terms of the quality of IMFs. Furthermore, this method can provide a new perspective to optimize the existing EMD algorithms, that is, transforming the structure of the input signal rather than being constrained by developing envelope computation techniques or signal decomposition methods. In summary, the study suggests that the serial-EMD technique is a highly competitive and fast alternative for multi-dimensional signal analysis.
Improving Conversational Recommendation System by Pretraining on Billions Scale of Knowledge Graph
Apr 30, 2021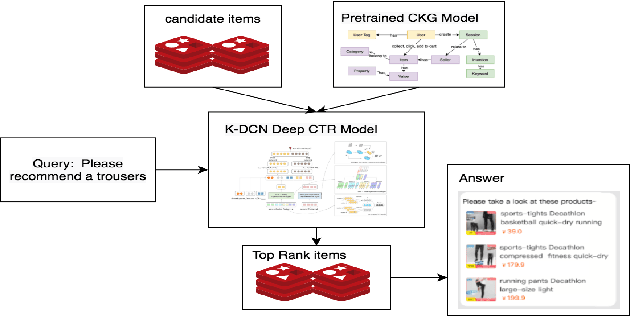
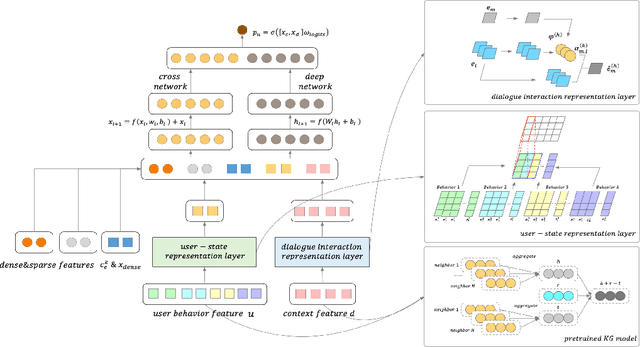
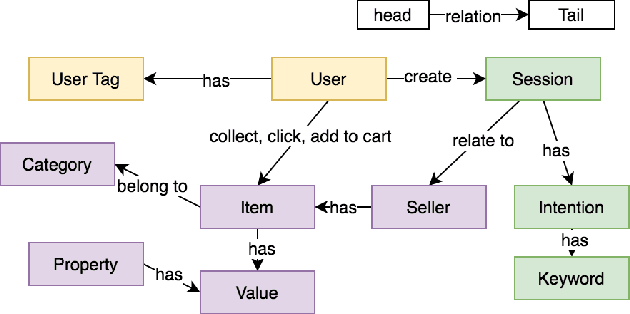
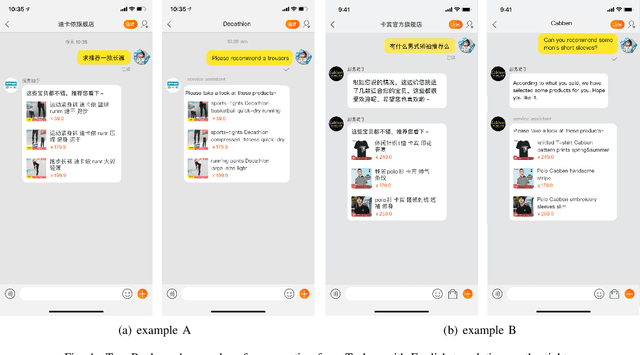
Conversational Recommender Systems (CRSs) in E-commerce platforms aim to recommend items to users via multiple conversational interactions. Click-through rate (CTR) prediction models are commonly used for ranking candidate items. However, most CRSs are suffer from the problem of data scarcity and sparseness. To address this issue, we propose a novel knowledge-enhanced deep cross network (K-DCN), a two-step (pretrain and fine-tune) CTR prediction model to recommend items. We first construct a billion-scale conversation knowledge graph (CKG) from information about users, items and conversations, and then pretrain CKG by introducing knowledge graph embedding method and graph convolution network to encode semantic and structural information respectively.To make the CTR prediction model sensible of current state of users and the relationship between dialogues and items, we introduce user-state and dialogue-interaction representations based on pre-trained CKG and propose K-DCN.In K-DCN, we fuse the user-state representation, dialogue-interaction representation and other normal feature representations via deep cross network, which will give the rank of candidate items to be recommended.We experimentally prove that our proposal significantly outperforms baselines and show it's real application in Alime.
Origami spring-inspired shape morphing for flexible robotics
Feb 10, 2021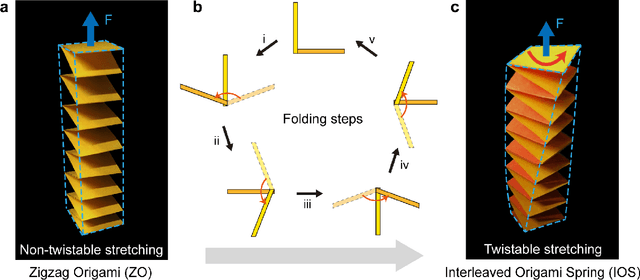
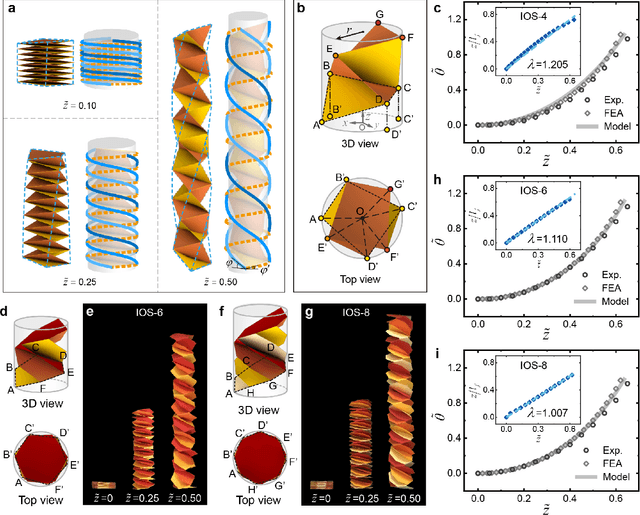
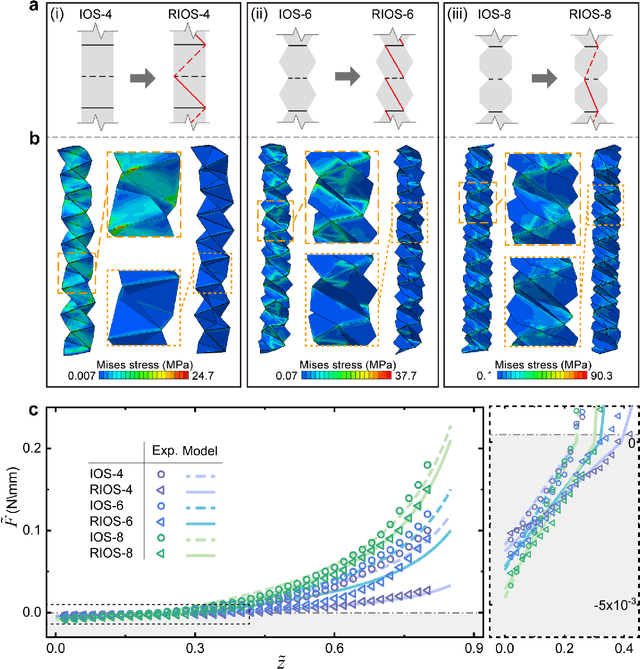
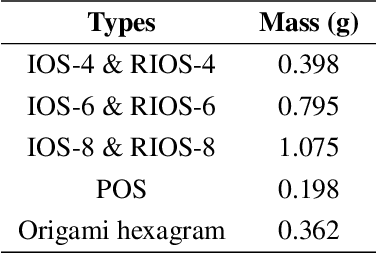
Flexible robotics are capable of achieving various functionalities by shape morphing, benefiting from their compliant bodies and reconfigurable structures. Here we construct and study a class of origami springs generalized from the known interleaved origami spring, as promising candidates for shape morphing in flexible robotics. These springs are found to exhibit nonlinear stretch-twist coupling and linear/nonlinear mechanical response in the compression/tension region, analyzed by the demonstrated continuum mechanics models, experiments, and finite element simulations. To improve the mechanical performance such as the damage resistance, we establish an origami rigidization method by adding additional creases to the spring system. Guided by the theoretical framework, we experimentally realize three types of flexible robotics -- origami spring ejectors, crawlers, and a transformer, which show the desired functionality and outstanding mechanical performance. The proposed concept of origami-aided design is expected to pave the way to facilitate diverse shape morphing of flexible robotics.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020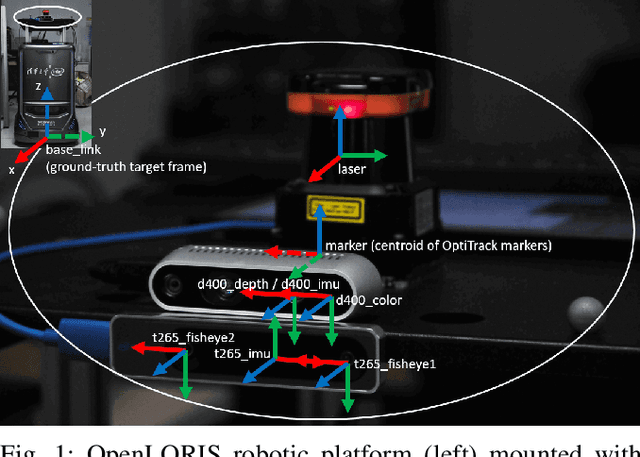
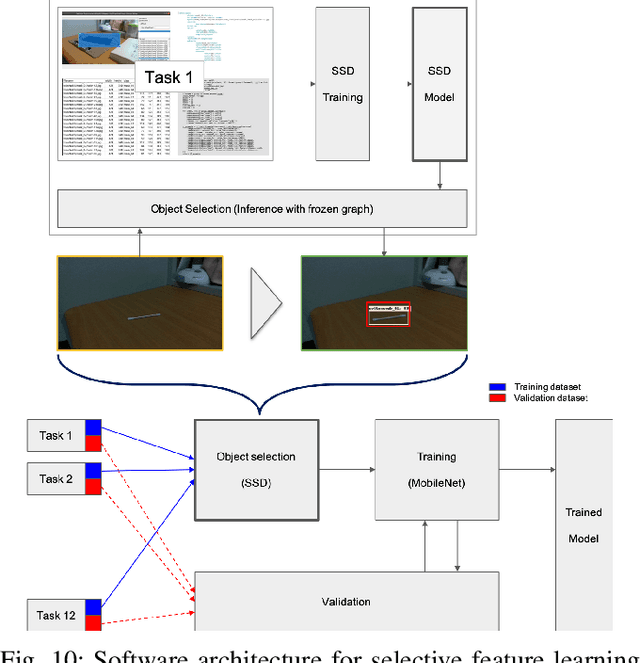


This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
OpenLORIS-Object: A Dataset and Benchmark towards Lifelong Object Recognition
Nov 15, 2019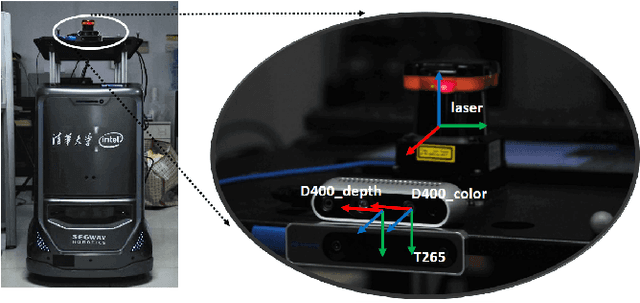


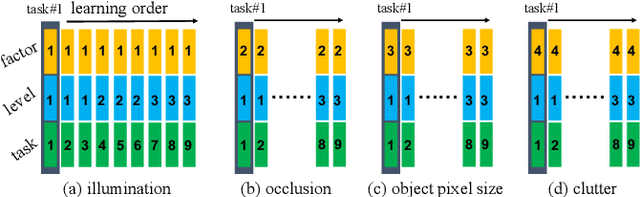
The recent breakthroughs in computer vision have benefited from the availability of large representative datasets (e.g. ImageNet and COCO) for training. Yet, robotic vision poses unique challenges for applying visual algorithms developed from these standard computer vision datasets due to their implicit assumption over non-varying distributions for a fixed set of tasks. Fully retraining models each time a new task becomes available is infeasible due to computational, storage and sometimes privacy issues, while na\"{i}ve incremental strategies have been shown to suffer from catastrophic forgetting. It is crucial for the robots to operate continuously under open-set and detrimental conditions with adaptive visual perceptual systems, where lifelong learning is a fundamental capability. However, very few datasets and benchmarks are available to evaluate and compare emerging techniques. To fill this gap, we provide a new lifelong robotic vision dataset ("OpenLORIS-Object") collected via RGB-D cameras mounted on mobile robots. The dataset embeds the challenges faced by a robot in the real-life application and provides new benchmarks for validating lifelong object recognition algorithms. Moreover, we have provided a testbed of $9$ state-of-the-art lifelong learning algorithms. Each of them involves $48$ tasks with $4$ evaluation metrics over the OpenLORIS-Object dataset. The results demonstrate that the object recognition task in the ever-changing difficulty environments is far from being solved and the bottlenecks are at the forward/backward transfer designs. Our dataset and benchmark are publicly available at \href{https://lifelong-robotic-vision.github.io/dataset/Data_Object-Recognition.html}{\underline{this url}}.
Deep joint rain and haze removal from single images
Jan 21, 2018
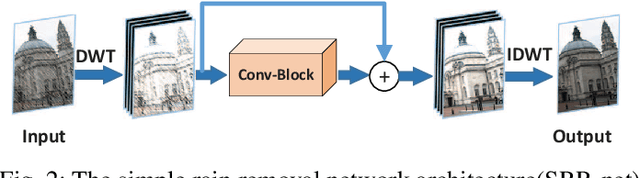
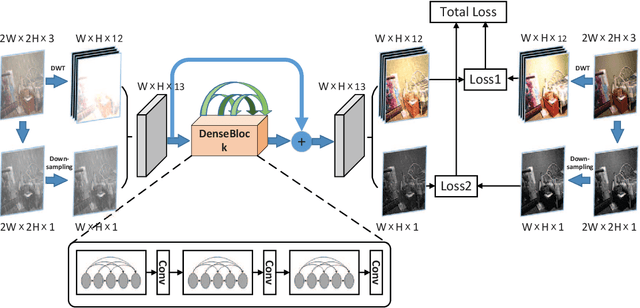

Rain removal from a single image is a challenge which has been studied for a long time. In this paper, a novel convolutional neural network based on wavelet and dark channel is proposed. On one hand, we think that rain streaks correspond to high frequency component of the image. Therefore, haar wavelet transform is a good choice to separate the rain streaks and background to some extent. More specifically, the LL subband of a rain image is more inclined to express the background information, while LH, HL, HH subband tend to represent the rain streaks and the edges. On the other hand, the accumulation of rain streaks from long distance makes the rain image look like haze veil. We extract dark channel of rain image as a feature map in network. By increasing this mapping between the dark channel of input and output images, we achieve haze removal in an indirect way. All of the parameters are optimized by back-propagation. Experiments on both synthetic and real- world datasets reveal that our method outperforms other state-of- the-art methods from a qualitative and quantitative perspective.