 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Preference-Aligned Concept Customization Benchmark via Decomposed Evaluation
Sep 03, 2025



Evaluating concept customization is challenging, as it requires a comprehensive assessment of fidelity to generative prompts and concept images. Moreover, evaluating multiple concepts is considerably more difficult than evaluating a single concept, as it demands detailed assessment not only for each individual concept but also for the interactions among concepts. While humans can intuitively assess generated images, existing metrics often provide either overly narrow or overly generalized evaluations, resulting in misalignment with human preference. To address this, we propose Decomposed GPT Score (D-GPTScore), a novel human-aligned evaluation method that decomposes evaluation criteria into finer aspects and incorporates aspect-wise assessments using Multimodal Large Language Model (MLLM). Additionally, we release Human Preference-Aligned Concept Customization Benchmark (CC-AlignBench), a benchmark dataset containing both single- and multi-concept tasks, enabling stage-wise evaluation across a wide difficulty range -- from individual actions to multi-person interactions. Our method significantly outperforms existing approaches on this benchmark, exhibiting higher correlation with human preferences. This work establishes a new standard for evaluating concept customization and highlights key challenges for future research. The benchmark and associated materials are available at https://github.com/ReinaIshikawa/D-GPTScore.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021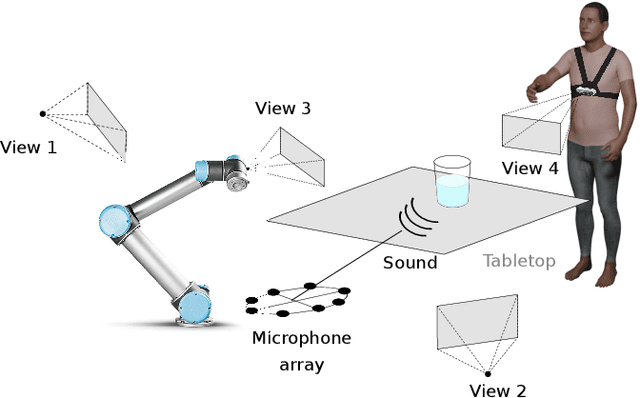


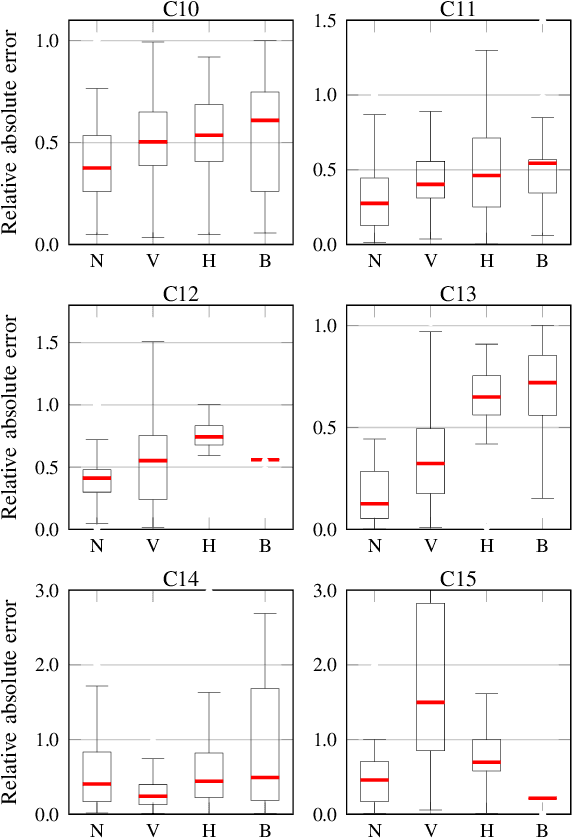
Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.