 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwT: Thinking without Tokens by Habitual Reasoning Distillation with Multi-Teachers' Guidance
Mar 31, 2025



Large Language Models (LLMs) have made significant strides in problem-solving by incorporating reasoning processes. However, this enhanced reasoning capability results in an increased number of output tokens during inference, leading to higher computational costs. To address this challenge, we propose TwT (Thinking without Tokens), a method that reduces inference-time costs through habitual reasoning distillation with multi-teachers' guidance, while maintaining high performance. Our approach introduces a Habitual Reasoning Distillation method, which internalizes explicit reasoning into the model's habitual behavior through a Teacher-Guided compression strategy inspired by human cognition. Additionally, we propose Dual-Criteria Rejection Sampling (DCRS), a technique that generates a high-quality and diverse distillation dataset using multiple teacher models, making our method suitable for unsupervised scenarios. Experimental results demonstrate that TwT effectively reduces inference costs while preserving superior performance, achieving up to a 13.6% improvement in accuracy with fewer output tokens compared to other distillation methods, offering a highly practical solution for efficient LLM deployment.
TablePilot; Recommending Human-Preferred Tabular Data Analysis with Large Language Models
Mar 17, 2025Tabular data analysis is crucial in many scenarios, yet efficiently identifying the most relevant data analysis queries and results for a new table remains a significant challenge. The complexity of tabular data, diverse analytical operations, and the demand for high-quality analysis make the process tedious. To address these challenges, we aim to recommend query-code-result triplets tailored for new tables in tabular data analysis workflows. In this paper, we present TablePilot, a pioneering tabular data analysis framework leveraging large language models to autonomously generate comprehensive and superior analytical results without relying on user profiles or prior interactions. The framework incorporates key designs in analysis preparation and analysis optimization to enhance accuracy. Additionally, we propose Rec-Align, a novel method to further improve recommendation quality and better align with human preferences. Experiments on DART, a dataset specifically designed for comprehensive tabular data analysis recommendation, demonstrate the effectiveness of our framework. Based on GPT-4o, the tuned TablePilot achieves 77.0% top-5 recommendation recall. Human evaluations further highlight its effectiveness in optimizing tabular data analysis workflows.
API Agents vs. GUI Agents: Divergence and Convergence
Mar 14, 2025Large language models (LLMs) have evolved beyond simple text generation to power software agents that directly translate natural language commands into tangible actions. While API-based LLM agents initially rose to prominence for their robust automation capabilities and seamless integration with programmatic endpoints, recent progress in multimodal LLM research has enabled GUI-based LLM agents that interact with graphical user interfaces in a human-like manner. Although these two paradigms share the goal of enabling LLM-driven task automation, they diverge significantly in architectural complexity, development workflows, and user interaction models. This paper presents the first comprehensive comparative study of API-based and GUI-based LLM agents, systematically analyzing their divergence and potential convergence. We examine key dimensions and highlight scenarios in which hybrid approaches can harness their complementary strengths. By proposing clear decision criteria and illustrating practical use cases, we aim to guide practitioners and researchers in selecting, combining, or transitioning between these paradigms. Ultimately, we indicate that continuing innovations in LLM-based automation are poised to blur the lines between API- and GUI-driven agents, paving the way for more flexible, adaptive solutions in a wide range of real-world applications.
Quantifying the Robustness of Retrieval-Augmented Language Models Against Spurious Features in Grounding Data
Mar 07, 2025Robustness has become a critical attribute for the deployment of RAG systems in real-world applications. Existing research focuses on robustness to explicit noise (e.g., document semantics) but overlooks spurious features (a.k.a. implicit noise). While previous works have explored spurious features in LLMs, they are limited to specific features (e.g., formats) and narrow scenarios (e.g., ICL). In this work, we statistically confirm the presence of spurious features in the RAG paradigm, a robustness problem caused by the sensitivity of LLMs to semantic-agnostic features. Moreover, we provide a comprehensive taxonomy of spurious features and empirically quantify their impact through controlled experiments. Further analysis reveals that not all spurious features are harmful and they can even be beneficial sometimes. Extensive evaluation results across multiple LLMs suggest that spurious features are a widespread and challenging problem in the field of RAG. The code and dataset will be released to facilitate future research. We release all codes and data at: $\\\href{https://github.com/maybenotime/RAG-SpuriousFeatures}{https://github.com/maybenotime/RAG-SpuriousFeatures}$.
TableLoRA: Low-rank Adaptation on Table Structure Understanding for Large Language Models
Mar 06, 2025



Tabular data are crucial in many fields and their understanding by large language models (LLMs) under high parameter efficiency paradigm is important. However, directly applying parameter-efficient fine-tuning (PEFT) techniques to tabular tasks presents significant challenges, particularly in terms of better table serialization and the representation of two-dimensional structured information within a one-dimensional sequence. To address this, we propose TableLoRA, a module designed to improve LLMs' understanding of table structure during PEFT. It incorporates special tokens for serializing tables with special token encoder and uses 2D LoRA to encode low-rank information on cell positions. Experiments on four tabular-related datasets demonstrate that TableLoRA consistently outperforms vanilla LoRA and surpasses various table encoding methods tested in control experiments. These findings reveal that TableLoRA, as a table-specific LoRA, enhances the ability of LLMs to process tabular data effectively, especially in low-parameter settings, demonstrating its potential as a robust solution for handling table-related tasks.
VEM: Environment-Free Exploration for Training GUI Agent with Value Environment Model
Feb 26, 2025



Training Vision-Language Models (VLMs) for Graphical User Interfaces (GUI) agents via Reinforcement Learning (RL) faces critical challenges: environment-based RL requires costly interactions, while environment-free methods struggle with distribution shift and reward generalization. We propose an environment-free RL framework that decouples value estimation from policy optimization by leveraging a pretrained Value Environment Model (VEM). VEM predicts state-action values directly from offline data, distilling human-like priors about GUI interaction outcomes without requiring next-state prediction or environmental feedback. This avoids compounding errors and enhances resilience to UI changes by focusing on semantic reasoning (e.g., Does this action advance the user's goal?). The framework operates in two stages: (1) pretraining VEM to estimate long-term action utilities and (2) guiding policy exploration with frozen VEM signals, enabling layout-agnostic GUI automation. Evaluated on Android-in-the-Wild benchmarks, VEM achieves state-of-the-art performance in both offline and online settings, outperforming environment-free baselines significantly and matching environment-based approaches without interaction costs. Importantly, VEM demonstrates that semantic-aware value estimation can achieve comparable performance with online-trained methods.
Distill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones?
Feb 26, 2025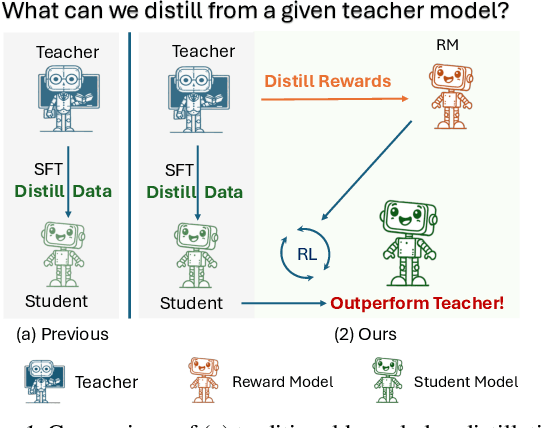

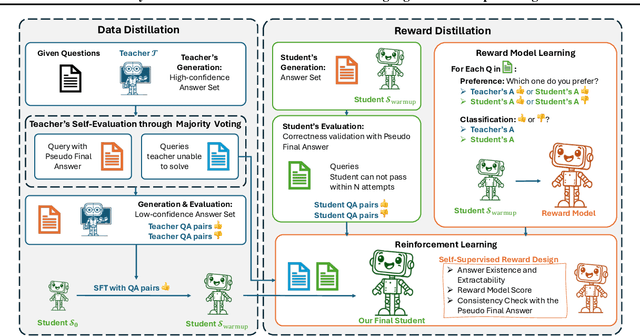
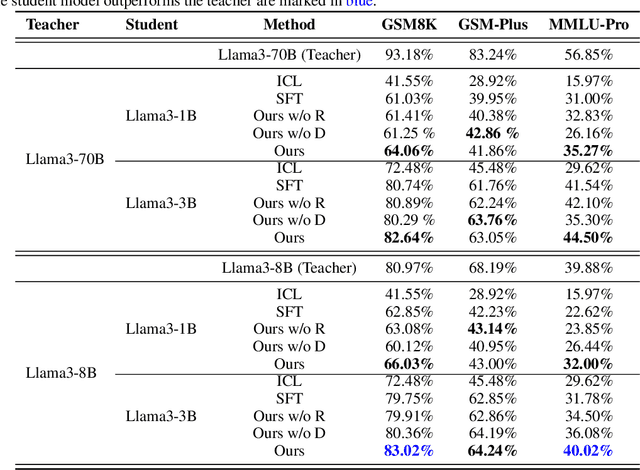
Distilling large language models (LLMs) typically involves transferring the teacher model's responses through supervised fine-tuning (SFT). However, this approach neglects the potential to distill both data (output content) and reward signals (quality evaluations). Extracting reliable reward signals directly from teacher models is challenging, as LLMs are optimized for generation rather than evaluation, often resulting in biased or inconsistent assessments. To address this limitation, we propose a novel distillation pipeline that transfers both responses and rewards. Our method generates pseudo-rewards through a self-supervised mechanism that leverages the inherent structure of both teacher and student responses, enabling reward learning without explicit external evaluation. The reward model subsequently guides reinforcement learning (RL), allowing iterative refinement of the student model after an SFT warm-up phase. Experiments on GSM8K and MMLU-PRO demonstrate that our method consistently outperforms traditional SFT-based approaches, enabling student models to surpass the performance of their teachers. This work highlights the potential for scalable, efficient distillation through structured self-supervised reward learning, reducing dependence on external reward supervision.
Lean and Mean: Decoupled Value Policy Optimization with Global Value Guidance
Feb 24, 2025Proximal Policy Optimization (PPO)-based Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human preferences. It requires joint training of an actor and critic with a pretrained, fixed reward model for guidance. This approach increases computational complexity and instability due to actor-critic interdependence. Additionally, PPO lacks access to true environment rewards in LLM tasks, limiting its adaptability. Under such conditions, pretraining a value model or a reward model becomes equivalent, as both provide fixed supervisory signals without new ground-truth feedback. To address these issues, we propose \textbf{Decoupled Value Policy Optimization (DVPO)}, a lean framework that replaces traditional reward modeling with a pretrained \emph{global value model (GVM)}. The GVM is conditioned on policy trajectories and predicts token-level return-to-go estimates. By decoupling value model from policy training (via frozen GVM-driven RL objectives), DVPO eliminates actor-critic interdependence, reducing GPU memory usage by 40\% and training time by 35\% compared to conventional RLHF. Experiments across benchmarks show DVPO outperforms efficient RLHF methods (e.g., DPO) while matching state-of-the-art PPO in performance.
MuDAF: Long-Context Multi-Document Attention Focusing through Contrastive Learning on Attention Heads
Feb 19, 2025Large Language Models (LLMs) frequently show distracted attention due to irrelevant information in the input, which severely impairs their long-context capabilities. Inspired by recent studies on the effectiveness of retrieval heads in long-context factutality, we aim at addressing this distraction issue through improving such retrieval heads directly. We propose Multi-Document Attention Focusing (MuDAF), a novel method that explicitly optimizes the attention distribution at the head level through contrastive learning. According to the experimental results, MuDAF can significantly improve the long-context question answering performance of LLMs, especially in multi-document question answering. Extensive evaluations on retrieval scores and attention visualizations show that MuDAF possesses great potential in making attention heads more focused on relevant information and reducing attention distractions.
MEETING DELEGATE: Benchmarking LLMs on Attending Meetings on Our Behalf
Feb 05, 2025In contemporary workplaces, meetings are essential for exchanging ideas and ensuring team alignment but often face challenges such as time consumption, scheduling conflicts, and inefficient participation. Recent advancements in Large Language Models (LLMs) have demonstrated their strong capabilities in natural language generation and reasoning, prompting the question: can LLMs effectively delegate participants in meetings? To explore this, we develop a prototype LLM-powered meeting delegate system and create a comprehensive benchmark using real meeting transcripts. Our evaluation reveals that GPT-4/4o maintain balanced performance between active and cautious engagement strategies. In contrast, Gemini 1.5 Pro tends to be more cautious, while Gemini 1.5 Flash and Llama3-8B/70B display more active tendencies. Overall, about 60\% of responses address at least one key point from the ground-truth. However, improvements are needed to reduce irrelevant or repetitive content and enhance tolerance for transcription errors commonly found in real-world settings. Additionally, we implement the system in practical settings and collect real-world feedback from demos. Our findings underscore the potential and challenges of utilizing LLMs as meeting delegates, offering valuable insights into their practical application for alleviating the burden of meetings.