 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Before You Match: Instance Understanding Matters in Video Object Segmentation
Dec 13, 2022



Exploring dense matching between the current frame and past frames for long-range context modeling, memory-based methods have demonstrated impressive results in video object segmentation (VOS) recently. Nevertheless, due to the lack of instance understanding ability, the above approaches are oftentimes brittle to large appearance variations or viewpoint changes resulted from the movement of objects and cameras. In this paper, we argue that instance understanding matters in VOS, and integrating it with memory-based matching can enjoy the synergy, which is intuitively sensible from the definition of VOS task, \ie, identifying and segmenting object instances within the video. Towards this goal, we present a two-branch network for VOS, where the query-based instance segmentation (IS) branch delves into the instance details of the current frame and the VOS branch performs spatial-temporal matching with the memory bank. We employ the well-learned object queries from IS branch to inject instance-specific information into the query key, with which the instance-augmented matching is further performed. In addition, we introduce a multi-path fusion block to effectively combine the memory readout with multi-scale features from the instance segmentation decoder, which incorporates high-resolution instance-aware features to produce final segmentation results. Our method achieves state-of-the-art performance on DAVIS 2016/2017 val (92.6% and 87.1%), DAVIS 2017 test-dev (82.8%), and YouTube-VOS 2018/2019 val (86.3% and 86.3%), outperforming alternative methods by clear margins.
CLIP Itself is a Strong Fine-tuner: Achieving 85.7% and 88.0% Top-1 Accuracy with ViT-B and ViT-L on ImageNet
Dec 12, 2022



Recent studies have shown that CLIP has achieved remarkable success in performing zero-shot inference while its fine-tuning performance is not satisfactory. In this paper, we identify that fine-tuning performance is significantly impacted by hyper-parameter choices. We examine various key hyper-parameters and empirically evaluate their impact in fine-tuning CLIP for classification tasks through a comprehensive study. We find that the fine-tuning performance of CLIP is substantially underestimated. Equipped with hyper-parameter refinement, we demonstrate CLIP itself is better or at least competitive in fine-tuning compared with large-scale supervised pre-training approaches or latest works that use CLIP as prediction targets in Masked Image Modeling. Specifically, CLIP ViT-Base/16 and CLIP ViT-Large/14 can achieve 85.7%,88.0% finetuning Top-1 accuracy on the ImageNet-1K dataset . These observations challenge the conventional conclusion that CLIP is not suitable for fine-tuning, and motivate us to rethink recently proposed improvements based on CLIP. We will release our code publicly at \url{https://github.com/LightDXY/FT-CLIP}.
Masked Video Distillation: Rethinking Masked Feature Modeling for Self-supervised Video Representation Learning
Dec 08, 2022Benefiting from masked visual modeling, self-supervised video representation learning has achieved remarkable progress. However, existing methods focus on learning representations from scratch through reconstructing low-level features like raw pixel RGB values. In this paper, we propose masked video distillation (MVD), a simple yet effective two-stage masked feature modeling framework for video representation learning: firstly we pretrain an image (or video) model by recovering low-level features of masked patches, then we use the resulting features as targets for masked feature modeling. For the choice of teacher models, we observe that students taught by video teachers perform better on temporally-heavy video tasks, while image teachers transfer stronger spatial representations for spatially-heavy video tasks. Visualization analysis also indicates different teachers produce different learned patterns for students. Motivated by this observation, to leverage the advantage of different teachers, we design a spatial-temporal co-teaching method for MVD. Specifically, we distill student models from both video teachers and image teachers by masked feature modeling. Extensive experimental results demonstrate that video transformers pretrained with spatial-temporal co-teaching outperform models distilled with a single teacher on a multitude of video datasets. Our MVD with vanilla ViT achieves state-of-the-art performance compared with previous supervised or self-supervised methods on several challenging video downstream tasks. For example, with the ViT-Large model, our MVD achieves 86.4% and 75.9% Top-1 accuracy on Kinetics-400 and Something-Something-v2, outperforming VideoMAE by 1.2% and 1.6% respectively. Code will be available at \url{https://github.com/ruiwang2021/mvd}.
X-Paste: Revisit Copy-Paste at Scale with CLIP and StableDiffusion
Dec 07, 2022



Copy-Paste is a simple and effective data augmentation strategy for instance segmentation. By randomly pasting object instances onto new background images, it creates new training data for free and significantly boosts the segmentation performance, especially for rare object categories. Although diverse, high-quality object instances used in Copy-Paste result in more performance gain, previous works utilize object instances either from human-annotated instance segmentation datasets or rendered from 3D object models, and both approaches are too expensive to scale up to obtain good diversity. In this paper, we revisit Copy-Paste at scale with the power of newly emerged zero-shot recognition models (e.g., CLIP) and text2image models (e.g., StableDiffusion). We demonstrate for the first time that using a text2image model to generate images or zero-shot recognition model to filter noisily crawled images for different object categories is a feasible way to make Copy-Paste truly scalable. To make such success happen, we design a data acquisition and processing framework, dubbed "X-Paste", upon which a systematic study is conducted. On the LVIS dataset, X-Paste provides impressive improvements over the strong baseline CenterNet2 with Swin-L as the backbone. Specifically, it archives +2.6 box AP and +2.1 mask AP gains on all classes and even more significant gains with +6.8 box AP +6.5 mask AP on long-tail classes.
Robust Point Cloud Segmentation with Noisy Annotations
Dec 06, 2022



Point cloud segmentation is a fundamental task in 3D. Despite recent progress on point cloud segmentation with the power of deep networks, current learning methods based on the clean label assumptions may fail with noisy labels. Yet, class labels are often mislabeled at both instance-level and boundary-level in real-world datasets. In this work, we take the lead in solving the instance-level label noise by proposing a Point Noise-Adaptive Learning (PNAL) framework. Compared to noise-robust methods on image tasks, our framework is noise-rate blind, to cope with the spatially variant noise rate specific to point clouds. Specifically, we propose a point-wise confidence selection to obtain reliable labels from the historical predictions of each point. A cluster-wise label correction is proposed with a voting strategy to generate the best possible label by considering the neighbor correlations. To handle boundary-level label noise, we also propose a variant ``PNAL-boundary " with a progressive boundary label cleaning strategy. Extensive experiments demonstrate its effectiveness on both synthetic and real-world noisy datasets. Even with $60\%$ symmetric noise and high-level boundary noise, our framework significantly outperforms its baselines, and is comparable to the upper bound trained on completely clean data. Moreover, we cleaned the popular real-world dataset ScanNetV2 for rigorous experiment. Our code and data is available at https://github.com/pleaseconnectwifi/PNAL.
Improving Commonsense in Vision-Language Models via Knowledge Graph Riddles
Nov 29, 2022This paper focuses on analyzing and improving the commonsense ability of recent popular vision-language (VL) models. Despite the great success, we observe that existing VL-models still lack commonsense knowledge/reasoning ability (e.g., "Lemons are sour"), which is a vital component towards artificial general intelligence. Through our analysis, we find one important reason is that existing large-scale VL datasets do not contain much commonsense knowledge, which motivates us to improve the commonsense of VL-models from the data perspective. Rather than collecting a new VL training dataset, we propose a more scalable strategy, i.e., "Data Augmentation with kNowledge graph linearization for CommonsensE capability" (DANCE). It can be viewed as one type of data augmentation technique, which can inject commonsense knowledge into existing VL datasets on the fly during training. More specifically, we leverage the commonsense knowledge graph (e.g., ConceptNet) and create variants of text description in VL datasets via bidirectional sub-graph sequentialization. For better commonsense evaluation, we further propose the first retrieval-based commonsense diagnostic benchmark. By conducting extensive experiments on some representative VL-models, we demonstrate that our DANCE technique is able to significantly improve the commonsense ability while maintaining the performance on vanilla retrieval tasks. The code and data are available at https://github.com/pleaseconnectwifi/DANCE
Self-Supervised Learning based on Heat Equation
Nov 23, 2022This paper presents a new perspective of self-supervised learning based on extending heat equation into high dimensional feature space. In particular, we remove time dependence by steady-state condition, and extend the remaining 2D Laplacian from x--y isotropic to linear correlated. Furthermore, we simplify it by splitting x and y axes as two first-order linear differential equations. Such simplification explicitly models the spatial invariance along horizontal and vertical directions separately, supporting prediction across image blocks. This introduces a very simple masked image modeling (MIM) method, named QB-Heat. QB-Heat leaves a single block with size of quarter image unmasked and extrapolates other three masked quarters linearly. It brings MIM to CNNs without bells and whistles, and even works well for pre-training light-weight networks that are suitable for both image classification and object detection without fine-tuning. Compared with MoCo-v2 on pre-training a Mobile-Former with 5.8M parameters and 285M FLOPs, QB-Heat is on par in linear probing on ImageNet, but clearly outperforms in non-linear probing that adds a transformer block before linear classifier (65.6% vs. 52.9%). When transferring to object detection with frozen backbone, QB-Heat outperforms MoCo-v2 and supervised pre-training on ImageNet by 7.9 and 4.5 AP respectively. This work provides an insightful hypothesis on the invariance within visual representation over different shapes and textures: the linear relationship between horizontal and vertical derivatives. The code will be publicly released.
SinDiffusion: Learning a Diffusion Model from a Single Natural Image
Nov 22, 2022We present SinDiffusion, leveraging denoising diffusion models to capture internal distribution of patches from a single natural image. SinDiffusion significantly improves the quality and diversity of generated samples compared with existing GAN-based approaches. It is based on two core designs. First, SinDiffusion is trained with a single model at a single scale instead of multiple models with progressive growing of scales which serves as the default setting in prior work. This avoids the accumulation of errors, which cause characteristic artifacts in generated results. Second, we identify that a patch-level receptive field of the diffusion network is crucial and effective for capturing the image's patch statistics, therefore we redesign the network structure of the diffusion model. Coupling these two designs enables us to generate photorealistic and diverse images from a single image. Furthermore, SinDiffusion can be applied to various applications, i.e., text-guided image generation, and image outpainting, due to the inherent capability of diffusion models. Extensive experiments on a wide range of images demonstrate the superiority of our proposed method for modeling the patch distribution.
PointCAT: Contrastive Adversarial Training for Robust Point Cloud Recognition
Sep 16, 2022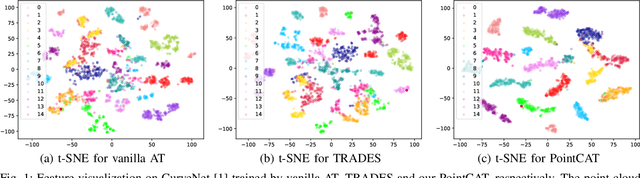
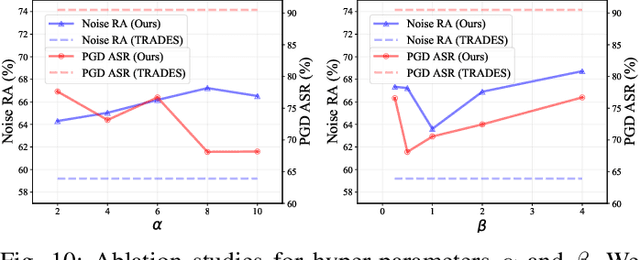
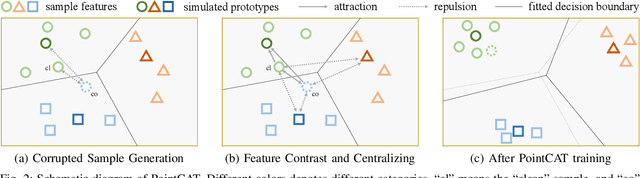
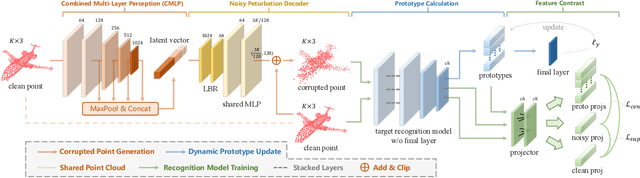
Notwithstanding the prominent performance achieved in various applications, point cloud recognition models have often suffered from natural corruptions and adversarial perturbations. In this paper, we delve into boosting the general robustness of point cloud recognition models and propose Point-Cloud Contrastive Adversarial Training (PointCAT). The main intuition of PointCAT is encouraging the target recognition model to narrow the decision gap between clean point clouds and corrupted point clouds. Specifically, we leverage a supervised contrastive loss to facilitate the alignment and uniformity of the hypersphere features extracted by the recognition model, and design a pair of centralizing losses with the dynamic prototype guidance to avoid these features deviating from their belonging category clusters. To provide the more challenging corrupted point clouds, we adversarially train a noise generator along with the recognition model from the scratch, instead of using gradient-based attack as the inner loop like previous adversarial training methods. Comprehensive experiments show that the proposed PointCAT outperforms the baseline methods and dramatically boosts the robustness of different point cloud recognition models, under a variety of corruptions including isotropic point noises, the LiDAR simulated noises, random point dropping and adversarial perturbations.
OmniVL:One Foundation Model for Image-Language and Video-Language Tasks
Sep 15, 2022
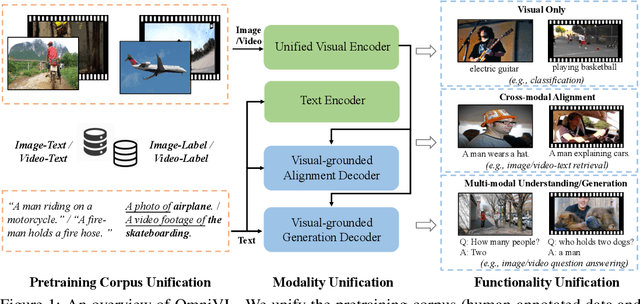
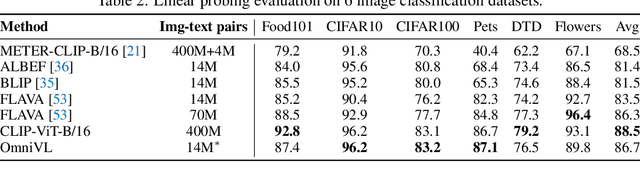
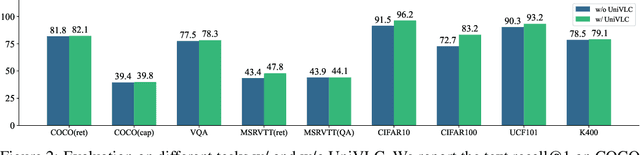
This paper presents OmniVL, a new foundation model to support both image-language and video-language tasks using one universal architecture. It adopts a unified transformer-based visual encoder for both image and video inputs, and thus can perform joint image-language and video-language pretraining. We demonstrate, for the first time, such a paradigm benefits both image and video tasks, as opposed to the conventional one-directional transfer (e.g., use image-language to help video-language). To this end, we propose a decoupled joint pretraining of image-language and video-language to effectively decompose the vision-language modeling into spatial and temporal dimensions and obtain performance boost on both image and video tasks. Moreover, we introduce a novel unified vision-language contrastive (UniVLC) loss to leverage image-text, video-text, image-label (e.g., image classification), video-label (e.g., video action recognition) data together, so that both supervised and noisily supervised pretraining data are utilized as much as possible. Without incurring extra task-specific adaptors, OmniVL can simultaneously support visual only tasks (e.g., image classification, video action recognition), cross-modal alignment tasks (e.g., image/video-text retrieval), and multi-modal understanding and generation tasks (e.g., image/video question answering, captioning). We evaluate OmniVL on a wide range of downstream tasks and achieve state-of-the-art or competitive results with similar model size and data scale.