 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust, But Verify: A Self-Verification Approach to Reinforcement Learning with Verifiable Rewards
May 19, 2025Large Language Models (LLMs) show great promise in complex reasoning, with Reinforcement Learning with Verifiable Rewards (RLVR) being a key enhancement strategy. However, a prevalent issue is ``superficial self-reflection'', where models fail to robustly verify their own outputs. We introduce RISE (Reinforcing Reasoning with Self-Verification), a novel online RL framework designed to tackle this. RISE explicitly and simultaneously trains an LLM to improve both its problem-solving and self-verification abilities within a single, integrated RL process. The core mechanism involves leveraging verifiable rewards from an outcome verifier to provide on-the-fly feedback for both solution generation and self-verification tasks. In each iteration, the model generates solutions, then critiques its own on-policy generated solutions, with both trajectories contributing to the policy update. Extensive experiments on diverse mathematical reasoning benchmarks show that RISE consistently improves model's problem-solving accuracy while concurrently fostering strong self-verification skills. Our analyses highlight the advantages of online verification and the benefits of increased verification compute. Additionally, RISE models exhibit more frequent and accurate self-verification behaviors during reasoning. These advantages reinforce RISE as a flexible and effective path towards developing more robust and self-aware reasoners.
Hearing from Silence: Reasoning Audio Descriptions from Silent Videos via Vision-Language Model
May 19, 2025Humans can intuitively infer sounds from silent videos, but whether multimodal large language models can perform modal-mismatch reasoning without accessing target modalities remains relatively unexplored. Current text-assisted-video-to-audio (VT2A) methods excel in video foley tasks but struggle to acquire audio descriptions during inference. We introduce the task of Reasoning Audio Descriptions from Silent Videos (SVAD) to address this challenge and investigate vision-language models' (VLMs) capabilities on this task. To further enhance the VLMs' reasoning capacity for the SVAD task, we construct a CoT-AudioCaps dataset and propose a Chain-of-Thought-based supervised fine-tuning strategy. Experiments on SVAD and subsequent VT2A tasks demonstrate our method's effectiveness in two key aspects: significantly improving VLMs' modal-mismatch reasoning for SVAD and effectively addressing the challenge of acquiring audio descriptions during VT2A inference.
MPS-Prover: Advancing Stepwise Theorem Proving by Multi-Perspective Search and Data Curation
May 16, 2025Automated Theorem Proving (ATP) in formal languages remains a formidable challenge in AI, demanding rigorous logical deduction and navigating vast search spaces. While large language models (LLMs) have shown promising performance, existing stepwise provers often suffer from biased search guidance, leading to inefficiencies and suboptimal proof strategies. This paper introduces the Multi-Perspective Search Prover (MPS-Prover), a novel stepwise ATP system designed to overcome these limitations. MPS-Prover incorporates two key innovations: a highly effective post-training data curation strategy that prunes approximately 40% of redundant training data without sacrificing performance, and a multi-perspective tree search mechanism. This search integrates a learned critic model with strategically designed heuristic rules to diversify tactic selection, prevent getting trapped in unproductive states, and enhance search robustness. Extensive evaluations demonstrate that MPS-Prover achieves state-of-the-art performance on multiple challenging benchmarks, including miniF2F and ProofNet, outperforming prior 7B parameter models. Furthermore, our analyses reveal that MPS-Prover generates significantly shorter and more diverse proofs compared to existing stepwise and whole-proof methods, highlighting its efficiency and efficacy. Our work advances the capabilities of LLM-based formal reasoning and offers a robust framework and a comprehensive analysis for developing more powerful theorem provers.
Recall with Reasoning: Chain-of-Thought Distillation for Mamba's Long-Context Memory and Extrapolation
May 06, 2025Mamba's theoretical infinite-context potential is limited in practice when sequences far exceed training lengths. This work explores unlocking Mamba's long-context memory ability by a simple-yet-effective method, Recall with Reasoning (RwR), by distilling chain-of-thought (CoT) summarization from a teacher model. Specifically, RwR prepends these summarization as CoT prompts during fine-tuning, teaching Mamba to actively recall and reason over long contexts. Experiments on LONGMEMEVAL and HELMET show RwR boosts Mamba's long-context performance against comparable Transformer/hybrid baselines under similar pretraining conditions, while preserving short-context capabilities, all without architectural changes.
WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model
Apr 23, 2025Agent self-improvement, where the backbone Large Language Model (LLM) of the agent are trained on trajectories sampled autonomously based on their own policies, has emerged as a promising approach for enhancing performance. Recent advancements, particularly in web environments, face a critical limitation: their performance will reach a stagnation point during autonomous learning cycles, hindering further improvement. We argue that this stems from limited exploration of the web environment and insufficient exploitation of pre-trained web knowledge in LLMs. To improve the performance of self-improvement, we propose a novel framework that introduces a co-evolving World Model LLM. This world model predicts the next observation based on the current observation and action within the web environment. Leveraging LLMs' pretrained knowledge of abundant web content, the World Model serves dual roles: (1) as a virtual web server generating self-instructed training data to continuously refine the agent's policy, and (2) as an imagination engine during inference, enabling look-ahead simulation to guide action selection for the agent LLM. Experiments in real-world web environments (Mind2Web-Live, WebVoyager, and GAIA-web) show a 10% performance gain over existing self-evolving agents, demonstrating the efficacy and generalizability of our approach, without using any distillation from more powerful close-sourced models. Our work establishes the necessity of integrating world models into autonomous agent frameworks to unlock sustained adaptability.
Enhancing Web Agents with Explicit Rollback Mechanisms
Apr 16, 2025With recent advancements in large language models, web agents have been greatly improved. However, dealing with complex and dynamic web environments requires more advanced planning and search abilities. Previous studies usually adopt a greedy one-way search strategy, which may struggle to recover from erroneous states. In this work, we enhance web agents with an explicit rollback mechanism, enabling the agent to revert back to a previous state in its navigation trajectory. This mechanism gives the model the flexibility to directly control the search process, leading to an effective and efficient web navigation method. We conduct experiments on two live web navigation benchmarks with zero-shot and fine-tuning settings. The results demonstrate the effectiveness of our proposed approach.
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning
Apr 15, 2025



The capacity for complex mathematical reasoning is a key benchmark for artificial intelligence. While reinforcement learning (RL) applied to LLMs shows promise, progress is significantly hindered by the lack of large-scale training data that is sufficiently challenging, possesses verifiable answer formats suitable for RL, and is free from contamination with evaluation benchmarks. To address these limitations, we introduce DeepMath-103K, a new, large-scale dataset comprising approximately 103K mathematical problems, specifically designed to train advanced reasoning models via RL. DeepMath-103K is curated through a rigorous pipeline involving source analysis, stringent decontamination against numerous benchmarks, and filtering for high difficulty (primarily Levels 5-9), significantly exceeding existing open resources in challenge. Each problem includes a verifiable final answer, enabling rule-based RL, and three distinct R1-generated solutions suitable for diverse training paradigms like supervised fine-tuning or distillation. Spanning a wide range of mathematical topics, DeepMath-103K promotes the development of generalizable reasoning. We demonstrate that models trained on DeepMath-103K achieve significant improvements on challenging mathematical benchmarks, validating its effectiveness. We release DeepMath-103K publicly to facilitate community progress in building more capable AI reasoning systems: https://github.com/zwhe99/DeepMath.
Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains
Apr 01, 2025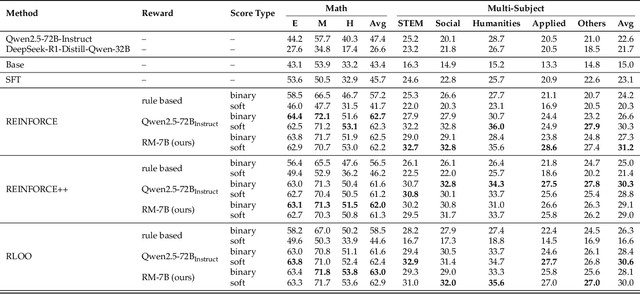
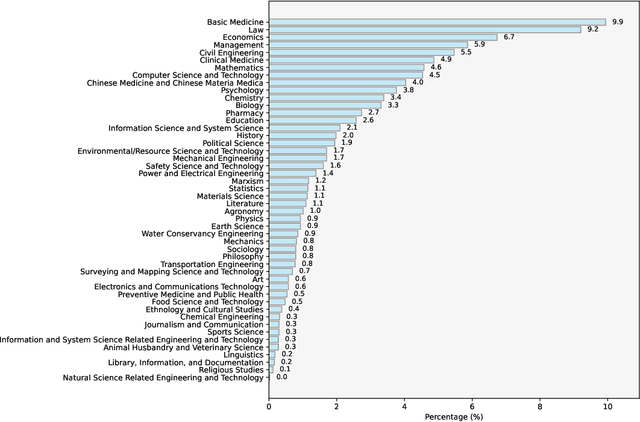
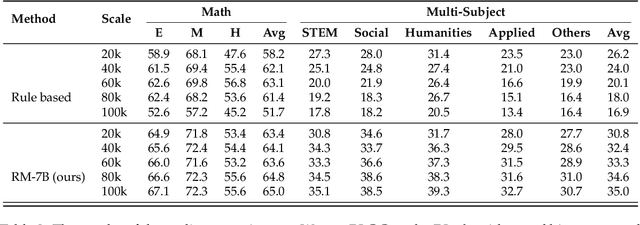

Reinforcement learning with verifiable rewards (RLVR) has demonstrated significant success in enhancing mathematical reasoning and coding performance of large language models (LLMs), especially when structured reference answers are accessible for verification. However, its extension to broader, less structured domains remains unexplored. In this work, we investigate the effectiveness and scalability of RLVR across diverse real-world domains including medicine, chemistry, psychology, economics, and education, where structured reference answers are typically unavailable. We reveal that binary verification judgments on broad-domain tasks exhibit high consistency across various LLMs provided expert-written reference answers exist. Motivated by this finding, we utilize a generative scoring technique that yields soft, model-based reward signals to overcome limitations posed by binary verifications, especially in free-form, unstructured answer scenarios. We further demonstrate the feasibility of training cross-domain generative reward models using relatively small (7B) LLMs without the need for extensive domain-specific annotation. Through comprehensive experiments, our RLVR framework establishes clear performance gains, significantly outperforming state-of-the-art open-source aligned models such as Qwen2.5-72B and DeepSeek-R1-Distill-Qwen-32B across domains in free-form settings. Our approach notably enhances the robustness, flexibility, and scalability of RLVR, representing a substantial step towards practical reinforcement learning applications in complex, noisy-label scenarios.
Dancing with Critiques: Enhancing LLM Reasoning with Stepwise Natural Language Self-Critique
Mar 21, 2025



Enhancing the reasoning capabilities of large language models (LLMs), particularly for complex tasks requiring multi-step logical deductions, remains a significant challenge. Traditional inference time scaling methods utilize scalar reward signals from process reward models to evaluate candidate reasoning steps, but these scalar rewards lack the nuanced qualitative information essential for understanding and justifying each step. In this paper, we propose a novel inference-time scaling approach -- stepwise natural language self-critique (PANEL), which employs self-generated natural language critiques as feedback to guide the step-level search process. By generating rich, human-readable critiques for each candidate reasoning step, PANEL retains essential qualitative information, facilitating better-informed decision-making during inference. This approach bypasses the need for task-specific verifiers and the associated training overhead, making it broadly applicable across diverse tasks. Experimental results on challenging reasoning benchmarks, including AIME and GPQA, demonstrate that PANEL significantly enhances reasoning performance, outperforming traditional scalar reward-based methods. Our code is available at https://github.com/puddingyeah/PANEL to support and encourage future research in this promising field.
FNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Mar 17, 2025The current dominant approach for neural speech enhancement relies on purely-supervised deep learning using simulated pairs of far-field noisy-reverberant speech (mixtures) and clean speech. However, these trained models often exhibit limited generalizability to real-recorded mixtures. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a novel framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce a novel evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.