 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge'1'-bit Count-based Sorting Unit to Reduce Link Power in DNN Accelerators
Jan 20, 2026Interconnect power consumption remains a bottleneck in Deep Neural Network (DNN) accelerators. While ordering data based on '1'-bit counts can mitigate this via reduced switching activity, practical hardware sorting implementations remain underexplored. This work proposes the hardware implementation of a comparison-free sorting unit optimized for Convolutional Neural Networks (CNN). By leveraging approximate computing to group population counts into coarse-grained buckets, our design achieves hardware area reductions while preserving the link power benefits of data reordering. Our approximate sorting unit achieves up to 35.4% area reduction while maintaining 19.50\% BT reduction compared to 20.42% of precise implementation.
FNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Mar 17, 2025The current dominant approach for neural speech enhancement relies on purely-supervised deep learning using simulated pairs of far-field noisy-reverberant speech (mixtures) and clean speech. However, these trained models often exhibit limited generalizability to real-recorded mixtures. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a novel framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce a novel evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.
A text-based, generative deep learning model for soil reflectance spectrum simulation in the VIS-NIR bands
May 02, 2024Simulating soil reflectance spectra is invaluable for soil-plant radiative modeling and training machine learning models, yet it is difficult as the intricate relationships between soil structure and its constituents. To address this, a fully data-driven soil optics generative model (SOGM) for simulation of soil reflectance spectra based on soil property inputs was developed. The model is trained on an extensive dataset comprising nearly 180,000 soil spectra-property pairs from 17 datasets. It generates soil reflectance spectra from text-based inputs describing soil properties and their values rather than only numerical values and labels in binary vector format. The generative model can simulate output spectra based on an incomplete set of input properties. SOGM is based on the denoising diffusion probabilistic model (DDPM). Two additional sub-models were also built to complement the SOGM: a spectral padding model that can fill in the gaps for spectra shorter than the full visible-near-infrared range (VIS-NIR; 400 to 2499 nm), and a wet soil spectra model that can estimate the effects of water content on soil reflectance spectra given the dry spectrum predicted by the SOGM. The SOGM was up-scaled by coupling with the Helios 3D plant modeling software, which allowed for generation of synthetic aerial images of simulated soil and plant scenes. It can also be easily integrated with soil-plant radiation model used for remote sensin research like PROSAIL. The testing results of the SOGM on new datasets that not included in model training proved that the model can generate reasonable soil reflectance spectra based on available property inputs. The presented models are openly accessible on: https://github.com/GEMINI-Breeding/SOGM_soil_spectra_simulation.
Harmonic enhancement using learnable comb filter for light-weight full-band speech enhancement model
Jun 01, 2023



With fewer feature dimensions, filter banks are often used in light-weight full-band speech enhancement models. In order to further enhance the coarse speech in the sub-band domain, it is necessary to apply a post-filtering for harmonic retrieval. The signal processing-based comb filters used in RNNoise and PercepNet have limited performance and may cause speech quality degradation due to inaccurate fundamental frequency estimation. To tackle this problem, we propose a learnable comb filter to enhance harmonics. Based on the sub-band model, we design a DNN-based fundamental frequency estimator to estimate the discrete fundamental frequencies and a comb filter for harmonic enhancement, which are trained via an end-to-end pattern. The experiments show the advantages of our proposed method over PecepNet and DeepFilterNet.
Inference skipping for more efficient real-time speech enhancement with parallel RNNs
Jul 22, 2022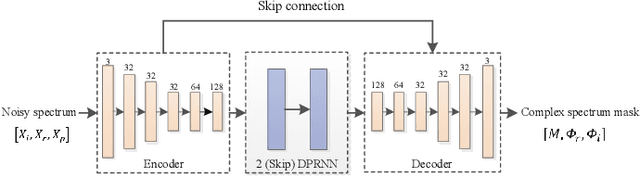
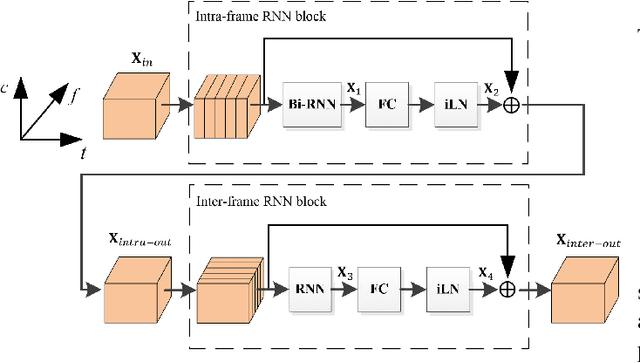
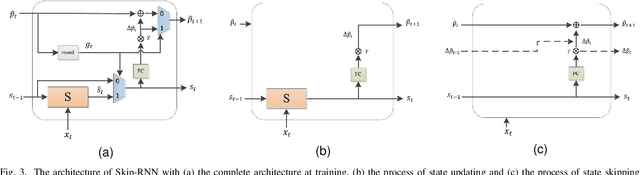
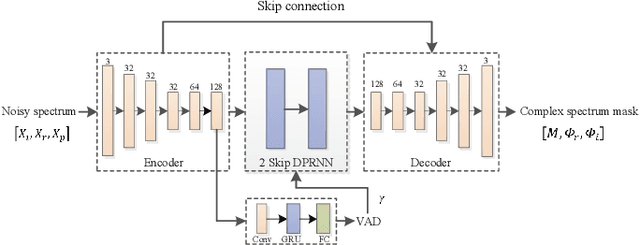
Deep neural network (DNN) based speech enhancement models have attracted extensive attention due to their promising performance. However, it is difficult to deploy a powerful DNN in real-time applications because of its high computational cost. Typical compression methods such as pruning and quantization do not make good use of the data characteristics. In this paper, we introduce the Skip-RNN strategy into speech enhancement models with parallel RNNs. The states of the RNNs update intermittently without interrupting the update of the output mask, which leads to significant reduction of computational load without evident audio artifacts. To better leverage the difference between the voice and the noise, we further regularize the skipping strategy with voice activity detection (VAD) guidance, saving more computational load. Experiments on a high-performance speech enhancement model, dual-path convolutional recurrent network (DPCRN), show the superiority of our strategy over strategies like network pruning or directly training a smaller model. We also validate the generalization of the proposed strategy on two other competitive speech enhancement models.