 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBHN-Net: Dual-Branch Hybrid Neural Network For Low-Complexity Monaural Speech Enhancement
Jun 04, 2026Although artificial neural network (ANN) based speech enhancement (SE) methods demonstrate excellent performance, the high computational complexity and high energy consumption hinder their deployment in practical front-end processing tasks.} Currently, the spiking neural networks (SNNs) have shown potential in reducing power consumption. However, the discrete binary activation and complex spatio-temporal dynamics of SNNs often result in information loss. The current challenge therefore focuses on how to maintain performance and reduce computational complexity. To address this issue, this work propose a Dual-Branch Hybrid Neural (DBHN) Network. 1) In terms of network architecture: A dual-branch network integrating ANN and SNN was designed, where the SNN branch reduces power consumption while the ANN branch addresses information loss; The BandSplit and Time-Frequency (TF) -Mamba modules were developed to simultaneously compress energy consumption and enhance model performance; Spiking Feature Extraction Group (SFEG) and Information Transformation Block (ITB) components were implemented with residual connections to mitigate information loss while further refining feature representations. 2) To facilitate inter-branch information fusion: An Interaction module was designed to promote information exchange at various stages of the dual-branch network; A TF-Cross Attention-Fusion module was designed to perform time-frequency domain fusion of dual-branch information while data-adaptively guiding the SNN branch to retain more critical information. Results show that the proposed model maintains superior performance across three public datasets while achieving an average 7.5 fold reduction in computational complexity compared to baseline models.
* This article has been accepted for publication in IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI)
SLD-L2S: Hierarchical Subspace Latent Diffusion for High-Fidelity Lip to Speech Synthesis
Feb 12, 2026Although lip-to-speech synthesis (L2S) has achieved significant progress in recent years, current state-of-the-art methods typically rely on intermediate representations such as mel-spectrograms or discrete self-supervised learning (SSL) tokens. The potential of latent diffusion models (LDMs) in this task remains largely unexplored. In this paper, we introduce SLD-L2S, a novel L2S framework built upon a hierarchical subspace latent diffusion model. Our method aims to directly map visual lip movements to the continuous latent space of a pre-trained neural audio codec, thereby avoiding the information loss inherent in traditional intermediate representations. The core of our method is a hierarchical architecture that processes visual representations through multiple parallel subspaces, initiated by a subspace decomposition module. To efficiently enhance interactions within and between these subspaces, we design the diffusion convolution block (DiCB) as our network backbone. Furthermore, we employ a reparameterized flow matching technique to directly generate the target latent vectors. This enables a principled inclusion of speech language model (SLM) and semantic losses during training, moving beyond conventional flow matching objectives and improving synthesized speech quality. Our experiments show that SLD-L2S achieves state-of-the-art generation quality on multiple benchmark datasets, surpassing existing methods in both objective and subjective evaluations.
Spiking Vocos: An Energy-Efficient Neural Vocoder
Sep 16, 2025Despite the remarkable progress in the synthesis speed and fidelity of neural vocoders, their high energy consumption remains a critical barrier to practical deployment on computationally restricted edge devices. Spiking Neural Networks (SNNs), widely recognized for their high energy efficiency due to their event-driven nature, offer a promising solution for low-resource scenarios. In this paper, we propose Spiking Vocos, a novel spiking neural vocoder with ultra-low energy consumption, built upon the efficient Vocos framework. To mitigate the inherent information bottleneck in SNNs, we design a Spiking ConvNeXt module to reduce Multiply-Accumulate (MAC) operations and incorporate an amplitude shortcut path to preserve crucial signal dynamics. Furthermore, to bridge the performance gap with its Artificial Neural Network (ANN) counterpart, we introduce a self-architectural distillation strategy to effectively transfer knowledge. A lightweight Temporal Shift Module is also integrated to enhance the model's ability to fuse information across the temporal dimension with negligible computational overhead. Experiments demonstrate that our model achieves performance comparable to its ANN counterpart, with UTMOS and PESQ scores of 3.74 and 3.45 respectively, while consuming only 14.7% of the energy. The source code is available at https://github.com/pymaster17/Spiking-Vocos.
FNSE-SBGAN: Far-field Speech Enhancement with Schrodinger Bridge and Generative Adversarial Networks
Mar 17, 2025The current dominant approach for neural speech enhancement relies on purely-supervised deep learning using simulated pairs of far-field noisy-reverberant speech (mixtures) and clean speech. However, these trained models often exhibit limited generalizability to real-recorded mixtures. To address this issue, this study investigates training enhancement models directly on real mixtures. Specifically, we revisit the single-channel far-field to near-field speech enhancement (FNSE) task, focusing on real-world data characterized by low signal-to-noise ratio (SNR), high reverberation, and mid-to-high frequency attenuation. We propose FNSE-SBGAN, a novel framework that integrates a Schrodinger Bridge (SB)-based diffusion model with generative adversarial networks (GANs). Our approach achieves state-of-the-art performance across various metrics and subjective evaluations, significantly reducing the character error rate (CER) by up to 14.58% compared to far-field signals. Experimental results demonstrate that FNSE-SBGAN preserves superior subjective quality and establishes a new benchmark for real-world far-field speech enhancement. Additionally, we introduce a novel evaluation framework leveraging matrix rank analysis in the time-frequency domain, providing systematic insights into model performance and revealing the strengths and weaknesses of different generative methods.
NaturalL2S: End-to-End High-quality Multispeaker Lip-to-Speech Synthesis with Differential Digital Signal Processing
Feb 17, 2025



Recent advancements in visual speech recognition (VSR) have promoted progress in lip-to-speech synthesis, where pre-trained VSR models enhance the intelligibility of synthesized speech by providing valuable semantic information. The success achieved by cascade frameworks, which combine pseudo-VSR with pseudo-text-to-speech (TTS) or implicitly utilize the transcribed text, highlights the benefits of leveraging VSR models. However, these methods typically rely on mel-spectrograms as an intermediate representation, which may introduce a key bottleneck: the domain gap between synthetic mel-spectrograms, generated from inherently error-prone lip-to-speech mappings, and real mel-spectrograms used to train vocoders. This mismatch inevitably degrades synthesis quality. To bridge this gap, we propose Natural Lip-to-Speech (NaturalL2S), an end-to-end framework integrating acoustic inductive biases with differentiable speech generation components. Specifically, we introduce a fundamental frequency (F0) predictor to capture prosodic variations in synthesized speech. The predicted F0 then drives a Differentiable Digital Signal Processing (DDSP) synthesizer to generate a coarse signal which serves as prior information for subsequent speech synthesis. Additionally, instead of relying on a reference speaker embedding as an auxiliary input, our approach achieves satisfactory performance on speaker similarity without explicitly modelling speaker characteristics. Both objective and subjective evaluation results demonstrate that NaturalL2S can effectively enhance the quality of the synthesized speech when compared to state-of-the-art methods. Our demonstration page is accessible at https://yifan-liang.github.io/NaturalL2S/.
BSDB-Net: Band-Split Dual-Branch Network with Selective State Spaces Mechanism for Monaural Speech Enhancement
Dec 26, 2024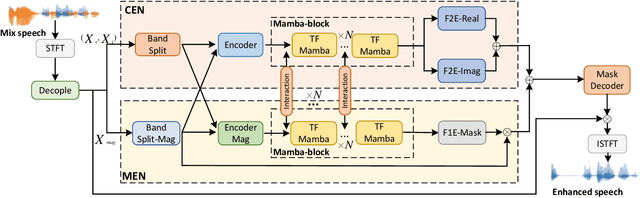
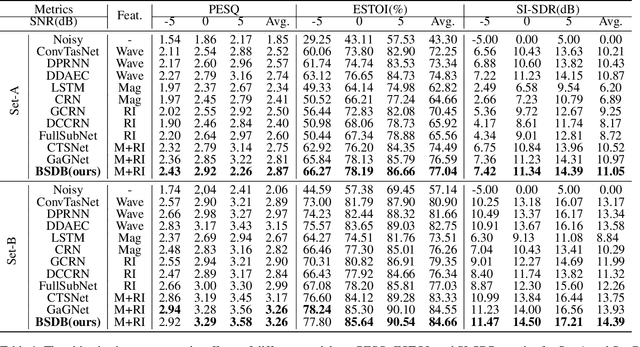
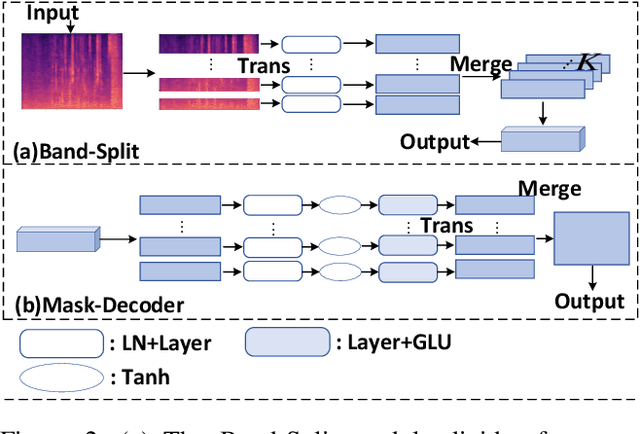
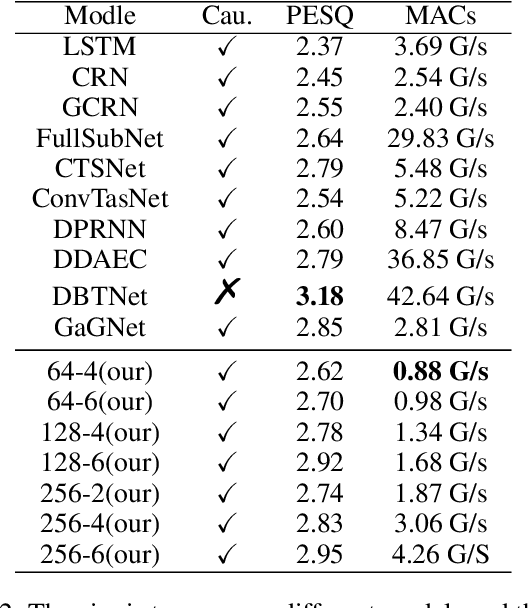
Although the complex spectrum-based speech enhancement(SE) methods have achieved significant performance, coupling amplitude and phase can lead to a compensation effect, where amplitude information is sacrificed to compensate for the phase that is harmful to SE. In addition, to further improve the performance of SE, many modules are stacked onto SE, resulting in increased model complexity that limits the application of SE. To address these problems, we proposed a dual-path network based on compressed frequency using Mamba. First, we extract amplitude and phase information through parallel dual branches. This approach leverages structured complex spectra to implicitly capture phase information and solves the compensation effect by decoupling amplitude and phase, and the network incorporates an interaction module to suppress unnecessary parts and recover missing components from the other branch. Second, to reduce network complexity, the network introduces a band-split strategy to compress the frequency dimension. To further reduce complexity while maintaining good performance, we designed a Mamba-based module that models the time and frequency dimensions under linear complexity. Finally, compared to baselines, our model achieves an average 8.3 times reduction in computational complexity while maintaining superior performance. Furthermore, it achieves a 25 times reduction in complexity compared to transformer-based models.
Array2BR: An End-to-End Noise-immune Binaural Audio Synthesis from Microphone-array Signals
Oct 08, 2024



Telepresence technology aims to provide an immersive virtual presence for remote conference applications, and it is extremely important to synthesize high-quality binaural audio signals for this aim. Because the ambient noise is often inevitable in practical application scenarios, it is highly desired that binaural audio signals without noise can be obtained from microphone-array signals directly. For this purpose, this paper proposes a new end-to-end noise-immune binaural audio synthesis framework from microphone-array signals, abbreviated as Array2BR, and experimental results show that binaural cues can be correctly mapped and noise can be well suppressed simultaneously using the proposed framework. Compared with existing methods, the proposed method achieved better performance in terms of both objective and subjective metric scores.
SMRU: Split-and-Merge Recurrent-based UNet for Acoustic Echo Cancellation and Noise Suppression
Jun 17, 2024The proliferation of deep neural networks has spawned the rapid development of acoustic echo cancellation and noise suppression, and plenty of prior arts have been proposed, which yield promising performance. Nevertheless, they rarely consider the deployment generality in different processing scenarios, such as edge devices, and cloud processing. To this end, this paper proposes a general model, termed SMRU, to cover different application scenarios. The novelty lies in two-fold. First, a multi-scale band split layer and band merge layer are proposed to effectively fuse local frequency bands for lower complexity modeling. Besides, by simulating the multi-resolution feature modeling characteristic of the classical UNet structure, a novel recurrent-dominated UNet is devised. It consists of multiple variable frame rate blocks, each of which involves the causal time down-/up-sampling layer with varying compression ratios and the dual-path structure for inter- and intra-band modeling. The model is configured from 50 M/s to 6.8 G/s in terms of MACs, and the experimental results show that the proposed approach yields competitive or even better performance over existing baselines, and has the full potential to adapt to more general scenarios with varying complexity requirements.
Gesper: A Restoration-Enhancement Framework for General Speech Reconstruction
Jun 14, 2023This paper describes a real-time General Speech Reconstruction (Gesper) system submitted to the ICASSP 2023 Speech Signal Improvement (SSI) Challenge. This novel proposed system is a two-stage architecture, in which the speech restoration is performed, and then cascaded by speech enhancement. We propose a complex spectral mapping-based generative adversarial network (CSM-GAN) as the speech restoration module for the first time. For noise suppression and dereverberation, the enhancement module is performed with fullband-wideband parallel processing. On the blind test set of ICASSP 2023 SSI Challenge, the proposed Gesper system, which satisfies the real-time condition, achieves 3.27 P.804 overall mean opinion score (MOS) and 3.35 P.835 overall MOS, ranked 1st in both track 1 and track 2.
TaylorBeamixer: Learning Taylor-Inspired All-Neural Multi-Channel Speech Enhancement from Beam-Space Dictionary Perspective
Nov 30, 2022Despite the promising performance of existing frame-wise all-neural beamformers in the speech enhancement field, it remains unclear what the underlying mechanism exists. In this paper, we revisit the beamforming behavior from the beam-space dictionary perspective and formulate it into the learning and mixing of different beam-space components. Based on that, we propose an all-neural beamformer called TaylorBM to simulate Taylor's series expansion operation in which the 0th-order term serves as a spatial filter to conduct the beam mixing, and several high-order terms are tasked with residual noise cancellation for post-processing. The whole system is devised to work in an end-to-end manner. Experiments are conducted on the spatialized LibriSpeech corpus and results show that the proposed approach outperforms existing advanced baselines in terms of evaluation metrics.