 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Pruning: Improving Neural Network Efficiency with Federated Learning
Sep 14, 2022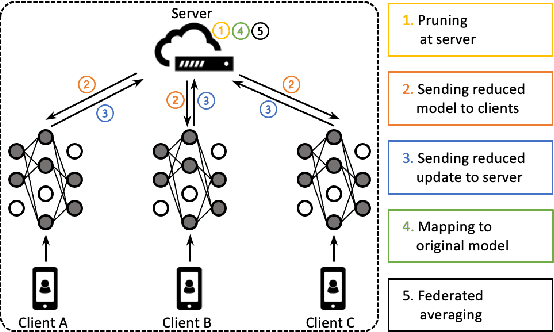
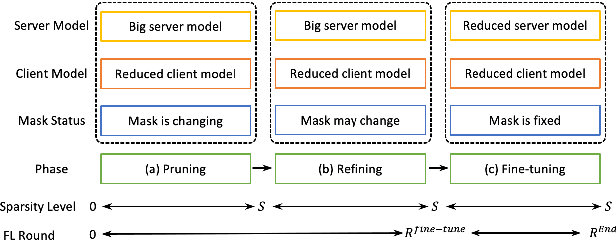
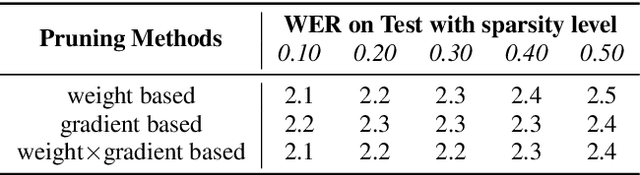
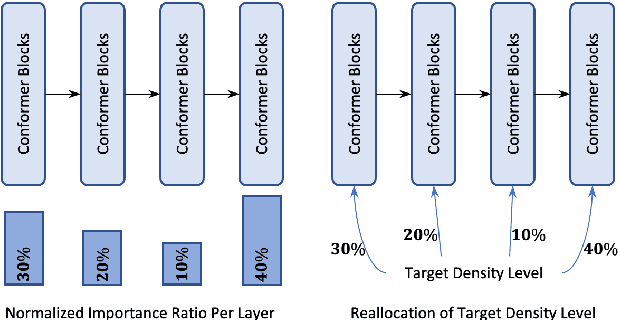
Automatic Speech Recognition models require large amount of speech data for training, and the collection of such data often leads to privacy concerns. Federated learning has been widely used and is considered to be an effective decentralized technique by collaboratively learning a shared prediction model while keeping the data local on different clients devices. However, the limited computation and communication resources on clients devices present practical difficulties for large models. To overcome such challenges, we propose Federated Pruning to train a reduced model under the federated setting, while maintaining similar performance compared to the full model. Moreover, the vast amount of clients data can also be leveraged to improve the pruning results compared to centralized training. We explore different pruning schemes and provide empirical evidence of the effectiveness of our methods.
Privacy of Autonomous Vehicles: Risks, Protection Methods, and Future Directions
Sep 08, 2022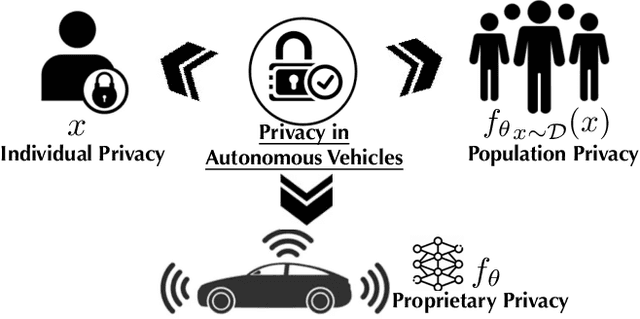
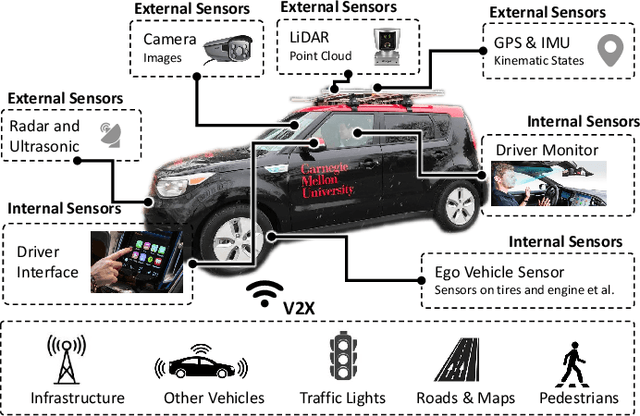
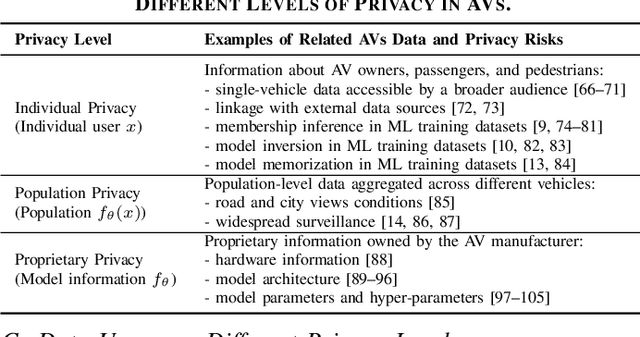
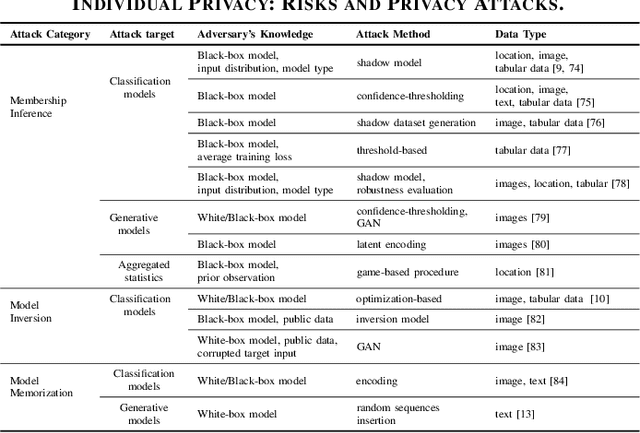
Recent advances in machine learning have enabled its wide application in different domains, and one of the most exciting applications is autonomous vehicles (AVs), which have encouraged the development of a number of ML algorithms from perception to prediction to planning. However, training AVs usually requires a large amount of training data collected from different driving environments (e.g., cities) as well as different types of personal information (e.g., working hours and routes). Such collected large data, treated as the new oil for ML in the data-centric AI era, usually contains a large amount of privacy-sensitive information which is hard to remove or even audit. Although existing privacy protection approaches have achieved certain theoretical and empirical success, there is still a gap when applying them to real-world applications such as autonomous vehicles. For instance, when training AVs, not only can individually identifiable information reveal privacy-sensitive information, but also population-level information such as road construction within a city, and proprietary-level commercial secrets of AVs. Thus, it is critical to revisit the frontier of privacy risks and corresponding protection approaches in AVs to bridge this gap. Following this goal, in this work, we provide a new taxonomy for privacy risks and protection methods in AVs, and we categorize privacy in AVs into three levels: individual, population, and proprietary. We explicitly list out recent challenges to protect each of these levels of privacy, summarize existing solutions to these challenges, discuss the lessons and conclusions, and provide potential future directions and opportunities for both researchers and practitioners. We believe this work will help to shape the privacy research in AV and guide the privacy protection technology design.
An Empirical Exploration of Cross-domain Alignment between Language and Electroencephalogram
Aug 21, 2022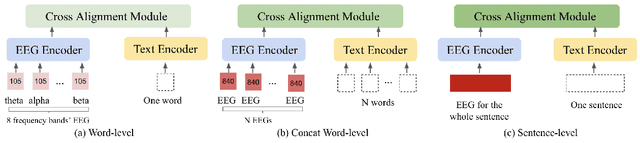
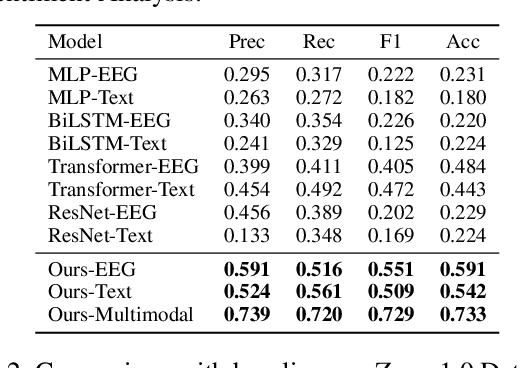
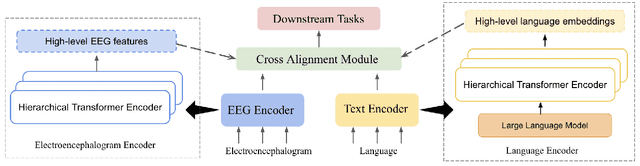
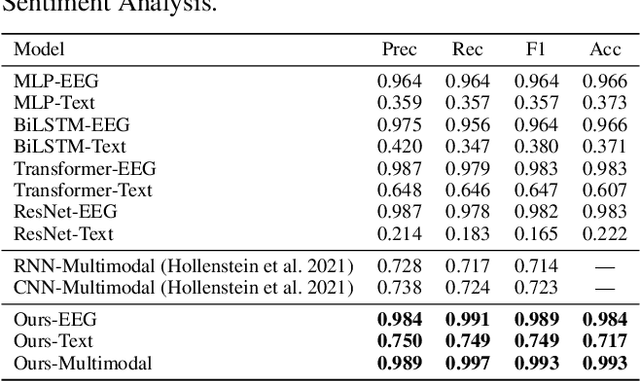
Electroencephalography (EEG) and language have been widely explored independently for many downstream tasks (e.g., sentiment analysis, relation detection, etc.). Multimodal approaches that study both domains have not been well explored, even though in recent years, multimodal learning has been seen to be more powerful than its unimodal counterparts. In this study, we want to explore the relationship and dependency between EEG and language, i.e., how one domain reflects and represents the other. To study the relationship at the representation level, we introduced MTAM, a MultimodalTransformer Alignment Model, to observe coordinated representations between the two modalities, and thus employ the transformed representations for downstream applications. We used various relationship alignment-seeking techniques, such as Canonical Correlation Analysis and Wasserstein Distance, as loss functions to transfigure low-level language and EEG features to high-level transformed features. On downstream applications, sentiment analysis and relation detection, we achieved new state-of-the-art results on two datasets, ZuCo and K-EmoCon. Our method achieved an F1-score improvement of 16.5% on sentiment analysis for K-EmoCon, 27% on sentiment analysis of ZuCo, and 31.1% on relation detection of ZuCo. In addition, we provide interpretations of the performance improvement by: (1) visualizing the original feature distribution and the transformed feature distribution, showing the effectiveness of the alignment module for discovering and encoding the relationship between EEG and language; (2) visualizing word-level and sentence-level EEG-language alignment weights, showing the influence of different language semantics as well as EEG frequency features; and (3) visualizing brain topographical maps to provide an intuitive demonstration of the connectivity of EEG and language response in the brain regions.
GeoECG: Data Augmentation via Wasserstein Geodesic Perturbation for Robust Electrocardiogram Prediction
Aug 10, 2022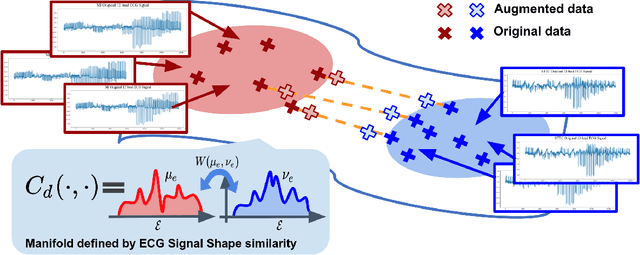


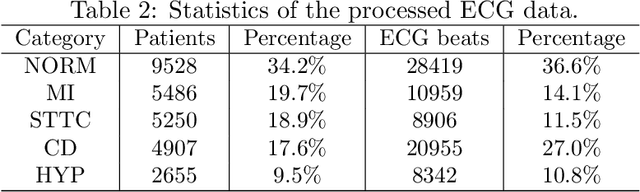
There has been an increased interest in applying deep neural networks to automatically interpret and analyze the 12-lead electrocardiogram (ECG). The current paradigms with machine learning methods are often limited by the amount of labeled data. This phenomenon is particularly problematic for clinically-relevant data, where labeling at scale can be time-consuming and costly in terms of the specialized expertise and human effort required. Moreover, deep learning classifiers may be vulnerable to adversarial examples and perturbations, which could have catastrophic consequences, for example, when applied in the context of medical treatment, clinical trials, or insurance claims. In this paper, we propose a physiologically-inspired data augmentation method to improve performance and increase the robustness of heart disease detection based on ECG signals. We obtain augmented samples by perturbing the data distribution towards other classes along the geodesic in Wasserstein space. To better utilize domain-specific knowledge, we design a ground metric that recognizes the difference between ECG signals based on physiologically determined features. Learning from 12-lead ECG signals, our model is able to distinguish five categories of cardiac conditions. Our results demonstrate improvements in accuracy and robustness, reflecting the effectiveness of our data augmentation method.
* 26 pages, Figure 13, Machine Learning for Healthcare 2022
Generalizing Goal-Conditioned Reinforcement Learning with Variational Causal Reasoning
Jul 19, 2022
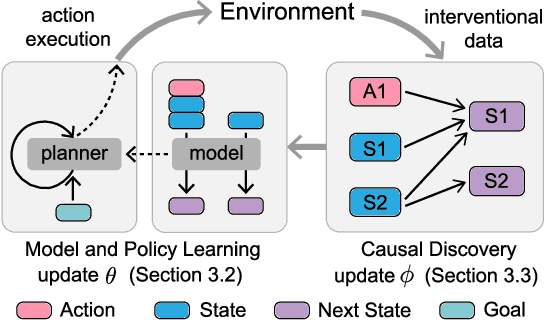
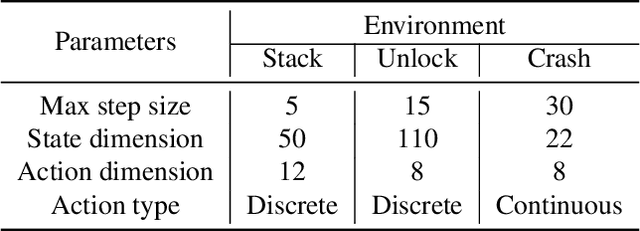
As a pivotal component to attaining generalizable solutions in human intelligence, reasoning provides great potential for reinforcement learning (RL) agents' generalization towards varied goals by summarizing part-to-whole arguments and discovering cause-and-effect relations. However, how to discover and represent causalities remains a huge gap that hinders the development of causal RL. In this paper, we augment Goal-Conditioned RL (GCRL) with Causal Graph (CG), a structure built upon the relation between objects and events. We novelly formulate the GCRL problem into variational likelihood maximization with CG as latent variables. To optimize the derived objective, we propose a framework with theoretical performance guarantees that alternates between two steps: using interventional data to estimate the posterior of CG; using CG to learn generalizable models and interpretable policies. Due to the lack of public benchmarks that verify generalization capability under reasoning, we design nine tasks and then empirically show the effectiveness of the proposed method against five baselines on these tasks. Further theoretical analysis shows that our performance improvement is attributed to the virtuous cycle of causal discovery, transition modeling, and policy training, which aligns with the experimental evidence in extensive ablation studies.
Prompting Decision Transformer for Few-Shot Policy Generalization
Jun 27, 2022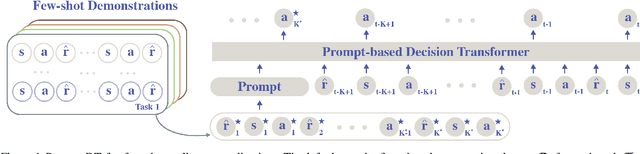
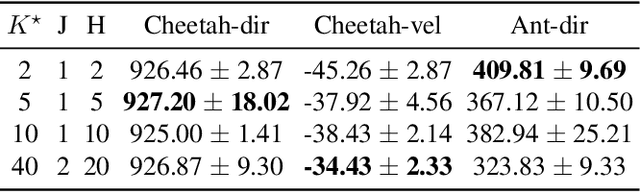
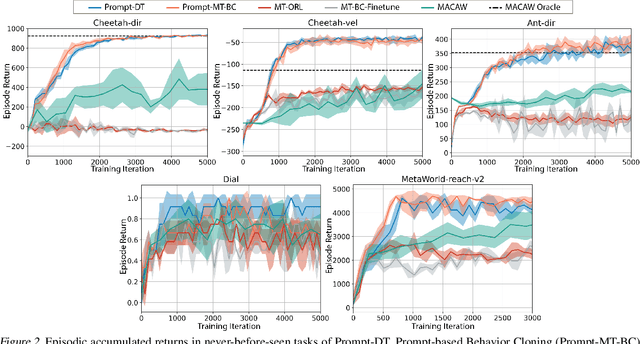
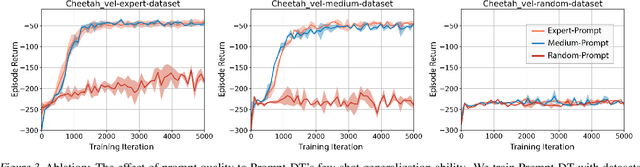
Humans can leverage prior experience and learn novel tasks from a handful of demonstrations. In contrast to offline meta-reinforcement learning, which aims to achieve quick adaptation through better algorithm design, we investigate the effect of architecture inductive bias on the few-shot learning capability. We propose a Prompt-based Decision Transformer (Prompt-DT), which leverages the sequential modeling ability of the Transformer architecture and the prompt framework to achieve few-shot adaptation in offline RL. We design the trajectory prompt, which contains segments of the few-shot demonstrations, and encodes task-specific information to guide policy generation. Our experiments in five MuJoCo control benchmarks show that Prompt-DT is a strong few-shot learner without any extra finetuning on unseen target tasks. Prompt-DT outperforms its variants and strong meta offline RL baselines by a large margin with a trajectory prompt containing only a few timesteps. Prompt-DT is also robust to prompt length changes and can generalize to out-of-distribution (OOD) environments.
SafeBench: A Benchmarking Platform for Safety Evaluation of Autonomous Vehicles
Jun 20, 2022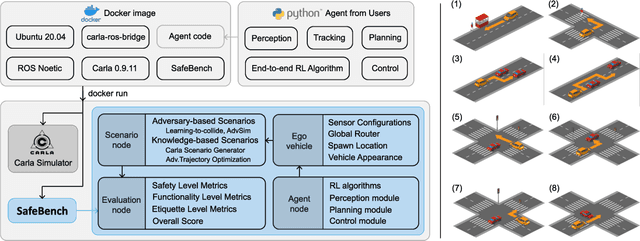
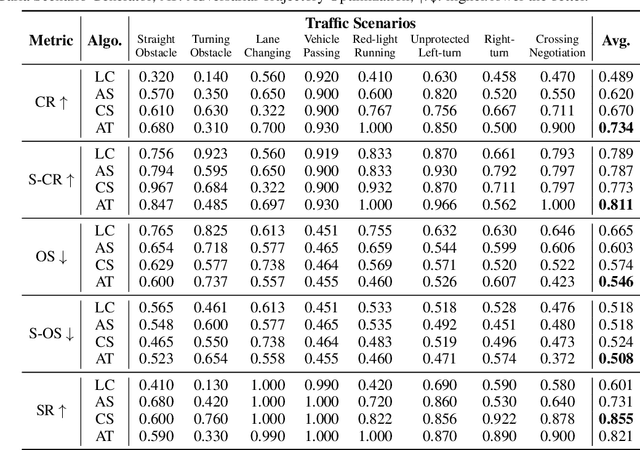

As shown by recent studies, machine intelligence-enabled systems are vulnerable to test cases resulting from either adversarial manipulation or natural distribution shifts. This has raised great concerns about deploying machine learning algorithms for real-world applications, especially in the safety-critical domains such as autonomous driving (AD). On the other hand, traditional AD testing on naturalistic scenarios requires hundreds of millions of driving miles due to the high dimensionality and rareness of the safety-critical scenarios in the real world. As a result, several approaches for autonomous driving evaluation have been explored, which are usually, however, based on different simulation platforms, types of safety-critical scenarios, scenario generation algorithms, and driving route variations. Thus, despite a large amount of effort in autonomous driving testing, it is still challenging to compare and understand the effectiveness and efficiency of different testing scenario generation algorithms and testing mechanisms under similar conditions. In this paper, we aim to provide the first unified platform SafeBench to integrate different types of safety-critical testing scenarios, scenario generation algorithms, and other variations such as driving routes and environments. Meanwhile, we implement 4 deep reinforcement learning-based AD algorithms with 4 types of input (e.g., bird's-eye view, camera) to perform fair comparisons on SafeBench. We find our generated testing scenarios are indeed more challenging and observe the trade-off between the performance of AD agents under benign and safety-critical testing scenarios. We believe our unified platform SafeBench for large-scale and effective autonomous driving testing will motivate the development of new testing scenario generation and safe AD algorithms. SafeBench is available at https://safebench.github.io.
On the Robustness of Safe Reinforcement Learning under Observational Perturbations
May 29, 2022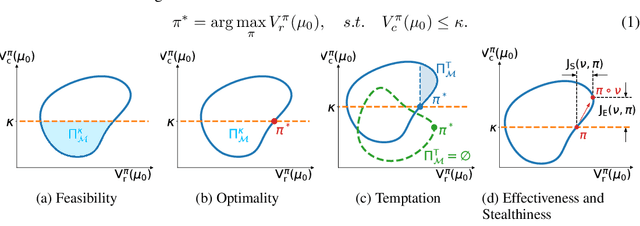

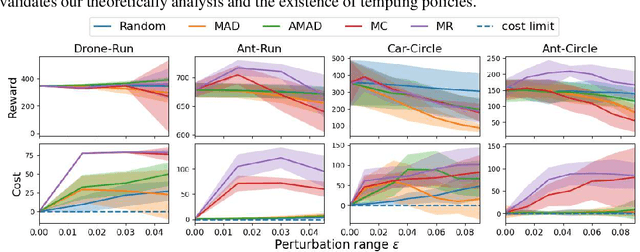
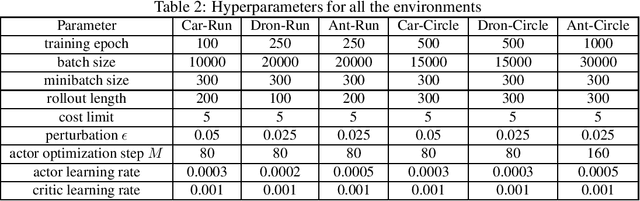
Safe reinforcement learning (RL) trains a policy to maximize the task reward while satisfying safety constraints. While prior works focus on the performance optimality, we find that the optimal solutions of many safe RL problems are not robust and safe against carefully designed observational perturbations. We formally analyze the unique properties of designing effective state adversarial attackers in the safe RL setting. We show that baseline adversarial attack techniques for standard RL tasks are not always effective for safe RL and proposed two new approaches - one maximizes the cost and the other maximizes the reward. One interesting and counter-intuitive finding is that the maximum reward attack is strong, as it can both induce unsafe behaviors and make the attack stealthy by maintaining the reward. We further propose a more effective adversarial training framework for safe RL and evaluate it via comprehensive experiments. This work sheds light on the inherited connection between observational robustness and safety in RL and provides a pioneer work for future safe RL studies.
Road Traffic Law Adaptive Decision-making for Self-Driving Vehicles
Apr 26, 2022
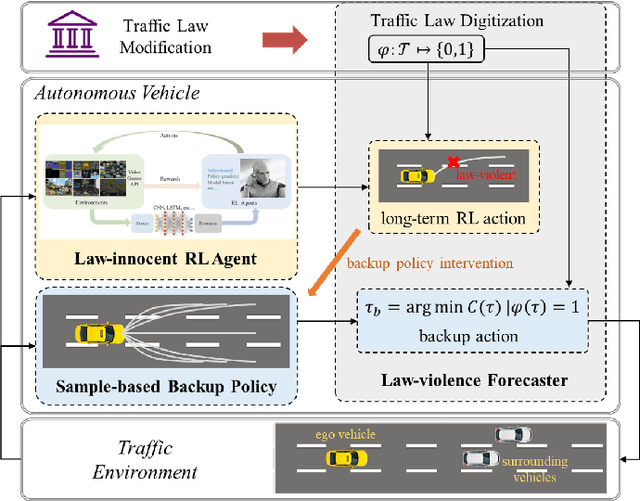
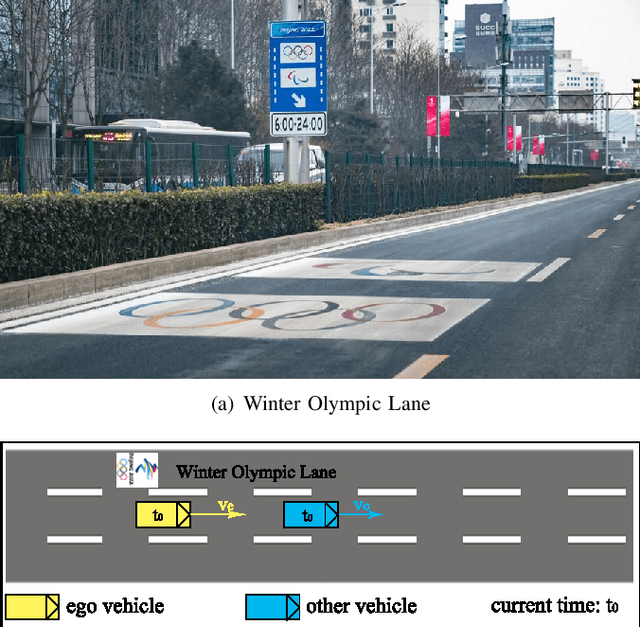
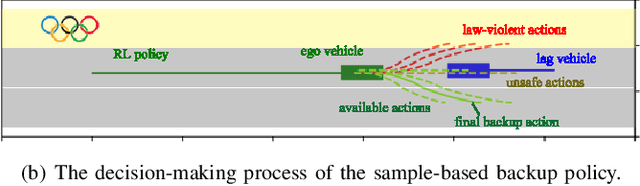
Self-driving vehicles have their own intelligence to drive on open roads. However, vehicle managers, e.g., government or industrial companies, still need a way to tell these self-driving vehicles what behaviors are encouraged or forbidden. Unlike human drivers, current self-driving vehicles cannot understand the traffic laws, thus rely on the programmers manually writing the corresponding principles into the driving systems. It would be less efficient and hard to adapt some temporary traffic laws, especially when the vehicles use data-driven decision-making algorithms. Besides, current self-driving vehicle systems rarely take traffic law modification into consideration. This work aims to design a road traffic law adaptive decision-making method. The decision-making algorithm is designed based on reinforcement learning, in which the traffic rules are usually implicitly coded in deep neural networks. The main idea is to supply the adaptability to traffic laws of self-driving vehicles by a law-adaptive backup policy. In this work, the natural language-based traffic laws are first translated into a logical expression by the Linear Temporal Logic method. Then, the system will try to monitor in advance whether the self-driving vehicle may break the traffic laws by designing a long-term RL action space. Finally, a sample-based planning method will re-plan the trajectory when the vehicle may break the traffic rules. The method is validated in a Beijing Winter Olympic Lane scenario and an overtaking case, built in CARLA simulator. The results show that by adopting this method, the self-driving vehicles can comply with new issued or updated traffic laws effectively. This method helps self-driving vehicles governed by digital traffic laws, which is necessary for the wide adoption of autonomous driving.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 20, 2022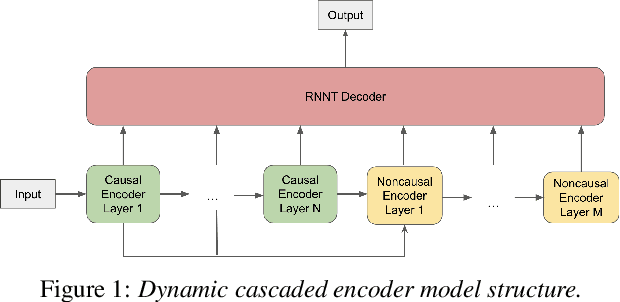
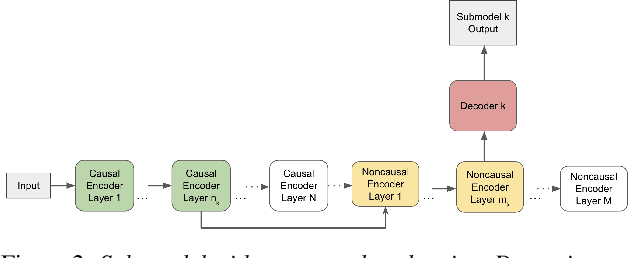
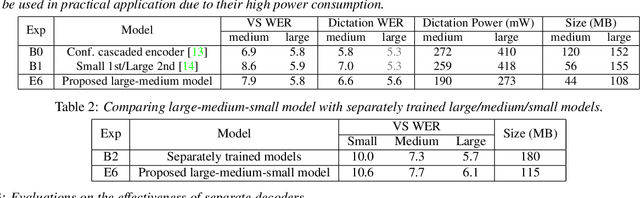
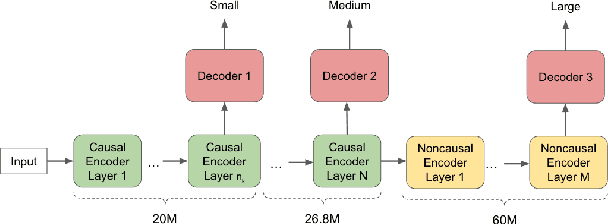
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.