 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text
May 09, 2021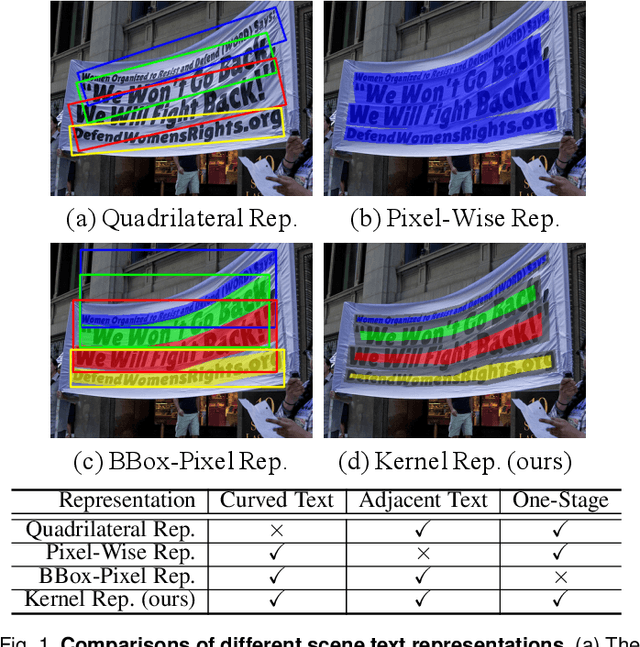
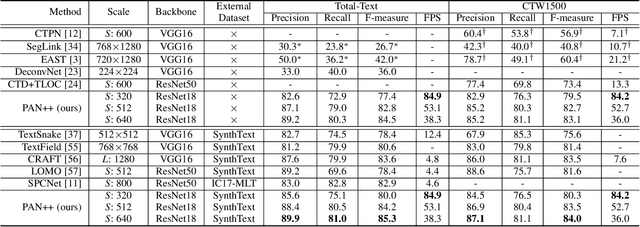
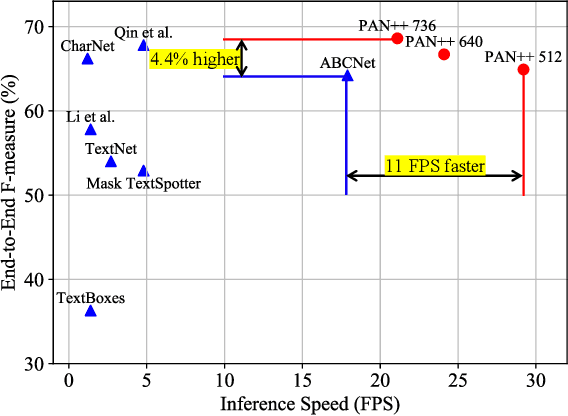
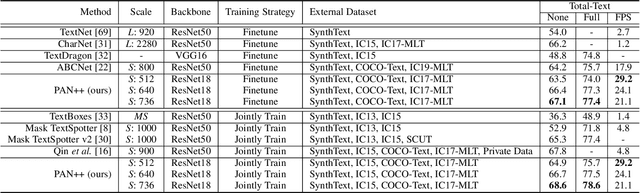
Scene text detection and recognition have been well explored in the past few years. Despite the progress, efficient and accurate end-to-end spotting of arbitrarily-shaped text remains challenging. In this work, we propose an end-to-end text spotting framework, termed PAN++, which can efficiently detect and recognize text of arbitrary shapes in natural scenes. PAN++ is based on the kernel representation that reformulates a text line as a text kernel (central region) surrounded by peripheral pixels. By systematically comparing with existing scene text representations, we show that our kernel representation can not only describe arbitrarily-shaped text but also well distinguish adjacent text. Moreover, as a pixel-based representation, the kernel representation can be predicted by a single fully convolutional network, which is very friendly to real-time applications. Taking the advantages of the kernel representation, we design a series of components as follows: 1) a computationally efficient feature enhancement network composed of stacked Feature Pyramid Enhancement Modules (FPEMs); 2) a lightweight detection head cooperating with Pixel Aggregation (PA); and 3) an efficient attention-based recognition head with Masked RoI. Benefiting from the kernel representation and the tailored components, our method achieves high inference speed while maintaining competitive accuracy. Extensive experiments show the superiority of our method. For example, the proposed PAN++ achieves an end-to-end text spotting F-measure of 64.9 at 29.2 FPS on the Total-Text dataset, which significantly outperforms the previous best method. Code will be available at: https://git.io/PAN.
Inter-class Discrepancy Alignment for Face Recognition
Mar 02, 2021The field of face recognition (FR) has witnessed great progress with the surge of deep learning. Existing methods mainly focus on extracting discriminative features, and directly compute the cosine or L2 distance by the point-to-point way without considering the context information. In this study, we make a key observation that the local con-text represented by the similarities between the instance and its inter-class neighbors1plays an important role forFR. Specifically, we attempt to incorporate the local in-formation in the feature space into the metric, and pro-pose a unified framework calledInter-class DiscrepancyAlignment(IDA), with two dedicated modules, Discrepancy Alignment Operator(IDA-DAO) andSupport Set Estimation(IDA-SSE). IDA-DAO is used to align the similarity scores considering the discrepancy between the images and its neighbors, which is defined by adaptive support sets on the hypersphere. For practical inference, it is difficult to acquire support set during online inference. IDA-SSE can provide convincing inter-class neighbors by introducing virtual candidate images generated with GAN. Further-more, we propose the learnable IDA-SSE, which can implicitly give estimation without the need of any other images in the evaluation process. The proposed IDA can be incorporated into existing FR systems seamlessly and efficiently. Extensive experiments demonstrate that this frame-work can 1) significantly improve the accuracy, and 2) make the model robust to the face images of various distributions.Without bells and whistles, our method achieves state-of-the-art performance on multiple standard FR benchmarks.
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
Feb 24, 2021
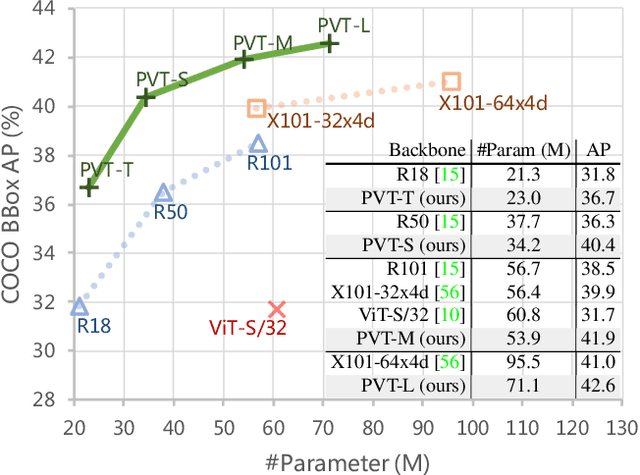
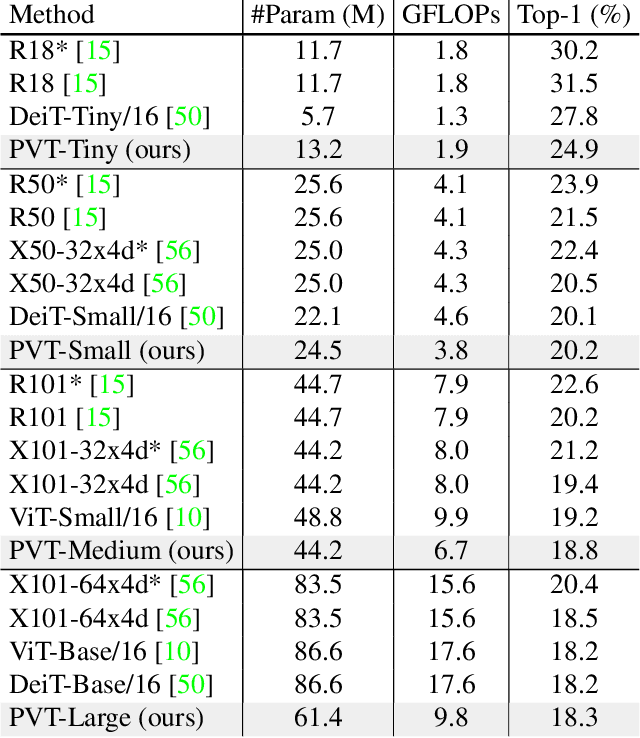
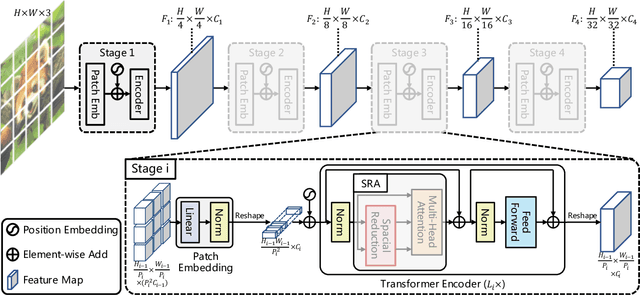
Although using convolutional neural networks (CNNs) as backbones achieves great successes in computer vision, this work investigates a simple backbone network useful for many dense prediction tasks without convolutions. Unlike the recently-proposed Transformer model (e.g., ViT) that is specially designed for image classification, we propose Pyramid Vision Transformer~(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several merits compared to prior arts. (1) Different from ViT that typically has low-resolution outputs and high computational and memory cost, PVT can be not only trained on dense partitions of the image to achieve high output resolution, which is important for dense predictions but also using a progressive shrinking pyramid to reduce computations of large feature maps. (2) PVT inherits the advantages from both CNN and Transformer, making it a unified backbone in various vision tasks without convolutions by simply replacing CNN backbones. (3) We validate PVT by conducting extensive experiments, showing that it boosts the performance of many downstream tasks, e.g., object detection, semantic, and instance segmentation. For example, with a comparable number of parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP. We hope PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future researches. Code is available at https://github.com/whai362/PVT.
Segmenting Transparent Object in the Wild with Transformer
Feb 23, 2021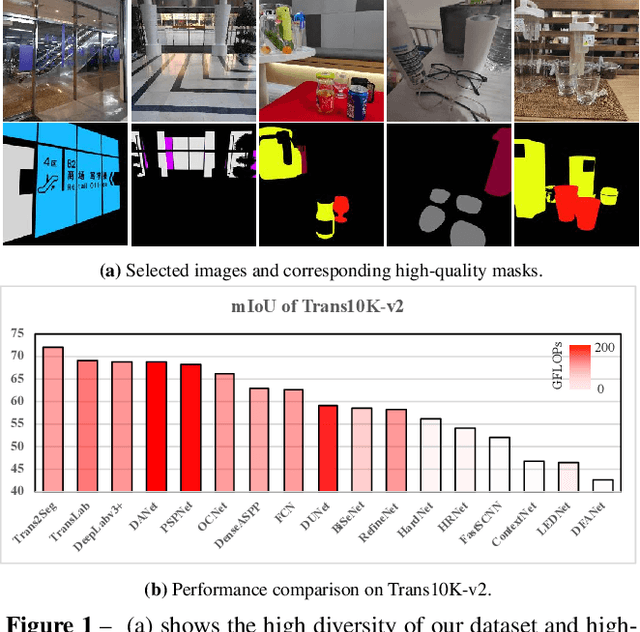


This work presents a new fine-grained transparent object segmentation dataset, termed Trans10K-v2, extending Trans10K-v1, the first large-scale transparent object segmentation dataset. Unlike Trans10K-v1 that only has two limited categories, our new dataset has several appealing benefits. (1) It has 11 fine-grained categories of transparent objects, commonly occurring in the human domestic environment, making it more practical for real-world application. (2) Trans10K-v2 brings more challenges for the current advanced segmentation methods than its former version. Furthermore, a novel transformer-based segmentation pipeline termed Trans2Seg is proposed. Firstly, the transformer encoder of Trans2Seg provides the global receptive field in contrast to CNN's local receptive field, which shows excellent advantages over pure CNN architectures. Secondly, by formulating semantic segmentation as a problem of dictionary look-up, we design a set of learnable prototypes as the query of Trans2Seg's transformer decoder, where each prototype learns the statistics of one category in the whole dataset. We benchmark more than 20 recent semantic segmentation methods, demonstrating that Trans2Seg significantly outperforms all the CNN-based methods, showing the proposed algorithm's potential ability to solve transparent object segmentation.
DocStruct: A Multimodal Method to Extract Hierarchy Structure in Document for General Form Understanding
Oct 15, 2020
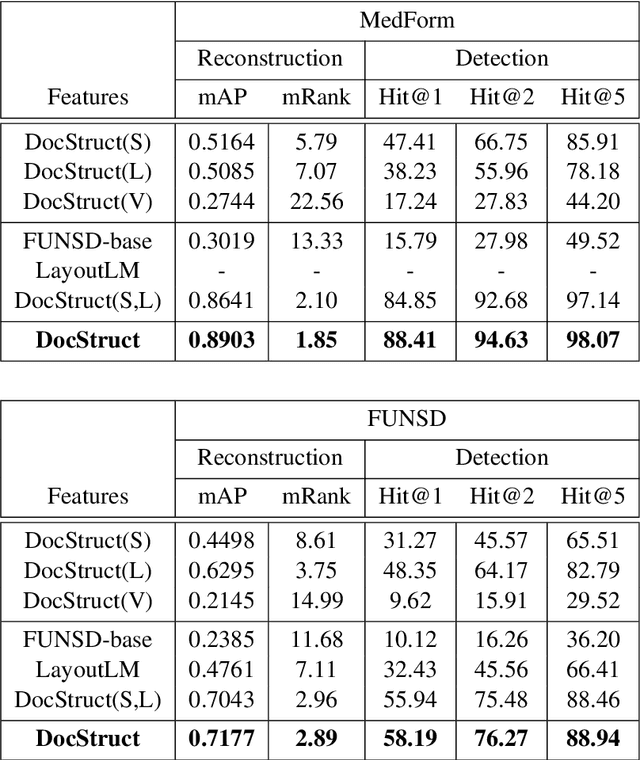
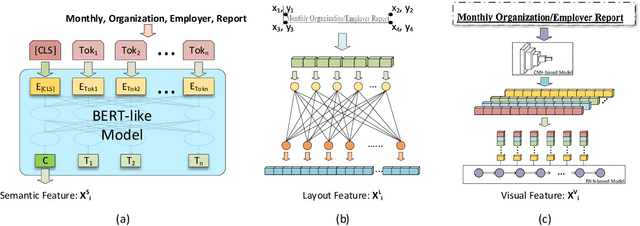
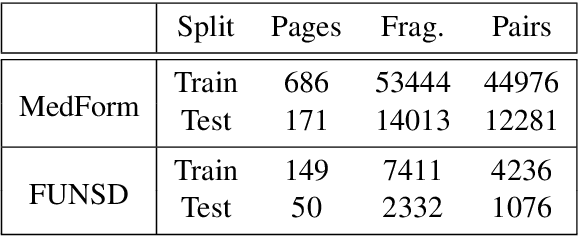
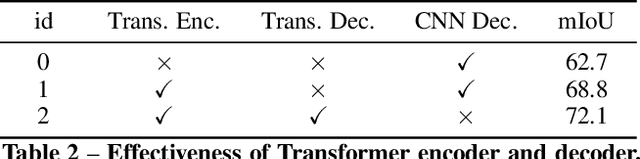
Form understanding depends on both textual contents and organizational structure. Although modern OCR performs well, it is still challenging to realize general form understanding because forms are commonly used and of various formats. The table detection and handcrafted features in previous works cannot apply to all forms because of their requirements on formats. Therefore, we concentrate on the most elementary components, the key-value pairs, and adopt multimodal methods to extract features. We consider the form structure as a tree-like or graph-like hierarchy of text fragments. The parent-child relation corresponds to the key-value pairs in forms. We utilize the state-of-the-art models and design targeted extraction modules to extract multimodal features from semantic contents, layout information, and visual images. A hybrid fusion method of concatenation and feature shifting is designed to fuse the heterogeneous features and provide an informative joint representation. We adopt an asymmetric algorithm and negative sampling in our model as well. We validate our method on two benchmarks, MedForm and FUNSD, and extensive experiments demonstrate the effectiveness of our method.
AE TextSpotter: Learning Visual and Linguistic Representation for Ambiguous Text Spotting
Aug 05, 2020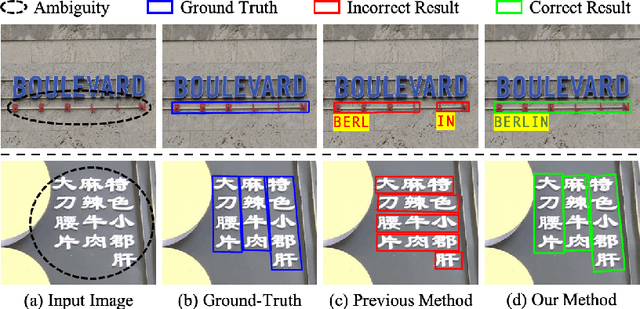
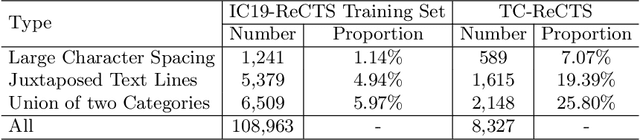

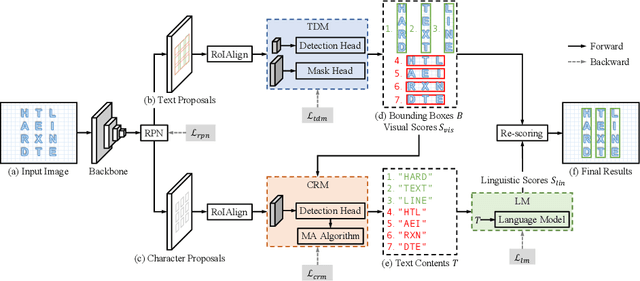
Scene text spotting aims to detect and recognize the entire word or sentence with multiple characters in natural images. It is still challenging because ambiguity often occurs when the spacing between characters is large or the characters are evenly spread in multiple rows and columns, making many visually plausible groupings of the characters (e.g. "BERLIN" is incorrectly detected as "BERL" and "IN" in Fig. 1(c)). Unlike previous works that merely employed visual features for text detection, this work proposes a novel text spotter, named Ambiguity Eliminating Text Spotter (AE TextSpotter), which learns both visual and linguistic features to significantly reduce ambiguity in text detection. The proposed AE TextSpotter has three important benefits. 1) The linguistic representation is learned together with the visual representation in a framework. To our knowledge, it is the first time to improve text detection by using a language model. 2) A carefully designed language module is utilized to reduce the detection confidence of incorrect text lines, making them easily pruned in the detection stage. 3) Extensive experiments show that AE TextSpotter outperforms other state-of-the-art methods by a large margin. For example, we carefully select a validation set of extremely ambiguous samples from the IC19-ReCTS dataset, where our approach surpasses other methods by more than 4%. The image list and evaluation scripts of the validation set have been released at https://github.com/whai362/TDA-ReCTS.
Scene Text Image Super-Resolution in the Wild
May 07, 2020
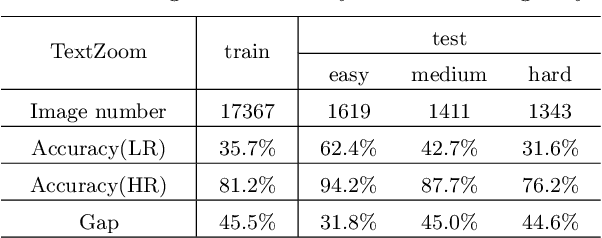
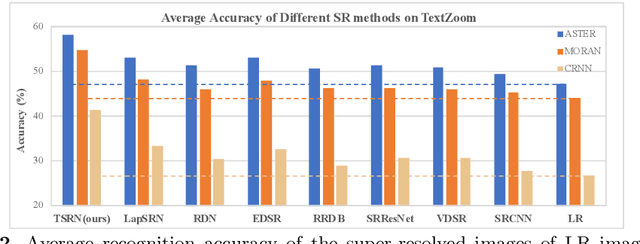
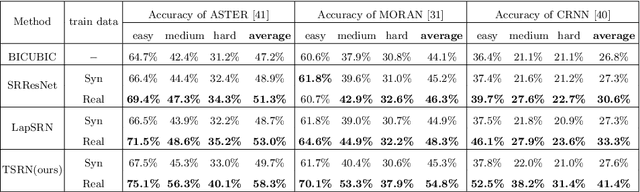
Low-resolution text images are often seen in natural scenes such as documents captured by mobile phones. Recognizing low-resolution text images is challenging because they lose detailed content information, leading to poor recognition accuracy. An intuitive solution is to introduce super-resolution (SR) techniques as pre-processing. However, previous single image super-resolution (SISR) methods are trained on synthetic low-resolution images (e.g.Bicubic down-sampling), which is simple and not suitable for real low-resolution text recognition. To this end, we pro-pose a real scene text SR dataset, termed TextZoom. It contains paired real low-resolution and high-resolution images which are captured by cameras with different focal length in the wild. It is more authentic and challenging than synthetic data, as shown in Fig. 1. We argue improv-ing the recognition accuracy is the ultimate goal for Scene Text SR. In this purpose, a new Text Super-Resolution Network termed TSRN, with three novel modules is developed. (1) A sequential residual block is proposed to extract the sequential information of the text images. (2) A boundary-aware loss is designed to sharpen the character boundaries. (3) A central alignment module is proposed to relieve the misalignment problem in TextZoom. Extensive experiments on TextZoom demonstrate that our TSRN largely improves the recognition accuracy by over 13%of CRNN, and by nearly 9.0% of ASTER and MORAN compared to synthetic SR data. Furthermore, our TSRN clearly outperforms 7 state-of-the-art SR methods in boosting the recognition accuracy of LR images in TextZoom. For example, it outperforms LapSRN by over 5% and 8%on the recognition accuracy of ASTER and CRNN. Our results suggest that low-resolution text recognition in the wild is far from being solved, thus more research effort is needed.
PolarMask: Single Shot Instance Segmentation with Polar Representation
Oct 10, 2019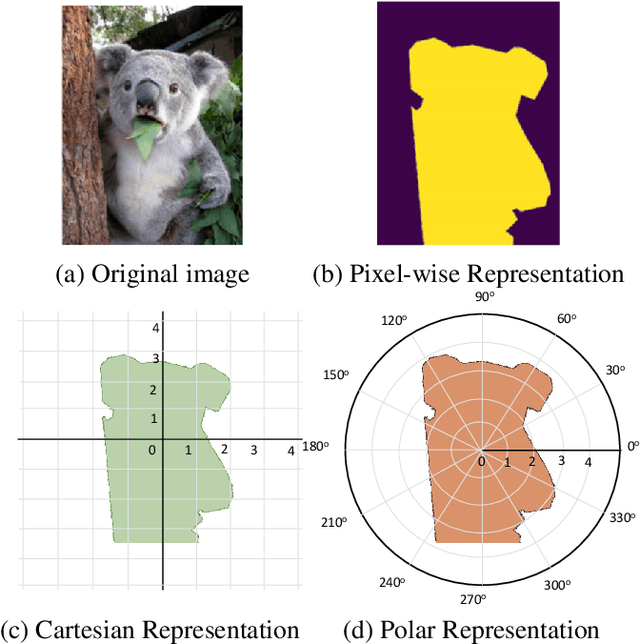
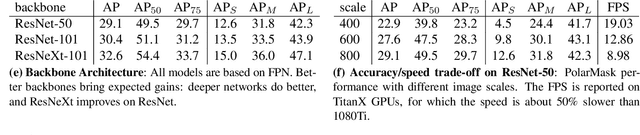
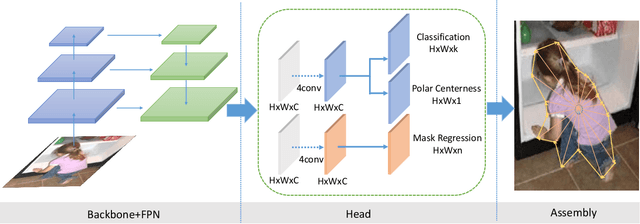
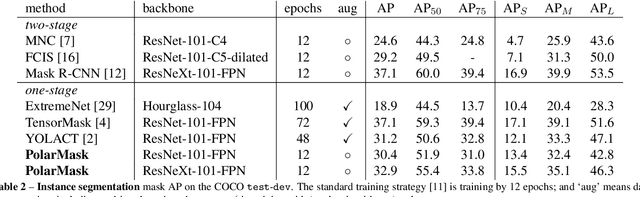
In this paper, we introduce an anchor-box free and single shot instance segmentation method, which is conceptually simple, fully convolutional and can be used as a mask prediction module for instance segmentation, by easily embedding it into most off-the-shelf detection methods. Our method, termed PolarMask, formulates the instance segmentation problem as instance center classification and dense distance regression in a polar coordinate. Moreover, we propose two effective approaches to deal with sampling high-quality center examples and optimization for dense distance regression, respectively, which can significantly improve the performance and simplify the training process. Without any bells and whistles, PolarMask achieves 32.9% in mask mAP with single-model and single-scale training/testing on challenging COCO dataset. For the first time, we demonstrate a much simpler and flexible instance segmentation framework achieving competitive accuracy. We hope that the proposed PolarMask framework can serve as a fundamental and strong baseline for single shot instance segmentation tasks. Code is available at: github.com/xieenze/PolarMask.
Knowledge Distillation via Route Constrained Optimization
Apr 19, 2019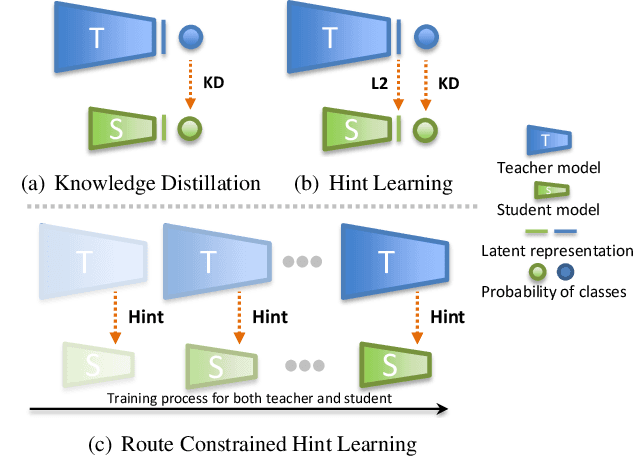
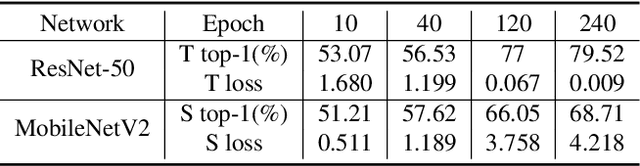
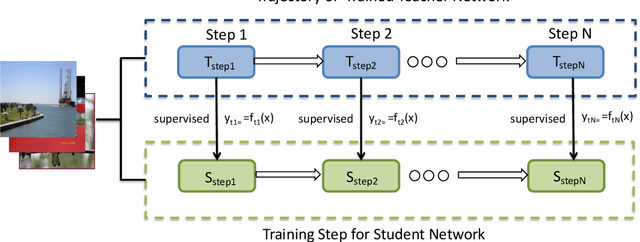
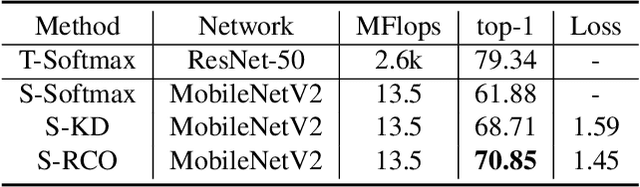
Distillation-based learning boosts the performance of the miniaturized neural network based on the hypothesis that the representation of a teacher model can be used as structured and relatively weak supervision, and thus would be easily learned by a miniaturized model. However, we find that the representation of a converged heavy model is still a strong constraint for training a small student model, which leads to a high lower bound of congruence loss. In this work, inspired by curriculum learning we consider the knowledge distillation from the perspective of curriculum learning by routing. Instead of supervising the student model with a converged teacher model, we supervised it with some anchor points selected from the route in parameter space that the teacher model passed by, as we called route constrained optimization (RCO). We experimentally demonstrate this simple operation greatly reduces the lower bound of congruence loss for knowledge distillation, hint and mimicking learning. On close-set classification tasks like CIFAR100 and ImageNet, RCO improves knowledge distillation by 2.14% and 1.5% respectively. For the sake of evaluating the generalization, we also test RCO on the open-set face recognition task MegaFace.
Dynamic Multi-path Neural Network
Apr 07, 2019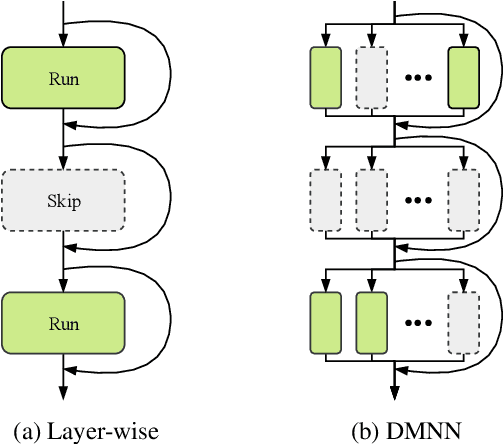
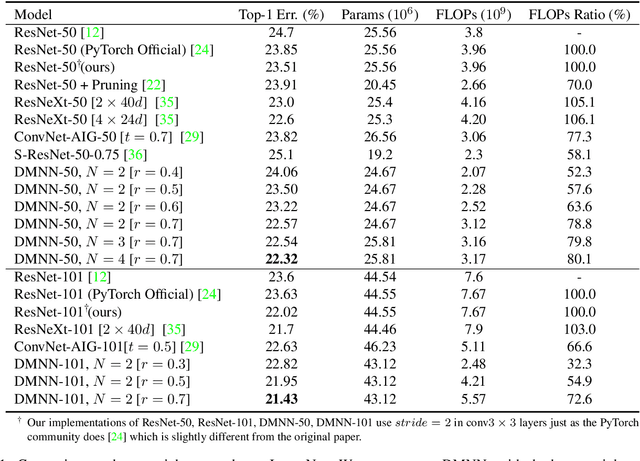
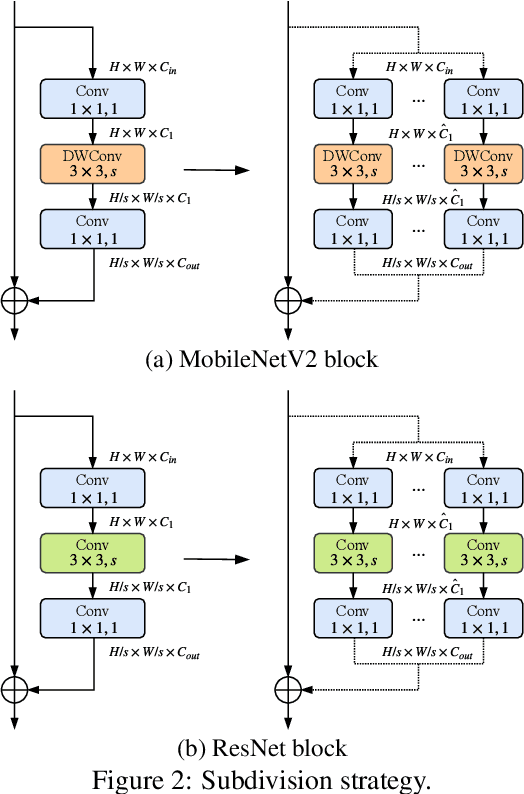
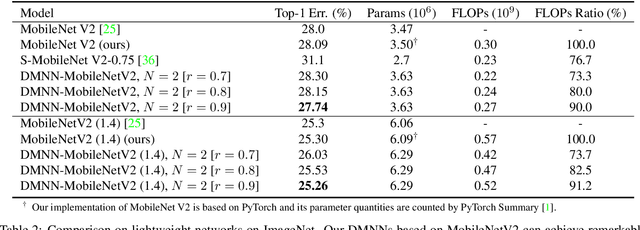
Although deeper and larger neural networks have achieved better performance, the complex network structure and increasing computational cost cannot meet the demands of many resource-constrained applications. Existing methods usually choose to execute or skip an entire specific layer, which can only alter the depth of the network. In this paper, we propose a novel method called Dynamic Multi-path Neural Network (DMNN), which provides more path selection choices in terms of network width and depth during inference. The inference path of the network is determined by a controller, which takes into account both previous state and object category information. The proposed method can be easily incorporated into most modern network architectures. Experimental results on ImageNet and CIFAR-100 demonstrate the superiority of our method on both efficiency and overall classification accuracy. To be specific, DMNN-101 significantly outperforms ResNet-101 with an encouraging 45.1% FLOPs reduction, and DMNN-50 performs comparably to ResNet-101 while saving 42.1% parameters.