 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransForensics: Image Forgery Localization with Dense Self-Attention
Aug 09, 2021
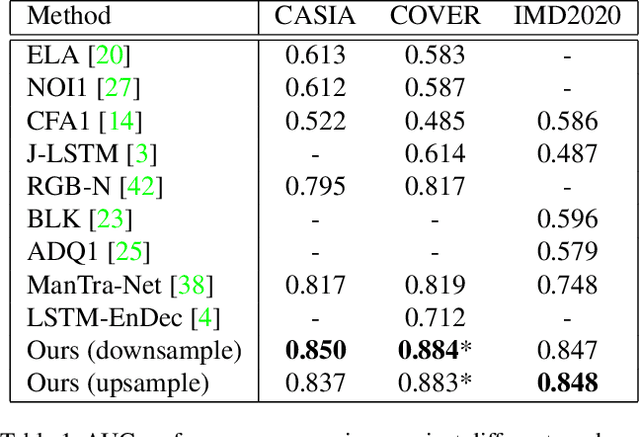
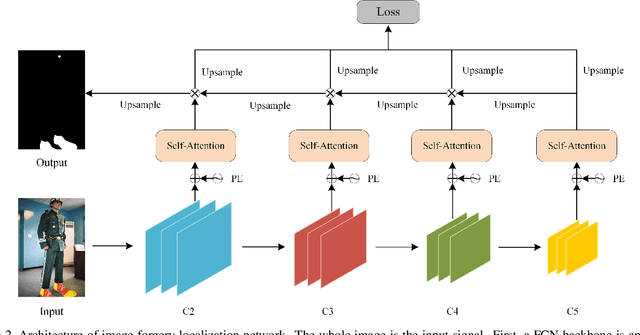
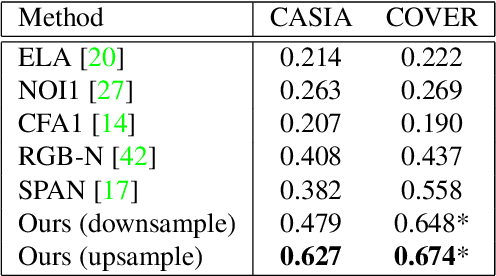
Nowadays advanced image editing tools and technical skills produce tampered images more realistically, which can easily evade image forensic systems and make authenticity verification of images more difficult. To tackle this challenging problem, we introduce TransForensics, a novel image forgery localization method inspired by Transformers. The two major components in our framework are dense self-attention encoders and dense correction modules. The former is to model global context and all pairwise interactions between local patches at different scales, while the latter is used for improving the transparency of the hidden layers and correcting the outputs from different branches. Compared to previous traditional and deep learning methods, TransForensics not only can capture discriminative representations and obtain high-quality mask predictions but is also not limited by tampering types and patch sequence orders. By conducting experiments on main benchmarks, we show that TransForensics outperforms the stateof-the-art methods by a large margin.
Divide-and-Assemble: Learning Block-wise Memory for Unsupervised Anomaly Detection
Jul 28, 2021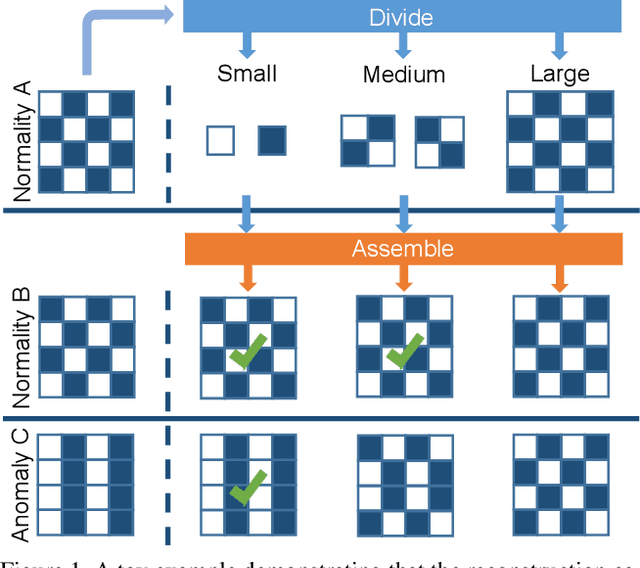

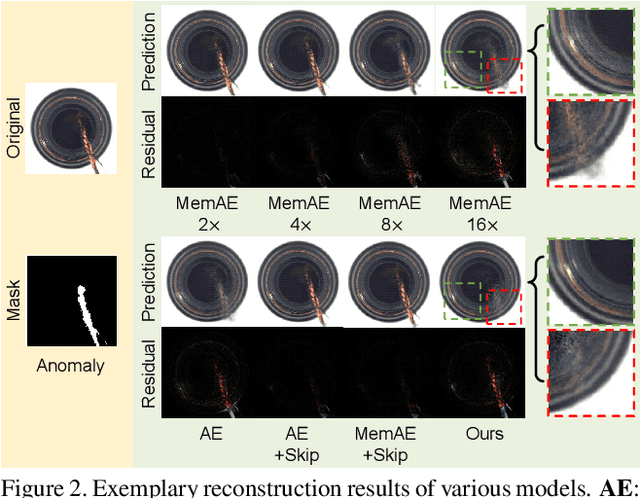
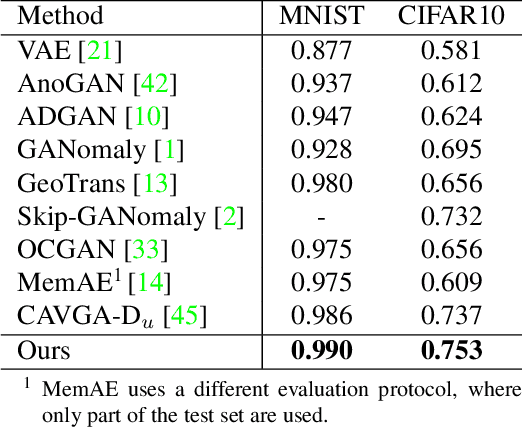
Reconstruction-based methods play an important role in unsupervised anomaly detection in images. Ideally, we expect a perfect reconstruction for normal samples and poor reconstruction for abnormal samples. Since the generalizability of deep neural networks is difficult to control, existing models such as autoencoder do not work well. In this work, we interpret the reconstruction of an image as a divide-and-assemble procedure. Surprisingly, by varying the granularity of division on feature maps, we are able to modulate the reconstruction capability of the model for both normal and abnormal samples. That is, finer granularity leads to better reconstruction, while coarser granularity leads to poorer reconstruction. With proper granularity, the gap between the reconstruction error of normal and abnormal samples can be maximized. The divide-and-assemble framework is implemented by embedding a novel multi-scale block-wise memory module into an autoencoder network. Besides, we introduce adversarial learning and explore the semantic latent representation of the discriminator, which improves the detection of subtle anomaly. We achieve state-of-the-art performance on the challenging MVTec AD dataset. Remarkably, we improve the vanilla autoencoder model by 10.1% in terms of the AUROC score.
Modulating Localization and Classification for Harmonized Object Detection
Mar 25, 2021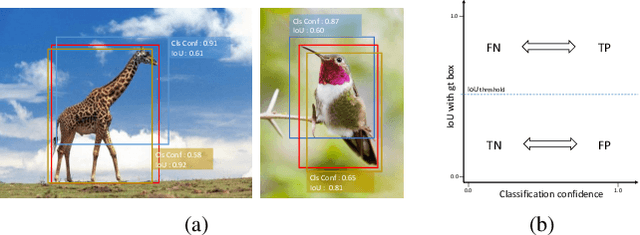

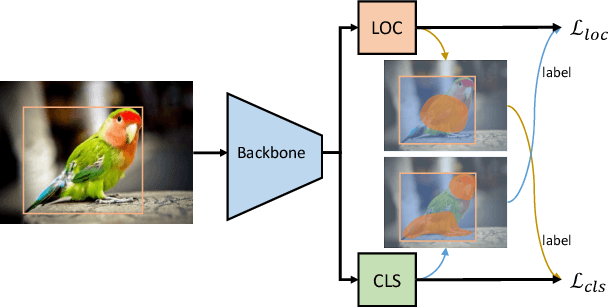
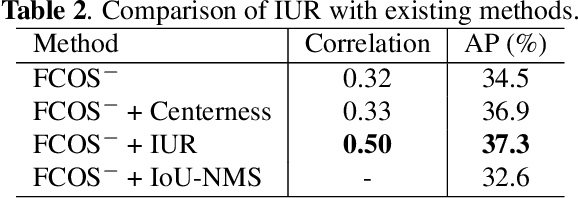
Object detection involves two sub-tasks, i.e. localizing objects in an image and classifying them into various categories. For existing CNN-based detectors, we notice the widespread divergence between localization and classification, which leads to degradation in performance. In this work, we propose a mutual learning framework to modulate the two tasks. In particular, the two tasks are forced to learn from each other with a novel mutual labeling strategy. Besides, we introduce a simple yet effective IoU rescoring scheme, which further reduces the divergence. Moreover, we define a Spearman rank correlation-based metric to quantify the divergence, which correlates well with the detection performance. The proposed approach is general-purpose and can be easily injected into existing detectors such as FCOS and RetinaNet. We achieve a significant performance gain over the baseline detectors on the COCO dataset.
Self-Supervised Noisy Label Learning for Source-Free Unsupervised Domain Adaptation
Feb 23, 2021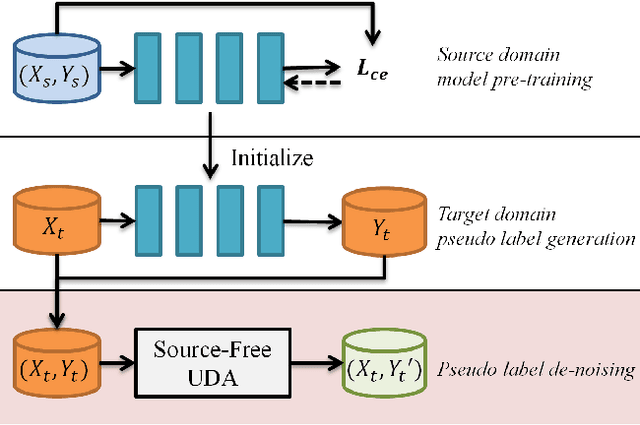

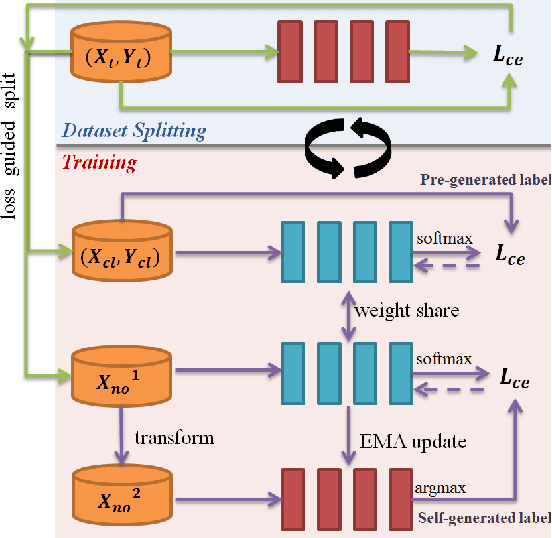

It is a strong prerequisite to access source data freely in many existing unsupervised domain adaptation approaches. However, source data is agnostic in many practical scenarios due to the constraints of expensive data transmission and data privacy protection. Usually, the given source domain pre-trained model is expected to optimize with only unlabeled target data, which is termed as source-free unsupervised domain adaptation. In this paper, we solve this problem from the perspective of noisy label learning, since the given pre-trained model can pre-generate noisy label for unlabeled target data via directly network inference. Under this problem modeling, incorporating self-supervised learning, we propose a novel Self-Supervised Noisy Label Learning method, which can effectively fine-tune the pre-trained model with pre-generated label as well as selfgenerated label on the fly. Extensive experiments had been conducted to validate its effectiveness. Our method can easily achieve state-of-the-art results and surpass other methods by a very large margin. Code will be released.
Box Re-Ranking: Unsupervised False Positive Suppression for Domain Adaptive Pedestrian Detection
Feb 01, 2021
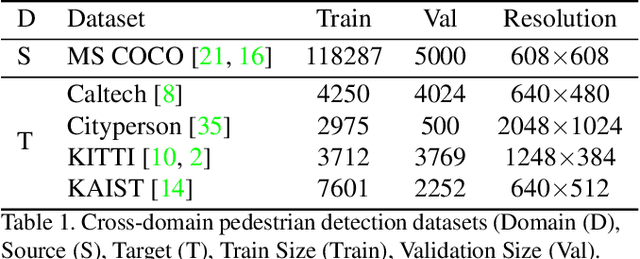
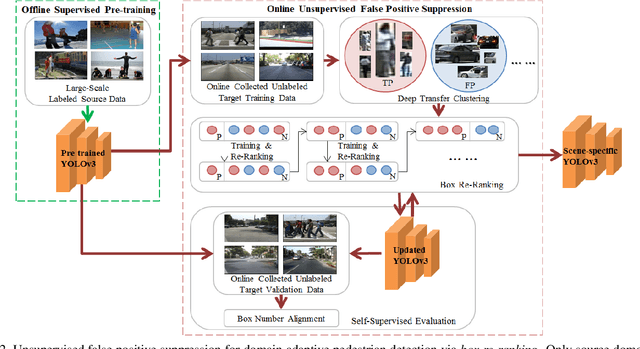
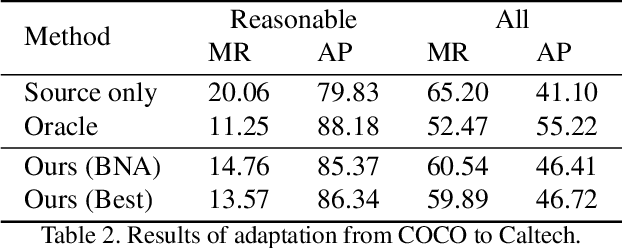
False positive is one of the most serious problems brought by agnostic domain shift in domain adaptive pedestrian detection. However, it is impossible to label each box in countless target domains. Therefore, it yields our attention to suppress false positive in each target domain in an unsupervised way. In this paper, we model an object detection task into a ranking task among positive and negative boxes innovatively, and thus transform a false positive suppression problem into a box re-ranking problem elegantly, which makes it feasible to solve without manual annotation. An attached problem during box re-ranking appears that no labeled validation data is available for cherrypicking. Considering we aim to keep the detection of true positive unchanged, we propose box number alignment, a self-supervised evaluation metric, to prevent the optimized model from capacity degeneration. Extensive experiments conducted on cross-domain pedestrian detection datasets have demonstrated the effectiveness of our proposed framework. Furthermore, the extension to two general unsupervised domain adaptive object detection benchmarks also supports our superiority to other state-of-the-arts.
A Free Lunch for Unsupervised Domain Adaptive Object Detection without Source Data
Dec 10, 2020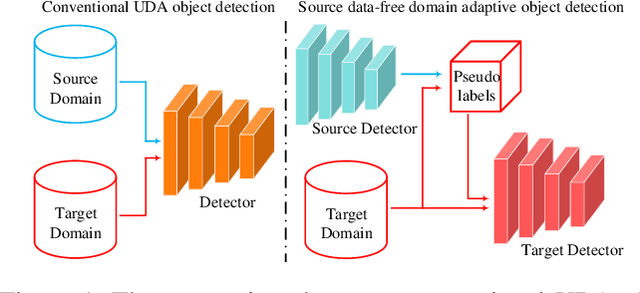
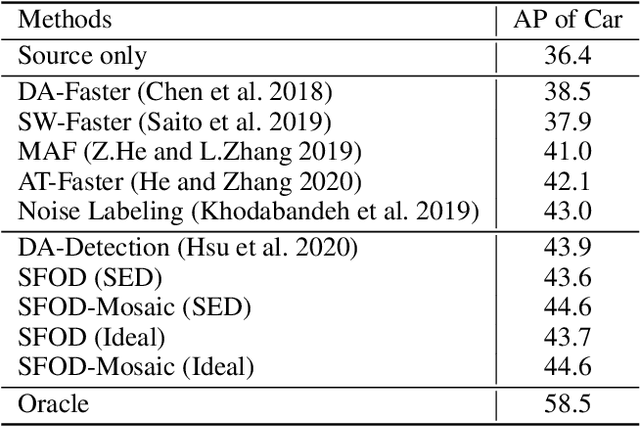
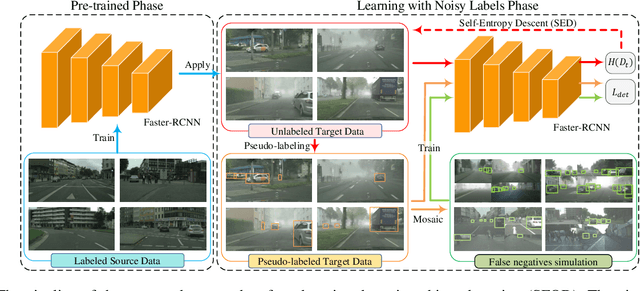
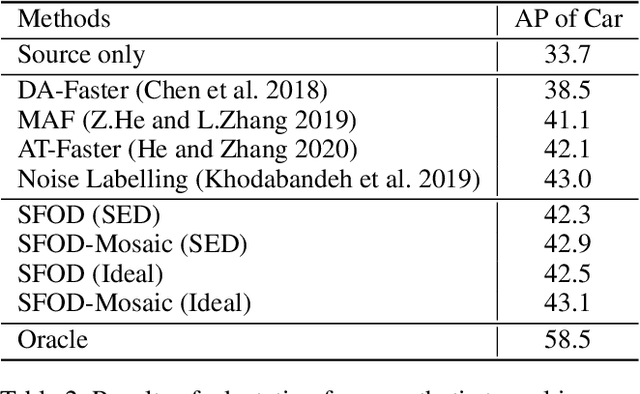
Unsupervised domain adaptation (UDA) assumes that source and target domain data are freely available and usually trained together to reduce the domain gap. However, considering the data privacy and the inefficiency of data transmission, it is impractical in real scenarios. Hence, it draws our eyes to optimize the network in the target domain without accessing labeled source data. To explore this direction in object detection, for the first time, we propose a source data-free domain adaptive object detection (SFOD) framework via modeling it into a problem of learning with noisy labels. Generally, a straightforward method is to leverage the pre-trained network from the source domain to generate the pseudo labels for target domain optimization. However, it is difficult to evaluate the quality of pseudo labels since no labels are available in target domain. In this paper, self-entropy descent (SED) is a metric proposed to search an appropriate confidence threshold for reliable pseudo label generation without using any handcrafted labels. Nonetheless, completely clean labels are still unattainable. After a thorough experimental analysis, false negatives are found to dominate in the generated noisy labels. Undoubtedly, false negatives mining is helpful for performance improvement, and we ease it to false negatives simulation through data augmentation like Mosaic. Extensive experiments conducted in four representative adaptation tasks have demonstrated that the proposed framework can easily achieve state-of-the-art performance. From another view, it also reminds the UDA community that the labeled source data are not fully exploited in the existing methods.
MGD-GAN: Text-to-Pedestrian generation through Multi-Grained Discrimination
Oct 02, 2020

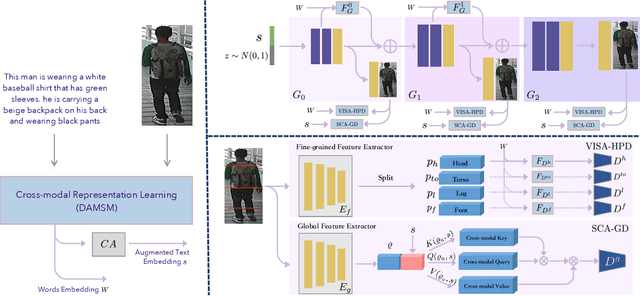

In this paper, we investigate the problem of text-to-pedestrian synthesis, which has many potential applications in art, design, and video surveillance. Existing methods for text-to-bird/flower synthesis are still far from solving this fine-grained image generation problem, due to the complex structure and heterogeneous appearance that the pedestrians naturally take on. To this end, we propose the Multi-Grained Discrimination enhanced Generative Adversarial Network, that capitalizes a human-part-based Discriminator (HPD) and a self-cross-attended (SCA) global Discriminator in order to capture the coherence of the complex body structure. A fined-grained word-level attention mechanism is employed in the HPD module to enforce diversified appearance and vivid details. In addition, two pedestrian generation metrics, named Pose Score and Pose Variance, are devised to evaluate the generation quality and diversity, respectively. We conduct extensive experiments and ablation studies on the caption-annotated pedestrian dataset, CUHK Person Description Dataset. The substantial improvement over the various metrics demonstrates the efficacy of MGD-GAN on the text-to-pedestrian synthesis scenario.
Dynamic GCN: Context-enriched Topology Learning for Skeleton-based Action Recognition
Jul 29, 2020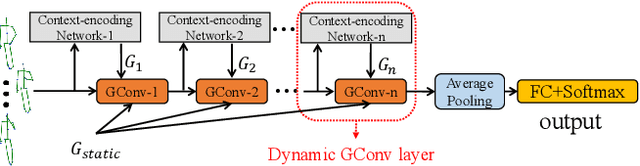

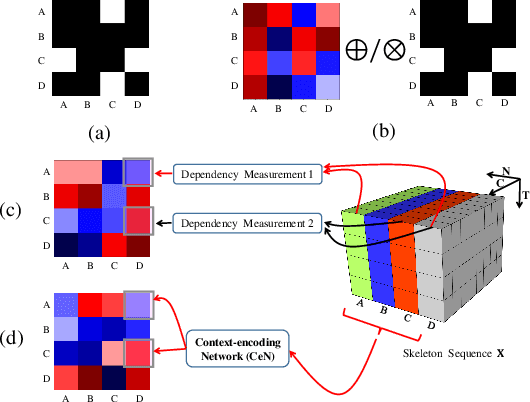
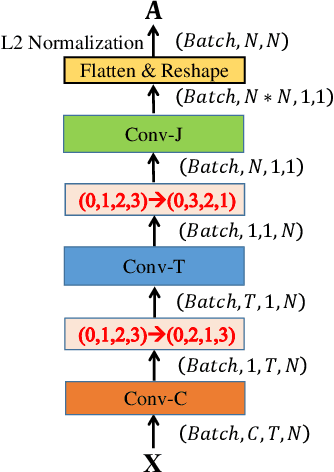
Graph Convolutional Networks (GCNs) have attracted increasing interests for the task of skeleton-based action recognition. The key lies in the design of the graph structure, which encodes skeleton topology information. In this paper, we propose Dynamic GCN, in which a novel convolutional neural network named Contextencoding Network (CeN) is introduced to learn skeleton topology automatically. In particular, when learning the dependency between two joints, contextual features from the rest joints are incorporated in a global manner. CeN is extremely lightweight yet effective, and can be embedded into a graph convolutional layer. By stacking multiple CeN-enabled graph convolutional layers, we build Dynamic GCN. Notably, as a merit of CeN, dynamic graph topologies are constructed for different input samples as well as graph convolutional layers of various depths. Besides, three alternative context modeling architectures are well explored, which may serve as a guideline for future research on graph topology learning. CeN brings only ~7% extra FLOPs for the baseline model, and Dynamic GCN achieves better performance with $2\times$~$4\times$ fewer FLOPs than existing methods. By further combining static physical body connections and motion modalities, we achieve state-of-the-art performance on three large-scale benchmarks, namely NTU-RGB+D, NTU-RGB+D 120 and Skeleton-Kinetics.
Unsupervised Image Classification for Deep Representation Learning
Jun 20, 2020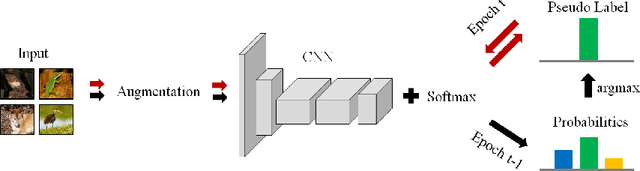
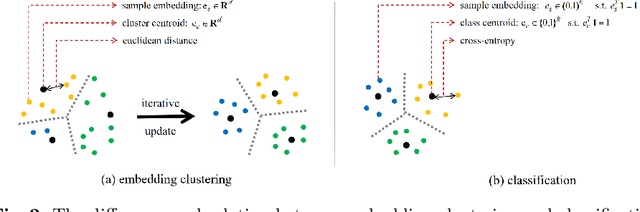
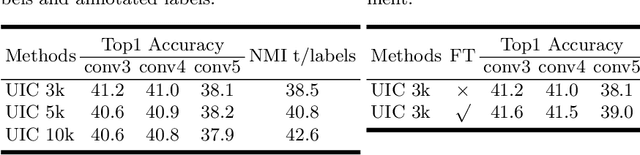

Deep clustering against self-supervised learning is a very important and promising direction for unsupervised visual representation learning since it requires little domain knowledge to design pretext tasks. However, the key component, embedding clustering, limits its extension to the extremely large-scale dataset due to its prerequisite to save the global latent embedding of the entire dataset. In this work, we aim to make this framework more simple and elegant without performance decline. We propose an unsupervised image classification framework without using embedding clustering, which is very similar to standard supervised training manner. For detailed interpretation, we further analyze its relation with deep clustering and contrastive learning. Extensive experiments on ImageNet dataset have been conducted to prove the effectiveness of our method. Furthermore, the experiments on transfer learning benchmarks have verified its generalization to other downstream tasks, including multi-label image classification, object detection, semantic segmentation and few-shot image classification.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020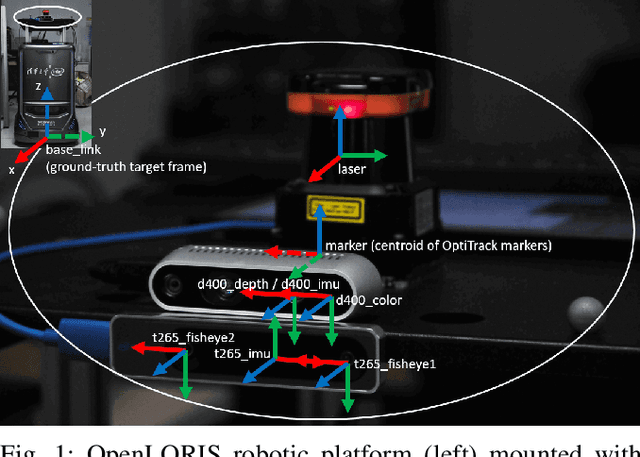
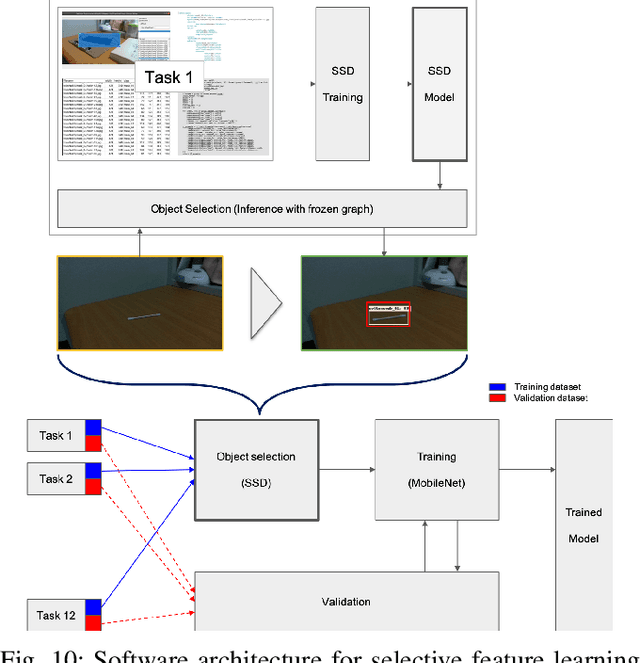


This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".