 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware RAG: Structured Retrieval Augmented Generation from Noisy Data for Conversational Agents
May 23, 2026Large Language Models (LLMs) have been widely adopted in conversational applications. However, their reliance on parametric knowledge limits reliability in real-world scenarios that require dynamic or domain-specific information. Retrieval-Augmented Generation (RAG) addresses this limitation by incorporating external knowledge during generation, but existing text-based and graph-based RAG methods often struggle with noisy or irrelevant contexts. In this work, we propose Structure-aware Retrieval Augmented Generation (SA-RAG), which uses tables as an intermediate structured representation to provide a compact and controllable interface that reduces noise while preserving essential information. We introduce a quality-aware table metadata generation framework that models metadata normalization and effectiveness, improving metadata quality and downstream performance. Furthermore, we explore both training-free and training-based table generation methods. Generation validation and direct preference optimization further improve table quality while maintaining semantic and structural consistency. Experiments on two noisy real-world datasets show that SA-RAG significantly outperforms existing RAG baselines. Our code is publicly available at a public repository.
WebForge: Breaking the Realism-Reproducibility-Scalability Trilemma in Browser Agent Benchmark
Apr 13, 2026Existing browser agent benchmarks face a fundamental trilemma: real-website benchmarks lack reproducibility due to content drift, controlled environments sacrifice realism by omitting real-web noise, and both require costly manual curation that limits scalability. We present WebForge, the first fully automated framework that resolves this trilemma through a four-agent pipeline -- Plan, Generate, Refine, and Validate -- that produces interactive, self-contained web environments end-to-end without human annotation. A seven-dimensional difficulty control framework structures task design along navigation depth, visual complexity, reasoning difficulty, and more, enabling systematic capability profiling beyond single aggregate scores. Using WebForge, we construct WebForge-Bench, a benchmark of 934 tasks spanning 7 domains and 3 difficulty levels. Multi-model experiments show that difficulty stratification effectively differentiates model capabilities, while cross-domain analysis exposes capability biases invisible to aggregate metrics. Together, these results confirm that multi-dimensional evaluation reveals distinct capability profiles that a single aggregate score cannot capture. Code and benchmark are publicly available at https://github.com/yuandaxia2001/WebForge.
VCC-DSA: A Novel Vascular Consistency Constrained DSA Imaging Model for Motion Artifact Suppression
Apr 12, 2026Digital Subtraction Angiography (DSA) is a clinically significant imaging technique for diagnosing cerebrovascular disease, as gold-standard. However, the artifacts caused by motion of high-attenuation tissues such as bones, teeth, and catheters, seriously reduce the visibility of blood vessels. This paper presents a novel Vascular Consistency Constrained DSA Imaging Model (VCC-DSA) for robust motion suppression and precise vascular imaging with the following designs: 1) We specially design a Learning-based Subtraction Mapping Paradigm, so that the ill-posed problem of existing learning-based methods can be solved to enhance the stability of the algorithm. 2) Our model effectively develops Residual Dense Blocks and details-shortcut to improve the performance under complex structures, such as moving bones overlapping with blood vessels, and small features, like peripheral vessels. 3) An innovative Vascular Consistency Strategy is proposed to extract intrinsically consistency from the various relative motions in mask-live images, so that spontaneously distils the vascular structure with contrast-agent development and robustly suppress motion artifacts, and also naturally alleviates the high matching requirements of data. 4) We creatively design a Mixup-based Data Self-evolution Strategy for data-intra self-enhancement in training loop, so that the training data gains dynamically optimized to promote model better learning the vascular features, and excluding the irrelevant structures in live/mask image and even the inevitable-artifacts/fake-structure in label. Prospectively, to further evaluate practical value, an actual general anesthesia animal experiment is specially conducted, besides the assessment on human clinical data. Compared with other method, our model improves the PSNR and SSIM by 73.4% and 8.56%, respectively.
FashionMV: Product-Level Composed Image Retrieval with Multi-View Fashion Data
Apr 11, 2026Composed Image Retrieval (CIR) retrieves target images using a reference image paired with modification text. Despite rapid advances, all existing methods and datasets operate at the image level -- a single reference image plus modification text in, a single target image out -- while real e-commerce users reason about products shown from multiple viewpoints. We term this mismatch View Incompleteness and formally define a new Multi-View CIR task that generalizes standard CIR from image-level to product-level retrieval. To support this task, we construct FashionMV, the first large-scale multi-view fashion dataset for product-level CIR, comprising 127K products, 472K multi-view images, and over 220K CIR triplets, built through a fully automated pipeline leveraging large multimodal models. We further propose ProCIR (Product-level Composed Image Retrieval), a modeling framework built upon a multimodal large language model that employs three complementary mechanisms -- two-stage dialogue, caption-based alignment, and chain-of-thought guidance -- together with an optional supervised fine-tuning (SFT) stage that injects structured product knowledge prior to contrastive training. Systematic ablation across 16 configurations on three fashion benchmarks reveals that: (1) alignment is the single most critical mechanism; (2) the two-stage dialogue architecture is a prerequisite for effective alignment; and (3) SFT and chain-of-thought serve as partially redundant knowledge injection paths. Our best 0.8B-parameter model outperforms all baselines, including general-purpose embedding models 10x its size. The dataset, model, and code are publicly available at https://github.com/yuandaxia2001/FashionMV.
Yunque DeepResearch Technical Report
Jan 27, 2026Deep research has emerged as a transformative capability for autonomous agents, empowering Large Language Models to navigate complex, open-ended tasks. However, realizing its full potential is hindered by critical limitations, including escalating contextual noise in long-horizon tasks, fragility leading to cascading errors, and a lack of modular extensibility. To address these challenges, we introduce Yunque DeepResearch, a hierarchical, modular, and robust framework. The architecture is characterized by three key components: (1) a centralized Multi-Agent Orchestration System that routes subtasks to an Atomic Capability Pool of tools and specialized sub-agents; (2) a Dynamic Context Management mechanism that structures completed sub-goals into semantic summaries to mitigate information overload; and (3) a proactive Supervisor Module that ensures resilience through active anomaly detection and context pruning. Yunque DeepResearch achieves state-of-the-art performance across a range of agentic deep research benchmarks, including GAIA, BrowseComp, BrowseComp-ZH, and Humanity's Last Exam. We open-source the framework, reproducible implementations, and application cases to empower the community.
An Integrated Sensing and Communications System Based on Affine Frequency Division Multiplexing
Jan 31, 2025



This paper proposes an integrated sensing and communications (ISAC) system based on affine frequency division multiplexing (AFDM) waveform. To this end, a metric set is designed according to not only the maximum tolerable delay/Doppler, but also the weighted spectral efficiency as well as the outage/error probability of sensing and communications. This enables the analytical investigation of the performance trade-offs of AFDM-ISAC system using the derived analytical relation among metrics and AFDM waveform parameters. Moreover, by revealing that delay and the integral/fractional parts of normalized Doppler can be decoupled in the affine Fourier transform-Doppler domain, an efficient estimation method is proposed for our AFDM-ISAC system, whose unambiguous Doppler can break through the limitation of subcarrier spacing. Theoretical analyses and numerical results verify that our proposed AFDM-ISAC system may significantly enlarge unambiguous delay/Doppler while possessing good spectral efficiency and peak-to-sidelobe level ratio in high-mobility scenarios.
MDS-GNN: A Mutual Dual-Stream Graph Neural Network on Graphs with Incomplete Features and Structure
Aug 09, 2024Graph Neural Networks (GNNs) have emerged as powerful tools for analyzing and learning representations from graph-structured data. A crucial prerequisite for the outstanding performance of GNNs is the availability of complete graph information, i.e., node features and graph structure, which is frequently unmet in real-world scenarios since graphs are often incomplete due to various uncontrollable factors. Existing approaches only focus on dealing with either incomplete features or incomplete structure, which leads to performance loss inevitably. To address this issue, this study proposes a mutual dual-stream graph neural network (MDS-GNN), which implements a mutual benefit learning between features and structure. Its main ideas are as follows: a) reconstructing the missing node features based on the initial incomplete graph structure; b) generating an augmented global graph based on the reconstructed node features, and propagating the incomplete node features on this global graph; and c) utilizing contrastive learning to make the dual-stream process mutually benefit from each other. Extensive experiments on six real-world datasets demonstrate the effectiveness of our proposed MDS-GNN on incomplete graphs.
Respiratory Subtraction for Pulmonary Microwave Ablation Evaluation
Aug 08, 2024



Currently, lung cancer is a leading cause of global cancer mortality, often necessitating minimally invasive interventions. Microwave ablation (MWA) is extensively utilized for both primary and secondary lung tumors. Although numerous clinical guidelines and standards for MWA have been established, the clinical evaluation of ablation surgery remains challenging and requires long-term patient follow-up for confirmation. In this paper, we propose a method termed respiratory subtraction to evaluate lung tumor ablation therapy performance based on pre- and post-operative image guidance. Initially, preoperative images undergo coarse rigid registration to their corresponding postoperative positions, followed by further non-rigid registration. Subsequently, subtraction images are generated by subtracting the registered preoperative images from the postoperative ones. Furthermore, to enhance the clinical assessment of MWA treatment performance, we devise a quantitative analysis metric to evaluate ablation efficacy by comparing differences between tumor areas and treatment areas. To the best of our knowledge, this is the pioneering work in the field to facilitate the assessment of MWA surgery performance on pulmonary tumors. Extensive experiments involving 35 clinical cases further validate the efficacy of the respiratory subtraction method. The experimental results confirm the effectiveness of the respiratory subtraction method and the proposed quantitative evaluation metric in assessing lung tumor treatment.
Amplify Graph Learning for Recommendation via Sparsity Completion
Jun 27, 2024



Graph learning models have been widely deployed in collaborative filtering (CF) based recommendation systems. Due to the issue of data sparsity, the graph structure of the original input lacks potential positive preference edges, which significantly reduces the performance of recommendations. In this paper, we study how to enhance the graph structure for CF more effectively, thereby optimizing the representation of graph nodes. Previous works introduced matrix completion techniques into CF, proposing the use of either stochastic completion methods or superficial structure completion to address this issue. However, most of these approaches employ random numerical filling that lack control over noise perturbations and limit the in-depth exploration of higher-order interaction features of nodes, resulting in biased graph representations. In this paper, we propose an Amplify Graph Learning framework based on Sparsity Completion (called AGL-SC). First, we utilize graph neural network to mine direct interaction features between user and item nodes, which are used as the inputs of the encoder. Second, we design a factorization-based method to mine higher-order interaction features. These features serve as perturbation factors in the latent space of the hidden layer to facilitate generative enhancement. Finally, by employing the variational inference, the above multi-order features are integrated to implement the completion and enhancement of missing graph structures. We conducted benchmark and strategy experiments on four real-world datasets related to recommendation tasks. The experimental results demonstrate that AGL-SC significantly outperforms the state-of-the-art methods.
An AFDM-Based Integrated Sensing and Communications
Aug 29, 2022
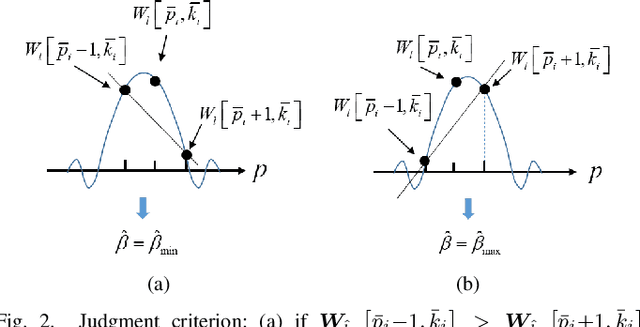
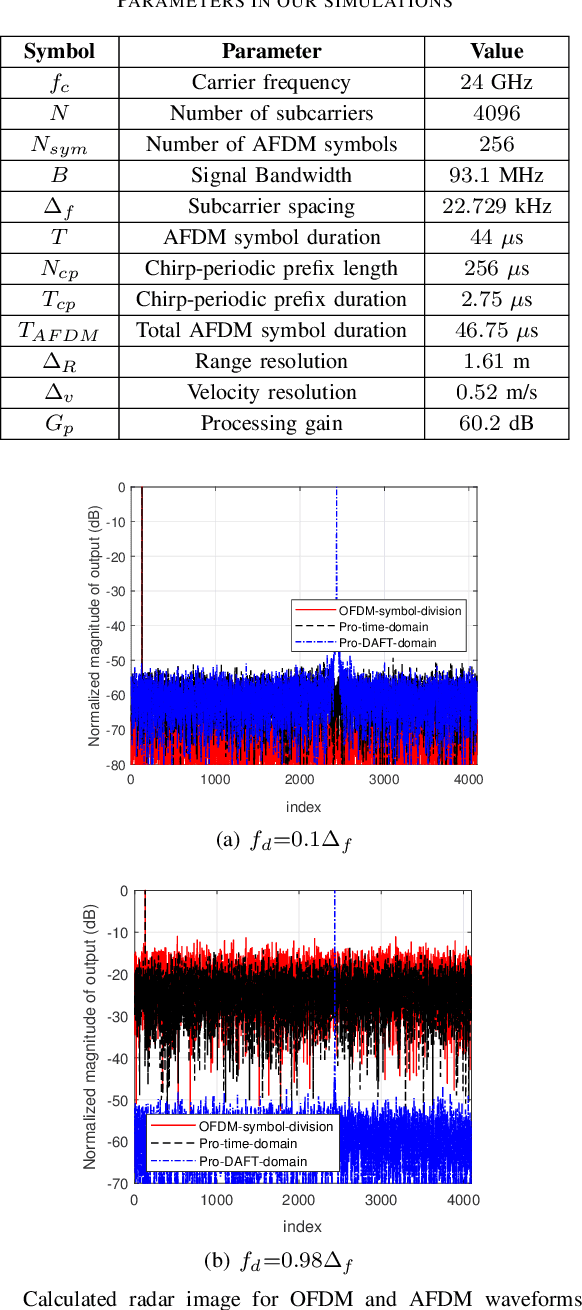
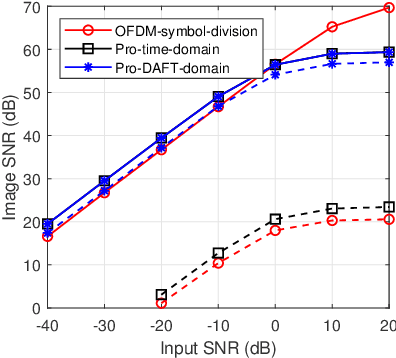
This paper considers an affine frequency division multiplexing (AFDM)-based integrated sensing and communications (ISAC) system, where the AFDM waveform is used to simultaneously carry communications information and sense targets. To realize AFDM-based sensing functionality, two parameter estimation methods are designed to process echoes in the time domain and the discrete affine Fourier transform (DAFT) domain, respectively. It allows us to decouple delay and Doppler shift in the fast time axis and can maintain good sensing performance even in large Doppler shift scenarios. Numerical results verify the effectiveness of our proposed AFDM-based system in high mobility scenarios.