 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Graph-based Framework for Scalable 3D Tree Reconstruction and Non-Destructive Biomass Estimation from Point Clouds
Jun 18, 2025Estimating forest above-ground biomass (AGB) is crucial for assessing carbon storage and supporting sustainable forest management. Quantitative Structural Model (QSM) offers a non-destructive approach to AGB estimation through 3D tree structural reconstruction. However, current QSM methods face significant limitations, as they are primarily designed for individual trees,depend on high-quality point cloud data from terrestrial laser scanning (TLS), and also require multiple pre-processing steps that hinder scalability and practical deployment. This study presents a novel unified framework that enables end-to-end processing of large-scale point clouds using an innovative graph-based pipeline. The proposed approach seamlessly integrates tree segmentation,leaf-wood separation and 3D skeletal reconstruction through dedicated graph operations including pathing and abstracting for tree topology reasoning. Comprehensive validation was conducted on datasets with varying leaf conditions (leaf-on and leaf-off), spatial scales (tree- and plot-level), and data sources (TLS and UAV-based laser scanning, ULS). Experimental results demonstrate strong performance under challenging conditions, particularly in leaf-on scenarios (~20% relative error) and low-density ULS datasets with partial coverage (~30% relative error). These findings indicate that the proposed framework provides a robust and scalable solution for large-scale, non-destructive AGB estimation. It significantly reduces dependency on specialized pre-processing tools and establishes ULS as a viable alternative to TLS. To our knowledge, this is the first method capable of enabling seamless, end-to-end 3D tree reconstruction at operational scales. This advancement substantially improves the feasibility of QSM-based AGB estimation, paving the way for broader applications in forest inventory and climate change research.
The Compositional Architecture of Regret in Large Language Models
Jun 18, 2025



Regret in Large Language Models refers to their explicit regret expression when presented with evidence contradicting their previously generated misinformation. Studying the regret mechanism is crucial for enhancing model reliability and helps in revealing how cognition is coded in neural networks. To understand this mechanism, we need to first identify regret expressions in model outputs, then analyze their internal representation. This analysis requires examining the model's hidden states, where information processing occurs at the neuron level. However, this faces three key challenges: (1) the absence of specialized datasets capturing regret expressions, (2) the lack of metrics to find the optimal regret representation layer, and (3) the lack of metrics for identifying and analyzing regret neurons. Addressing these limitations, we propose: (1) a workflow for constructing a comprehensive regret dataset through strategically designed prompting scenarios, (2) the Supervised Compression-Decoupling Index (S-CDI) metric to identify optimal regret representation layers, and (3) the Regret Dominance Score (RDS) metric to identify regret neurons and the Group Impact Coefficient (GIC) to analyze activation patterns. Our experimental results successfully identified the optimal regret representation layer using the S-CDI metric, which significantly enhanced performance in probe classification experiments. Additionally, we discovered an M-shaped decoupling pattern across model layers, revealing how information processing alternates between coupling and decoupling phases. Through the RDS metric, we categorized neurons into three distinct functional groups: regret neurons, non-regret neurons, and dual neurons.
OneRec Technical Report
Jun 16, 2025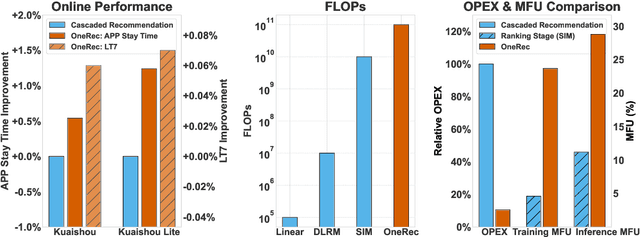

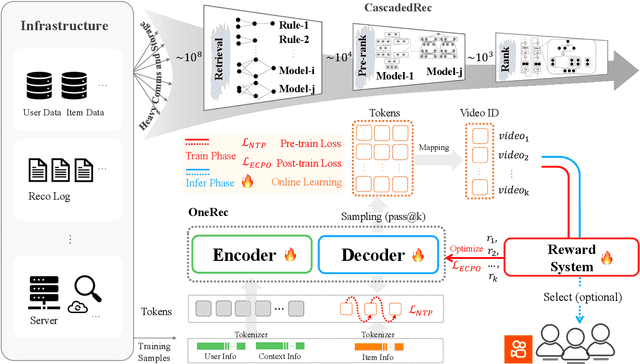
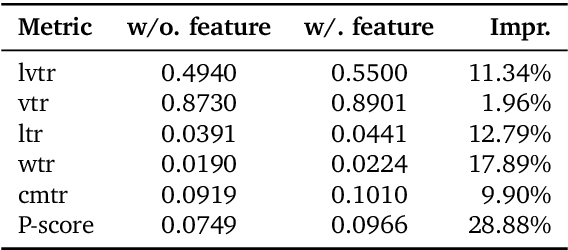
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Intra-Trajectory Consistency for Reward Modeling
Jun 10, 2025Reward models are critical for improving large language models (LLMs), particularly in reinforcement learning from human feedback (RLHF) or inference-time verification. Current reward modeling typically relies on scores of overall responses to learn the outcome rewards for the responses. However, since the response-level scores are coarse-grained supervision signals, the reward model struggles to identify the specific components within a response trajectory that truly correlate with the scores, leading to poor generalization on unseen responses. In this paper, we propose to leverage generation probabilities to establish reward consistency between processes in the response trajectory, which allows the response-level supervisory signal to propagate across processes, thereby providing additional fine-grained signals for reward learning. Building on analysis under the Bayesian framework, we develop an intra-trajectory consistency regularization to enforce that adjacent processes with higher next-token generation probability maintain more consistent rewards. We apply the proposed regularization to the advanced outcome reward model, improving its performance on RewardBench. Besides, we show that the reward model trained with the proposed regularization induces better DPO-aligned policies and achieves better best-of-N (BON) inference-time verification results. Our code is provided in https://github.com/chaoyang101/ICRM.
Flattery in Motion: Benchmarking and Analyzing Sycophancy in Video-LLMs
Jun 08, 2025As video large language models (Video-LLMs) become increasingly integrated into real-world applications that demand grounded multimodal reasoning, ensuring their factual consistency and reliability is of critical importance. However, sycophancy, the tendency of these models to align with user input even when it contradicts the visual evidence, undermines their trustworthiness in such contexts. Current sycophancy research has largely overlooked its specific manifestations in the video-language domain, resulting in a notable absence of systematic benchmarks and targeted evaluations to understand how Video-LLMs respond under misleading user input. To fill this gap, we propose VISE (Video-LLM Sycophancy Benchmarking and Evaluation), the first dedicated benchmark designed to evaluate sycophantic behavior in state-of-the-art Video-LLMs across diverse question formats, prompt biases, and visual reasoning tasks. Specifically, VISE pioneeringly brings linguistic perspectives on sycophancy into the visual domain, enabling fine-grained analysis across multiple sycophancy types and interaction patterns. In addition, we explore key-frame selection as an interpretable, training-free mitigation strategy, which reveals potential paths for reducing sycophantic bias by strengthening visual grounding.
Efficient Text-Attributed Graph Learning through Selective Annotation and Graph Alignment
Jun 08, 2025In the realm of Text-attributed Graphs (TAGs), traditional graph neural networks (GNNs) often fall short due to the complex textual information associated with each node. Recent methods have improved node representations by leveraging large language models (LLMs) to enhance node text features, but these approaches typically require extensive annotations or fine-tuning across all nodes, which is both time-consuming and costly. To overcome these challenges, we introduce GAGA, an efficient framework for TAG representation learning. GAGA reduces annotation time and cost by focusing on annotating only representative nodes and edges. It constructs an annotation graph that captures the topological relationships among these annotations. Furthermore, GAGA employs a two-level alignment module to effectively integrate the annotation graph with the TAG, aligning their underlying structures. Experiments show that GAGA achieves classification accuracies on par with or surpassing state-of-the-art methods while requiring only 1% of the data to be annotated, demonstrating its high efficiency.
Mitigating Behavioral Hallucination in Multimodal Large Language Models for Sequential Images
Jun 08, 2025



While multimodal large language models excel at various tasks, they still suffer from hallucinations, which limit their reliability and scalability for broader domain applications. To address this issue, recent research mainly focuses on objective hallucination. However, for sequential images, besides objective hallucination, there is also behavioral hallucination, which is less studied. This work aims to fill in the gap. We first reveal that behavioral hallucinations mainly arise from two key factors: prior-driven bias and the snowball effect. Based on these observations, we introduce SHE (Sequence Hallucination Eradication), a lightweight, two-stage framework that (1) detects hallucinations via visual-textual alignment check using our proposed adaptive temporal window and (2) mitigates them via orthogonal projection onto the joint embedding space. We also propose a new metric (BEACH) to quantify behavioral hallucination severity. Empirical results on standard benchmarks demonstrate that SHE reduces behavioral hallucination by over 10% on BEACH while maintaining descriptive accuracy.
Differentially Private Sparse Linear Regression with Heavy-tailed Responses
Jun 07, 2025As a fundamental problem in machine learning and differential privacy (DP), DP linear regression has been extensively studied. However, most existing methods focus primarily on either regular data distributions or low-dimensional cases with irregular data. To address these limitations, this paper provides a comprehensive study of DP sparse linear regression with heavy-tailed responses in high-dimensional settings. In the first part, we introduce the DP-IHT-H method, which leverages the Huber loss and private iterative hard thresholding to achieve an estimation error bound of \( \tilde{O}\biggl( s^{* \frac{1 }{2}} \cdot \biggl(\frac{\log d}{n}\biggr)^{\frac{\zeta}{1 + \zeta}} + s^{* \frac{1 + 2\zeta}{2 + 2\zeta}} \cdot \biggl(\frac{\log^2 d}{n \varepsilon}\biggr)^{\frac{\zeta}{1 + \zeta}} \biggr) \) under the $(\varepsilon, \delta)$-DP model, where $n$ is the sample size, $d$ is the dimensionality, $s^*$ is the sparsity of the parameter, and $\zeta \in (0, 1]$ characterizes the tail heaviness of the data. In the second part, we propose DP-IHT-L, which further improves the error bound under additional assumptions on the response and achieves \( \tilde{O}\Bigl(\frac{(s^*)^{3/2} \log d}{n \varepsilon}\Bigr). \) Compared to the first result, this bound is independent of the tail parameter $\zeta$. Finally, through experiments on synthetic and real-world datasets, we demonstrate that our methods outperform standard DP algorithms designed for ``regular'' data.
GELD: A Unified Neural Model for Efficiently Solving Traveling Salesman Problems Across Different Scales
Jun 07, 2025The Traveling Salesman Problem (TSP) is a well-known combinatorial optimization problem with broad real-world applications. Recent advancements in neural network-based TSP solvers have shown promising results. Nonetheless, these models often struggle to efficiently solve both small- and large-scale TSPs using the same set of pre-trained model parameters, limiting their practical utility. To address this issue, we introduce a novel neural TSP solver named GELD, built upon our proposed broad global assessment and refined local selection framework. Specifically, GELD integrates a lightweight Global-view Encoder (GE) with a heavyweight Local-view Decoder (LD) to enrich embedding representation while accelerating the decision-making process. Moreover, GE incorporates a novel low-complexity attention mechanism, allowing GELD to achieve low inference latency and scalability to larger-scale TSPs. Additionally, we propose a two-stage training strategy that utilizes training instances of different sizes to bolster GELD's generalization ability. Extensive experiments conducted on both synthetic and real-world datasets demonstrate that GELD outperforms seven state-of-the-art models considering both solution quality and inference speed. Furthermore, GELD can be employed as a post-processing method to significantly elevate the quality of the solutions derived by existing neural TSP solvers via spending affordable additional computing time. Notably, GELD is shown as capable of solving TSPs with up to 744,710 nodes, first-of-its-kind to solve this large size TSP without relying on divide-and-conquer strategies to the best of our knowledge.
Towards Lifecycle Unlearning Commitment Management: Measuring Sample-level Unlearning Completeness
Jun 06, 2025Growing concerns over data privacy and security highlight the importance of machine unlearning--removing specific data influences from trained models without full retraining. Techniques like Membership Inference Attacks (MIAs) are widely used to externally assess successful unlearning. However, existing methods face two key limitations: (1) maximizing MIA effectiveness (e.g., via online attacks) requires prohibitive computational resources, often exceeding retraining costs; (2) MIAs, designed for binary inclusion tests, struggle to capture granular changes in approximate unlearning. To address these challenges, we propose the Interpolated Approximate Measurement (IAM), a framework natively designed for unlearning inference. IAM quantifies sample-level unlearning completeness by interpolating the model's generalization-fitting behavior gap on queried samples. IAM achieves strong performance in binary inclusion tests for exact unlearning and high correlation for approximate unlearning--scalable to LLMs using just one pre-trained shadow model. We theoretically analyze how IAM's scoring mechanism maintains performance efficiently. We then apply IAM to recent approximate unlearning algorithms, revealing general risks of both over-unlearning and under-unlearning, underscoring the need for stronger safeguards in approximate unlearning systems. The code is available at https://github.com/Happy2Git/Unlearning_Inference_IAM.