 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRaQ: Optimized Low Rank Approximation for 4-bit Quantization
Apr 20, 2026Post-training quantization (PTQ) is essential for deploying large diffusion transformers on resource-constrained hardware, but aggressive 4-bit quantization significantly degrades generative performance. Low-rank approximation methods have emerged as a promising solution by appending auxiliary linear branches to restore performance. However, current state-of-the-art approaches assume these branches must retain high precision (W16A16) and rely on heavy, data-dependent calibration for initialization. We challenge both limitations with LoRaQ (Low-Rank Approximated Quantization), a simple, data-free calibration approach that optimizes quantization error compensation. By overcoming the need for high-precision branches, LoRaQ enables the first fully sub-16 bit pipeline, allowing the low-rank branch itself to be quantized. We demonstrate that, at equal memory overhead, LoRaQ outperforms the state-of-the-art methods in their native implementations on Pixart-$Σ$ and SANA. We also analyze mixed-precision configurations, showing that setups such as W8A8, W6A6, and W4A8 for the low-rank branch, alongside a W4 main layer, yield superior results while maintaining a fully quantized architecture compatible with modern mixed-precision hardware.
AdaHOP: Fast and Accurate Low-Precision Training via Outlier-Pattern-Aware Rotation
Apr 02, 2026Low-precision training (LPT) commonly employs Hadamard transforms to suppress outliers and mitigate quantization error in large language models (LLMs). However, prior methods apply a fixed transform uniformly, despite substantial variation in outlier structures across tensors. Through the first systematic study of outlier patterns across weights, activations, and gradients of LLMs, we show that this strategy is fundamentally flawed: the effectiveness of Hadamard-based suppression depends on how the transform's smoothing direction aligns with the outlier structure of each operand -- a property that varies substantially across layers and computation paths. We characterize these patterns into three types: Row-wise, Column-wise, and None. Each pair requires a tailored transform direction or outlier handling strategy to minimize quantization error. Based on this insight, we propose AdaHOP (Adaptive Hadamard transform with Outlier-Pattern-aware strategy), which assigns each matrix multiplication its optimal strategy: Inner Hadamard Transform (IHT) where inner-dimension smoothing is effective, or IHT combined with selective Outlier Extraction (OE) -- routing dominant outliers to a high-precision path -- where it is not. Combined with hardware-aware Triton kernels, AdaHOP achieves BF16 training quality at MXFP4 precision while delivering up to 3.6X memory compression and 1.8X kernel acceleration} over BF16 full-precision training.
Error Diffusion: Post Training Quantization with Block-Scaled Number Formats for Neural Networks
Oct 15, 2024



Quantization reduces the model's hardware costs, such as data movement, storage, and operations like multiply and addition. It also affects the model's behavior by degrading the output quality. Therefore, there is a need for methods that preserve the model's behavior when quantizing model parameters. More exotic numerical encodings, such as block-scaled number formats, have shown advantages for utilizing a fixed bit budget to encode model parameters. This paper presents error diffusion (ED), a hyperparameter-free method for post-training quantization with support for block-scaled data formats. Our approach does not rely on backpropagation or Hessian information. We describe how to improve the quantization process by viewing the neural model as a composite function and diffusing the quantization error in every layer. In addition, we introduce TensorCast, an open-source library based on PyTorch to emulate a variety of number formats, including the block-scaled ones, to aid the research in neural model quantization. We demonstrate the efficacy of our algorithm through rigorous testing on various architectures, including vision and large language models (LLMs), where it consistently delivers competitive results. Our experiments confirm that block-scaled data formats provide a robust choice for post-training quantization and could be used effectively to enhance the practical deployment of advanced neural networks.
Microscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
Tailor: Altering Skip Connections for Resource-Efficient Inference
Jan 18, 2023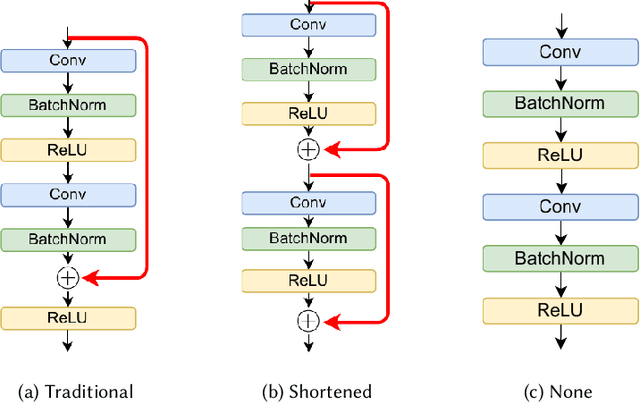



Deep neural networks use skip connections to improve training convergence. However, these skip connections are costly in hardware, requiring extra buffers and increasing on- and off-chip memory utilization and bandwidth requirements. In this paper, we show that skip connections can be optimized for hardware when tackled with a hardware-software codesign approach. We argue that while a network's skip connections are needed for the network to learn, they can later be removed or shortened to provide a more hardware efficient implementation with minimal to no accuracy loss. We introduce Tailor, a codesign tool whose hardware-aware training algorithm gradually removes or shortens a fully trained network's skip connections to lower their hardware cost. The optimized hardware designs improve resource utilization by up to 34% for BRAMs, 13% for FFs, and 16% for LUTs.