 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
Accelerating Transformer Inference and Training with 2:4 Activation Sparsity
Mar 20, 2025



In this paper, we demonstrate how to leverage 2:4 sparsity, a popular hardware-accelerated GPU sparsity pattern, to activations to accelerate large language model training and inference. Crucially we exploit the intrinsic sparsity found in Squared-ReLU activations to provide this acceleration with no accuracy loss. Our approach achieves up to 1.3x faster Feed Forward Network (FFNs) in both the forwards and backwards pass. This work highlights the potential for sparsity to play a key role in accelerating large language model training and inference.
Inference-time sparse attention with asymmetric indexing
Feb 12, 2025
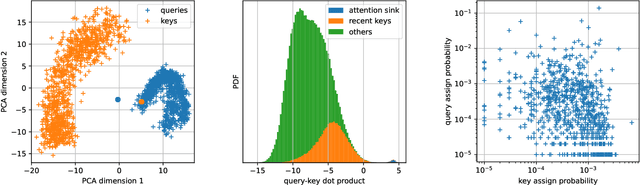


Self-attention in transformer models is an incremental associative memory that maps key vectors to value vectors. One way to speed up self-attention is to employ GPU-compliant vector search algorithms, yet the standard partitioning methods yield poor results in this context, because (1) keys and queries follow different distributions and (2) the effect of RoPE positional encoding. In this paper, we introduce SAAP (Self-Attention with Asymmetric Partitions), which overcomes these problems. It is an asymmetrical indexing technique that employs distinct partitions for keys and queries, thereby approximating self-attention with a data-adaptive sparsity pattern. It works on pretrained language models without finetuning, as it only requires to train (offline) a small query classifier. On a long context Llama 3.1-8b model, with sequences ranging from 100k to 500k tokens, our method typically reduces by a factor 20 the fraction of memory that needs to be looked-up, which translates to a time saving of 60\% when compared to FlashAttention-v2.
SimpleFSDP: Simpler Fully Sharded Data Parallel with torch.compile
Nov 01, 2024



Distributed training of large models consumes enormous computation resources and requires substantial engineering efforts to compose various training techniques. This paper presents SimpleFSDP, a PyTorch-native compiler-based Fully Sharded Data Parallel (FSDP) framework, which has a simple implementation for maintenance and composability, allows full computation-communication graph tracing, and brings performance enhancement via compiler backend optimizations. SimpleFSDP's novelty lies in its unique torch.compile-friendly implementation of collective communications using existing PyTorch primitives, namely parametrizations, selective activation checkpointing, and DTensor. It also features the first-of-its-kind intermediate representation (IR) nodes bucketing and reordering in the TorchInductor backend for effective computation-communication overlapping. As a result, users can employ the aforementioned optimizations to automatically or manually wrap model components for minimal communication exposure. Extensive evaluations of SimpleFSDP on Llama 3 models (including the ultra-large 405B) using TorchTitan demonstrate up to 28.54% memory reduction and 68.67% throughput improvement compared to the most widely adopted FSDP2 eager framework, when composed with other distributed training techniques.
DINOv2: Learning Robust Visual Features without Supervision
Apr 14, 2023



The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.
Hybrid Transformers for Music Source Separation
Nov 15, 2022



A natural question arising in Music Source Separation (MSS) is whether long range contextual information is useful, or whether local acoustic features are sufficient. In other fields, attention based Transformers have shown their ability to integrate information over long sequences. In this work, we introduce Hybrid Transformer Demucs (HT Demucs), an hybrid temporal/spectral bi-U-Net based on Hybrid Demucs, where the innermost layers are replaced by a cross-domain Transformer Encoder, using self-attention within one domain, and cross-attention across domains. While it performs poorly when trained only on MUSDB, we show that it outperforms Hybrid Demucs (trained on the same data) by 0.45 dB of SDR when using 800 extra training songs. Using sparse attention kernels to extend its receptive field, and per source fine-tuning, we achieve state-of-the-art results on MUSDB with extra training data, with 9.20 dB of SDR.
Training data-efficient image transformers & distillation through attention
Jan 15, 2021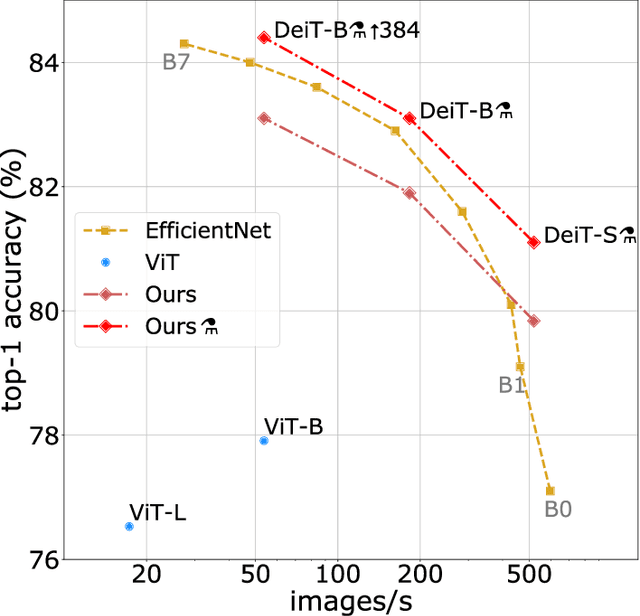
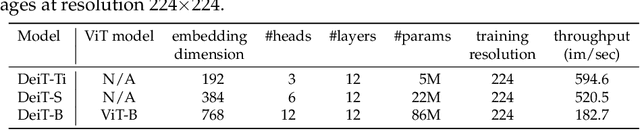
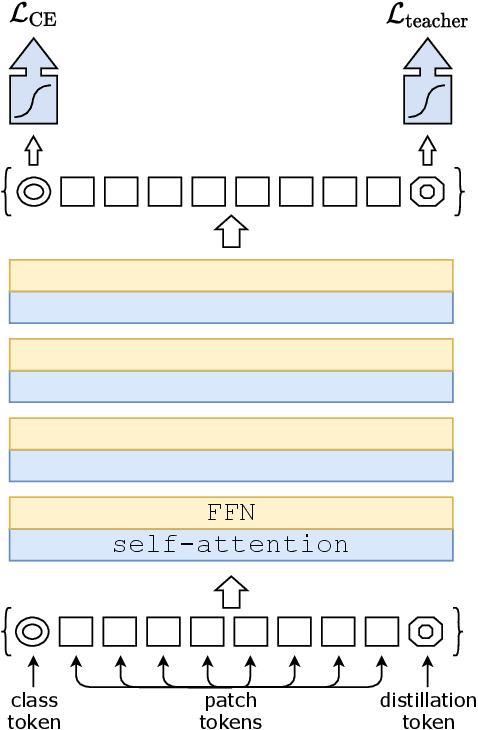
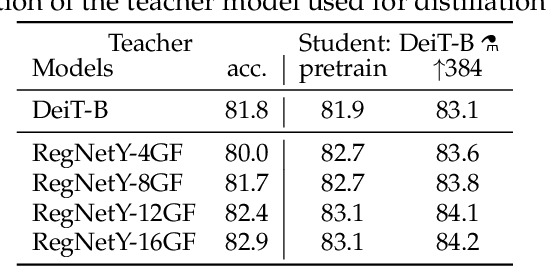
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. However, these visual transformers are pre-trained with hundreds of millions of images using an expensive infrastructure, thereby limiting their adoption. In this work, we produce a competitive convolution-free transformer by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external data. More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention. We show the interest of this token-based distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks. We share our code and models.
End-to-End Object Detection with Transformers
May 28, 2020
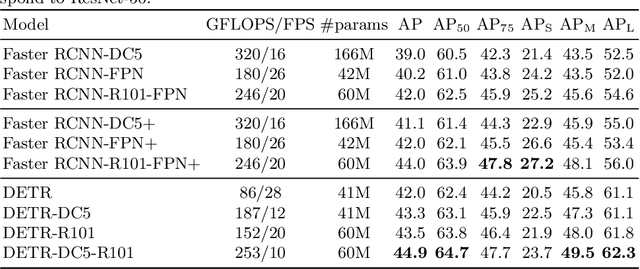
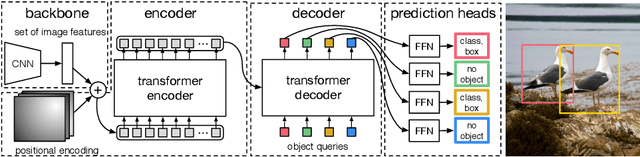
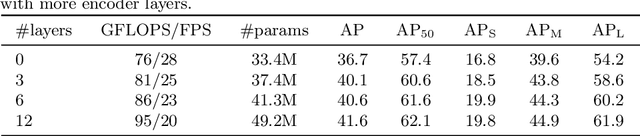
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive baselines. Training code and pretrained models are available at https://github.com/facebookresearch/detr.
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019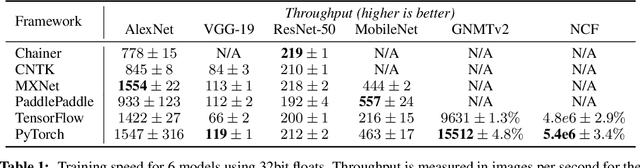

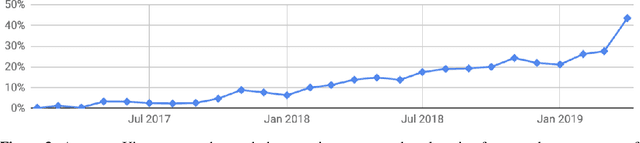
Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.