 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast-to-Most Prompting Enables Complex Reasoning in Large Language Models
May 21, 2022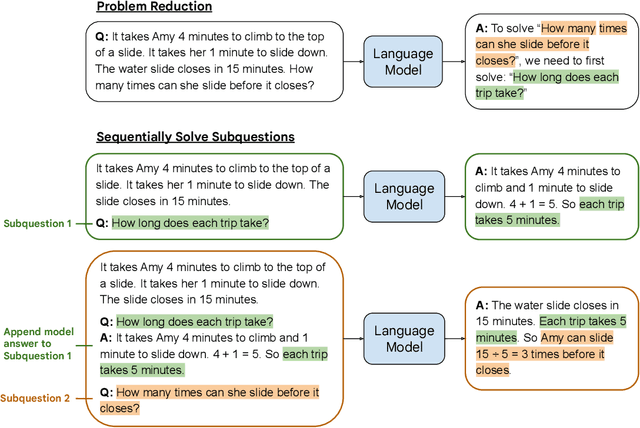



We propose a novel prompting strategy, least-to-most prompting, that enables large language models to better perform multi-step reasoning tasks. Least-to-most prompting first reduces a complex problem into a list of subproblems, and then sequentially solves the subproblems, whereby solving a given subproblem is facilitated by the model's answers to previously solved subproblems. Experiments on symbolic manipulation, compositional generalization and numerical reasoning demonstrate that least-to-most prompting can generalize to examples that are harder than those seen in the prompt context, outperforming other prompting-based approaches by a large margin. A notable empirical result is that the GPT-3 code-davinci-002 model with least-to-most-prompting can solve the SCAN benchmark with an accuracy of 99.7% using 14 examples. As a comparison, the neural-symbolic models in the literature specialized for solving SCAN are trained with the full training set of more than 15,000 examples.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Apr 06, 2022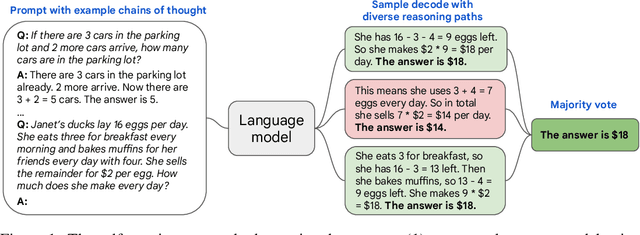
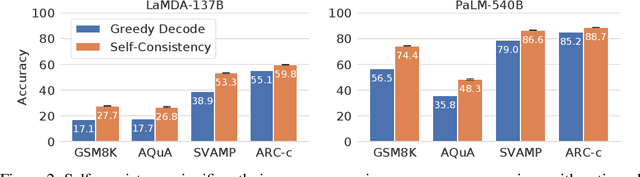
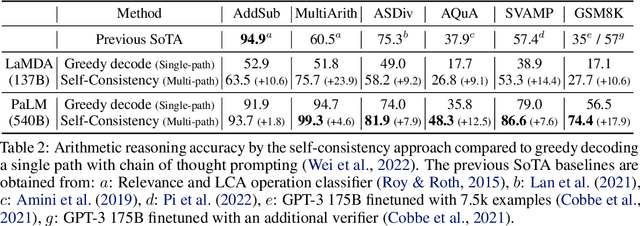
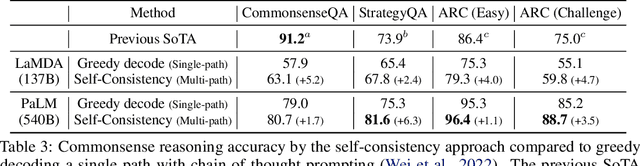
We explore a simple ensemble strategy, self-consistency, that significantly improves the reasoning accuracy of large language models. The idea is to sample a diverse set of reasoning paths from a language model via chain of thought prompting then return the most consistent final answer in the set. We evaluate self-consistency on a range of arithmetic and commonsense reasoning benchmarks, and find that it robustly improves accuracy across a variety of language models and model scales without the need for additional training or auxiliary models. When combined with a recent large language model, PaLM-540B, self-consistency increases performance to state-of-the-art levels across several benchmark reasoning tasks, including GSM8K (56.5% -> 74.4%), SVAMP (79.0% -> 86.6%), AQuA (35.8% -> 48.3%), StrategyQA (75.3% -> 81.6%) and ARC-challenge (85.2% -> 88.7%).
Token Dropping for Efficient BERT Pretraining
Mar 24, 2022
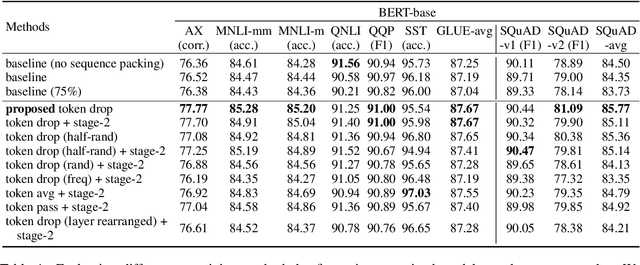
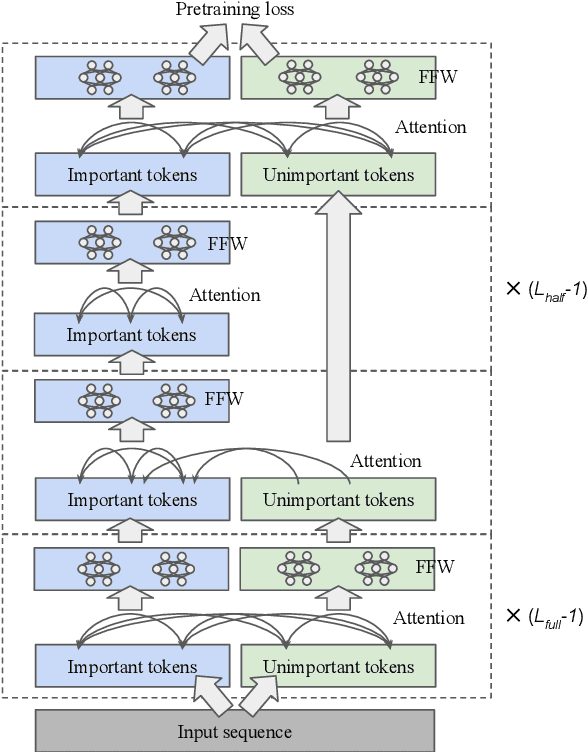
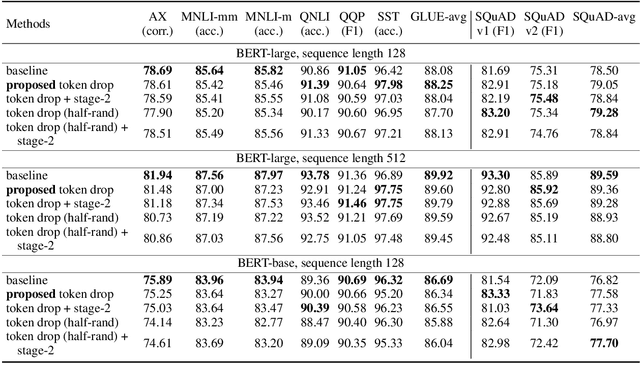
Transformer-based models generally allocate the same amount of computation for each token in a given sequence. We develop a simple but effective "token dropping" method to accelerate the pretraining of transformer models, such as BERT, without degrading its performance on downstream tasks. In short, we drop unimportant tokens starting from an intermediate layer in the model to make the model focus on important tokens; the dropped tokens are later picked up by the last layer of the model so that the model still produces full-length sequences. We leverage the already built-in masked language modeling (MLM) loss to identify unimportant tokens with practically no computational overhead. In our experiments, this simple approach reduces the pretraining cost of BERT by 25% while achieving similar overall fine-tuning performance on standard downstream tasks.
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
Mar 15, 2022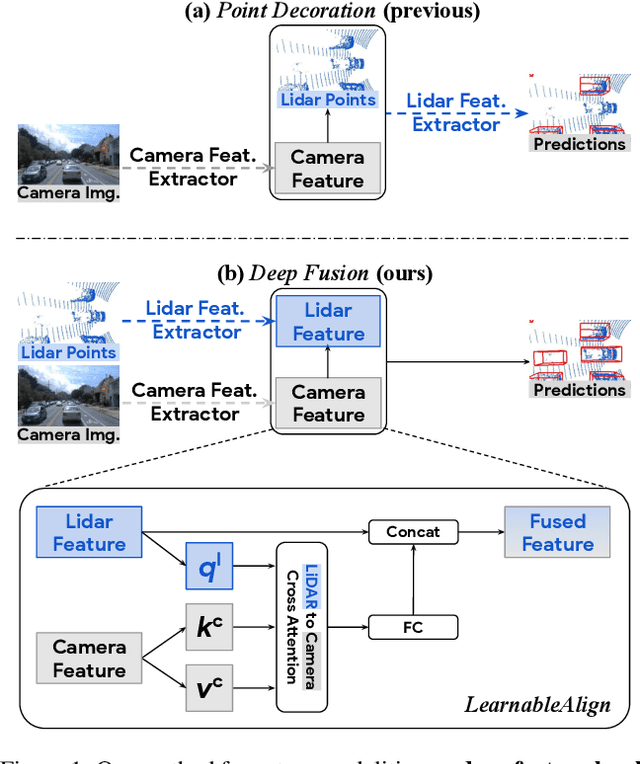
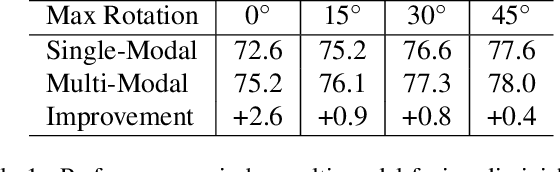
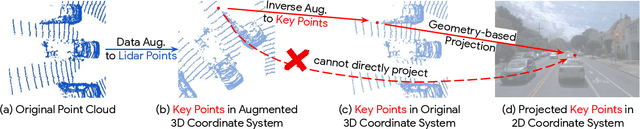
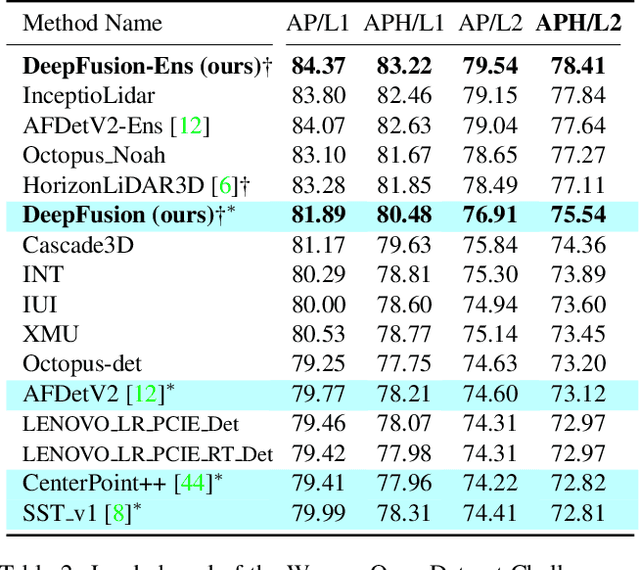
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While prevalent multi-modal methods simply decorate raw lidar point clouds with camera features and feed them directly to existing 3D detection models, our study shows that fusing camera features with deep lidar features instead of raw points, can lead to better performance. However, as those features are often augmented and aggregated, a key challenge in fusion is how to effectively align the transformed features from two modalities. In this paper, we propose two novel techniques: InverseAug that inverses geometric-related augmentations, e.g., rotation, to enable accurate geometric alignment between lidar points and image pixels, and LearnableAlign that leverages cross-attention to dynamically capture the correlations between image and lidar features during fusion. Based on InverseAug and LearnableAlign, we develop a family of generic multi-modal 3D detection models named DeepFusion, which is more accurate than previous methods. For example, DeepFusion improves PointPillars, CenterPoint, and 3D-MAN baselines on Pedestrian detection for 6.7, 8.9, and 6.2 LEVEL_2 APH, respectively. Notably, our models achieve state-of-the-art performance on Waymo Open Dataset, and show strong model robustness against input corruptions and out-of-distribution data. Code will be publicly available at https://github.com/tensorflow/lingvo/tree/master/lingvo/.
Auto-scaling Vision Transformers without Training
Feb 27, 2022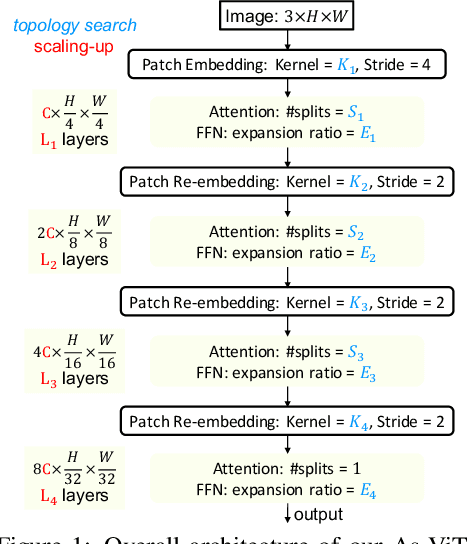
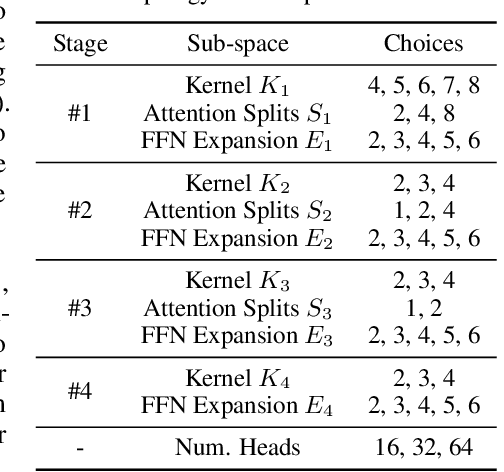
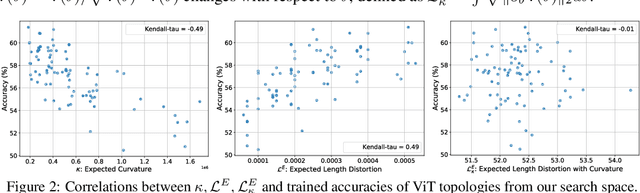
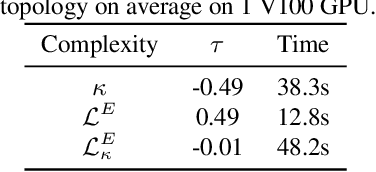
This work targets automated designing and scaling of Vision Transformers (ViTs). The motivation comes from two pain spots: 1) the lack of efficient and principled methods for designing and scaling ViTs; 2) the tremendous computational cost of training ViT that is much heavier than its convolution counterpart. To tackle these issues, we propose As-ViT, an auto-scaling framework for ViTs without training, which automatically discovers and scales up ViTs in an efficient and principled manner. Specifically, we first design a "seed" ViT topology by leveraging a training-free search process. This extremely fast search is fulfilled by a comprehensive study of ViT's network complexity, yielding a strong Kendall-tau correlation with ground-truth accuracies. Second, starting from the "seed" topology, we automate the scaling rule for ViTs by growing widths/depths to different ViT layers. This results in a series of architectures with different numbers of parameters in a single run. Finally, based on the observation that ViTs can tolerate coarse tokenization in early training stages, we propose a progressive tokenization strategy to train ViTs faster and cheaper. As a unified framework, As-ViT achieves strong performance on classification (83.5% top1 on ImageNet-1k) and detection (52.7% mAP on COCO) without any manual crafting nor scaling of ViT architectures: the end-to-end model design and scaling process cost only 12 hours on one V100 GPU. Our code is available at https://github.com/VITA-Group/AsViT.
Provable Stochastic Optimization for Global Contrastive Learning: Small Batch Does Not Harm Performance
Feb 24, 2022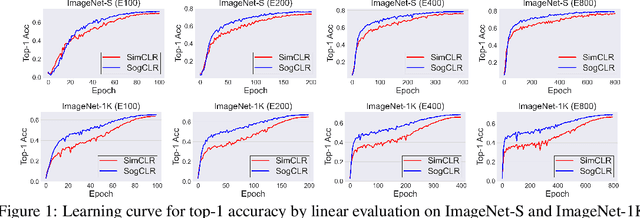
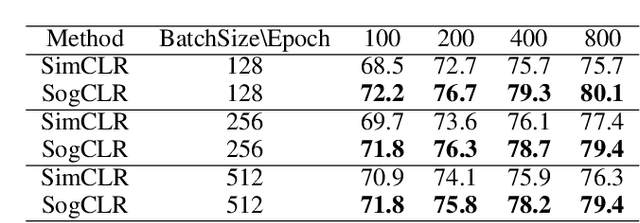
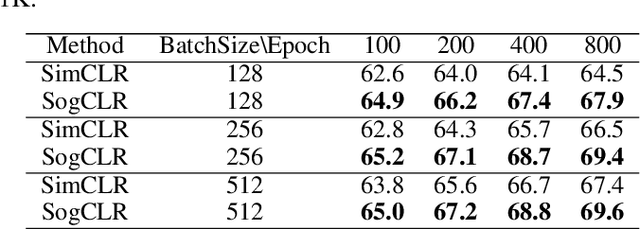
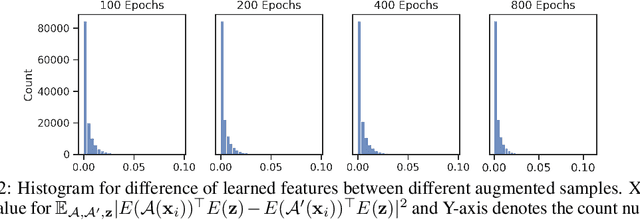
In this paper, we study contrastive learning from an optimization perspective, aiming to analyze and address a fundamental issue of existing contrastive learning methods that either rely on a large batch size or a large dictionary. We consider a global objective for contrastive learning, which contrasts each positive pair with all negative pairs for an anchor point. From the optimization perspective, we explain why existing methods such as SimCLR requires a large batch size in order to achieve a satisfactory result. In order to remove such requirement, we propose a memory-efficient Stochastic Optimization algorithm for solving the Global objective of Contrastive Learning of Representations, named SogCLR. We show that its optimization error is negligible under a reasonable condition after a sufficient number of iterations or is diminishing for a slightly different global contrastive objective. Empirically, we demonstrate that on ImageNet with a batch size 256, SogCLR achieves a performance of 69.4% for top-1 linear evaluation accuracy using ResNet-50, which is on par with SimCLR (69.3%) with a large batch size 8,192. We also attempt to show that the proposed optimization technique is generic and can be applied to solving other contrastive losses, e.g., two-way contrastive losses for bimodal contrastive learning.
Chain of Thought Prompting Elicits Reasoning in Large Language Models
Jan 28, 2022



Although scaling up language model size has reliably improved performance on a range of NLP tasks, even the largest models currently struggle with certain reasoning tasks such as math word problems, symbolic manipulation, and commonsense reasoning. This paper explores the ability of language models to generate a coherent chain of thought -- a series of short sentences that mimic the reasoning process a person might have when responding to a question. Experiments show that inducing a chain of thought via prompting can enable sufficiently large language models to better perform reasoning tasks that otherwise have flat scaling curves.
A Simple Single-Scale Vision Transformer for Object Localization and Instance Segmentation
Dec 17, 2021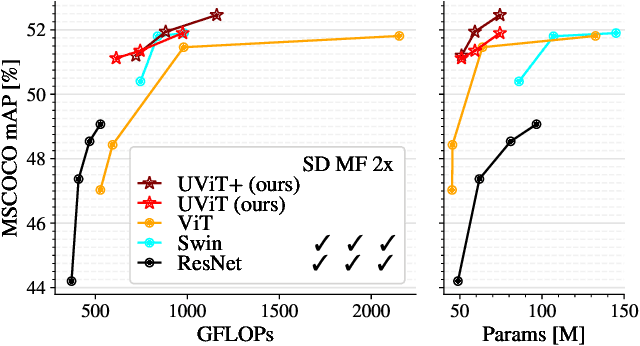

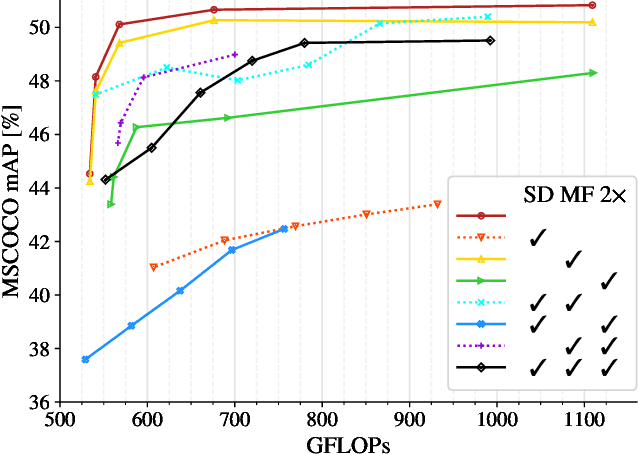

This work presents a simple vision transformer design as a strong baseline for object localization and instance segmentation tasks. Transformers recently demonstrate competitive performance in image classification tasks. To adopt ViT to object detection and dense prediction tasks, many works inherit the multistage design from convolutional networks and highly customized ViT architectures. Behind this design, the goal is to pursue a better trade-off between computational cost and effective aggregation of multiscale global contexts. However, existing works adopt the multistage architectural design as a black-box solution without a clear understanding of its true benefits. In this paper, we comprehensively study three architecture design choices on ViT -- spatial reduction, doubled channels, and multiscale features -- and demonstrate that a vanilla ViT architecture can fulfill this goal without handcrafting multiscale features, maintaining the original ViT design philosophy. We further complete a scaling rule to optimize our model's trade-off on accuracy and computation cost / model size. By leveraging a constant feature resolution and hidden size throughout the encoder blocks, we propose a simple and compact ViT architecture called Universal Vision Transformer (UViT) that achieves strong performance on COCO object detection and instance segmentation tasks.
SMORE: Knowledge Graph Completion and Multi-hop Reasoning in Massive Knowledge Graphs
Nov 01, 2021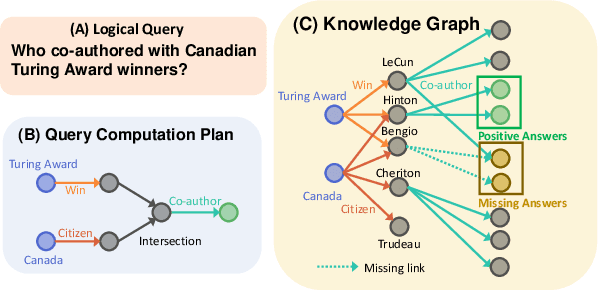

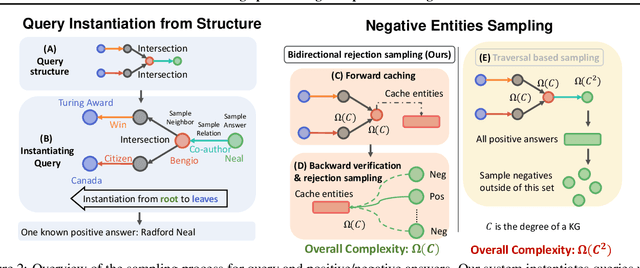
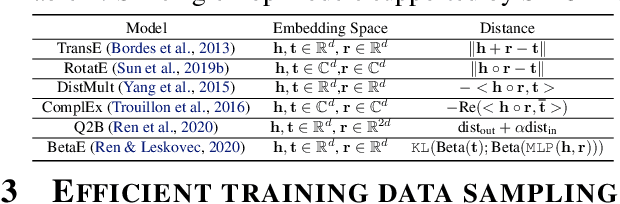
Knowledge graphs (KGs) capture knowledge in the form of head--relation--tail triples and are a crucial component in many AI systems. There are two important reasoning tasks on KGs: (1) single-hop knowledge graph completion, which involves predicting individual links in the KG; and (2), multi-hop reasoning, where the goal is to predict which KG entities satisfy a given logical query. Embedding-based methods solve both tasks by first computing an embedding for each entity and relation, then using them to form predictions. However, existing scalable KG embedding frameworks only support single-hop knowledge graph completion and cannot be applied to the more challenging multi-hop reasoning task. Here we present Scalable Multi-hOp REasoning (SMORE), the first general framework for both single-hop and multi-hop reasoning in KGs. Using a single machine SMORE can perform multi-hop reasoning in Freebase KG (86M entities, 338M edges), which is 1,500x larger than previously considered KGs. The key to SMORE's runtime performance is a novel bidirectional rejection sampling that achieves a square root reduction of the complexity of online training data generation. Furthermore, SMORE exploits asynchronous scheduling, overlapping CPU-based data sampling, GPU-based embedding computation, and frequent CPU--GPU IO. SMORE increases throughput (i.e., training speed) over prior multi-hop KG frameworks by 2.2x with minimal GPU memory requirements (2GB for training 400-dim embeddings on 86M-node Freebase) and achieves near linear speed-up with the number of GPUs. Moreover, on the simpler single-hop knowledge graph completion task SMORE achieves comparable or even better runtime performance to state-of-the-art frameworks on both single GPU and multi-GPU settings.