 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLQ: Bridging Modalities via Shared Latent Queries for Retrieval with Frozen MLLMs
Apr 16, 2026Multimodal Large Language Models (MLLMs) exhibit strong reasoning and world knowledge, yet adapting them for retrieval remains challenging. Existing approaches rely on invasive parameter updates, such as full fine-tuning and LoRA, which may disrupt the pre-trained semantic space and impair the structured knowledge essential for reasoning. In this work, we argue that adapting MLLMs for retrieval should focus on eliciting pre-trained representations rather than overwriting them. To this end, we propose SLQ, an effective and efficient framework that adapts a frozen MLLM into a retriever through a small set of Shared Latent Queries. Appended to the end of both text and image token sequences, these queries leverage the model's native causal attention to serve as global aggregation interfaces, producing compact embeddings in a unified space while keeping the backbone unchanged. Furthermore, to better evaluate retrieval beyond superficial pattern matching, we construct KARR-Bench, a benchmark designed for knowledge-aware reasoning retrieval. Extensive experiments show that SLQ outperforms full fine-tuning and LoRA on COCO and Flickr30K, while achieving competitive performance on MMEB and yielding substantial gains on KARR-Bench. The results demonstrate that SLQ, which preserves pre-trained representations, provides an effective and efficient framework for adapting MLLMs to retrieval.
MIMIC-SR-ICD11: A Dataset for Narrative-Based Diagnosis
Nov 07, 2025



Disease diagnosis is a central pillar of modern healthcare, enabling early detection and timely intervention for acute conditions while guiding lifestyle adjustments and medication regimens to prevent or slow chronic disease. Self-reports preserve clinically salient signals that templated electronic health record (EHR) documentation often attenuates or omits, especially subtle but consequential details. To operationalize this shift, we introduce MIMIC-SR-ICD11, a large English diagnostic dataset built from EHR discharge notes and natively aligned to WHO ICD-11 terminology. We further present LL-Rank, a likelihood-based re-ranking framework that computes a length-normalized joint likelihood of each label given the clinical report context and subtracts the corresponding report-free prior likelihood for that label. Across seven model backbones, LL-Rank consistently outperforms a strong generation-plus-mapping baseline (GenMap). Ablation experiments show that LL-Rank's gains primarily stem from its PMI-based scoring, which isolates semantic compatibility from label frequency bias.
MIND: A Multi-agent Framework for Zero-shot Harmful Meme Detection
Jul 09, 2025



The rapid expansion of memes on social media has highlighted the urgent need for effective approaches to detect harmful content. However, traditional data-driven approaches struggle to detect new memes due to their evolving nature and the lack of up-to-date annotated data. To address this issue, we propose MIND, a multi-agent framework for zero-shot harmful meme detection that does not rely on annotated data. MIND implements three key strategies: 1) We retrieve similar memes from an unannotated reference set to provide contextual information. 2) We propose a bi-directional insight derivation mechanism to extract a comprehensive understanding of similar memes. 3) We then employ a multi-agent debate mechanism to ensure robust decision-making through reasoned arbitration. Extensive experiments on three meme datasets demonstrate that our proposed framework not only outperforms existing zero-shot approaches but also shows strong generalization across different model architectures and parameter scales, providing a scalable solution for harmful meme detection. The code is available at https://github.com/destroy-lonely/MIND.
Distilling Text Style Transfer With Self-Explanation From LLMs
Mar 02, 2024



Text Style Transfer (TST) seeks to alter the style of text while retaining its core content. Given the constraints of limited parallel datasets for TST, we propose CoTeX, a framework that leverages large language models (LLMs) alongside chain-of-thought (CoT) prompting to facilitate TST. CoTeX distills the complex rewriting and reasoning capabilities of LLMs into more streamlined models capable of working with both non-parallel and parallel data. Through experimentation across four TST datasets, CoTeX is shown to surpass traditional supervised fine-tuning and knowledge distillation methods, particularly in low-resource settings. We conduct a comprehensive evaluation, comparing CoTeX against current unsupervised, supervised, in-context learning (ICL) techniques, and instruction-tuned LLMs. Furthermore, CoTeX distinguishes itself by offering transparent explanations for its style transfer process.
Multi-step Problem Solving Through a Verifier: An Empirical Analysis on Model-induced Process Supervision
Feb 05, 2024



Process supervision, using a trained verifier to evaluate the intermediate steps generated by reasoner, has demonstrated significant improvements in multi-step problem solving. In this paper, to avoid expensive human annotation effort on the verifier training data, we introduce Model-induced Process Supervision (MiPS), a novel method for automating data curation. MiPS annotates an intermediate step by sampling completions of this solution through the reasoning model, and obtaining an accuracy defined as the proportion of correct completions. Errors in the reasoner would cause MiPS to underestimate the accuracy of intermediate steps, therefore, we suggest and empirically show that verification focusing on high predicted scores of the verifier shall be preferred over that of low predicted scores, contrary to prior work. Our approach significantly improves the performance of PaLM 2 on math and coding tasks (accuracy +0.67% on GSM8K, +4.16% on MATH, +0.92% on MBPP compared with an output supervision trained verifier). Additionally, our study demonstrates that the verifier exhibits strong generalization ability across different reasoning models.
Enable Language Models to Implicitly Learn Self-Improvement From Data
Oct 05, 2023



Large Language Models (LLMs) have demonstrated remarkable capabilities in open-ended text generation tasks. However, the inherent open-ended nature of these tasks implies that there is always room for improvement in the quality of model responses. To address this challenge, various approaches have been proposed to enhance the performance of LLMs. There has been a growing focus on enabling LLMs to self-improve their response quality, thereby reducing the reliance on extensive human annotation efforts for collecting diverse and high-quality training data. Recently, prompting-based methods have been widely explored among self-improvement methods owing to their effectiveness, efficiency, and convenience. However, those methods usually require explicitly and thoroughly written rubrics as inputs to LLMs. It is expensive and challenging to manually derive and provide all necessary rubrics with a real-world complex goal for improvement (e.g., being more helpful and less harmful). To this end, we propose an ImPlicit Self-ImprovemenT (PIT) framework that implicitly learns the improvement goal from human preference data. PIT only requires preference data that are used to train reward models without extra human efforts. Specifically, we reformulate the training objective of reinforcement learning from human feedback (RLHF) -- instead of maximizing response quality for a given input, we maximize the quality gap of the response conditioned on a reference response. In this way, PIT is implicitly trained with the improvement goal of better aligning with human preferences. Experiments on two real-world datasets and one synthetic dataset show that our method significantly outperforms prompting-based methods.
Flan-MoE: Scaling Instruction-Finetuned Language Models with Sparse Mixture of Experts
May 24, 2023The explosive growth of language models and their applications have led to an increased demand for efficient and scalable methods. In this paper, we introduce Flan-MoE, a set of Instruction-Finetuned Sparse Mixture-of-Expert (MoE) models. We show that naively finetuning MoE models on a task-specific dataset (in other words, no instruction-finetuning) often yield worse performance compared to dense models of the same computational complexity. However, our Flan-MoE outperforms dense models under multiple experiment settings: instruction-finetuning only and instruction-finetuning followed by task-specific finetuning. This shows that instruction-finetuning is an essential stage for MoE models. Specifically, our largest model, Flan-MoE-32B, surpasses the performance of Flan-PaLM-62B on four benchmarks, while utilizing only one-third of the FLOPs. The success of Flan-MoE encourages rethinking the design of large-scale, high-performance language models, under the setting of task-agnostic learning.
Token Imbalance Adaptation for Radiology Report Generation
Apr 18, 2023



Imbalanced token distributions naturally exist in text documents, leading neural language models to overfit on frequent tokens. The token imbalance may dampen the robustness of radiology report generators, as complex medical terms appear less frequently but reflect more medical information. In this study, we demonstrate how current state-of-the-art models fail to generate infrequent tokens on two standard benchmark datasets (IU X-RAY and MIMIC-CXR) of radiology report generation. % However, no prior study has proposed methods to adapt infrequent tokens for text generators feeding with medical images. To solve the challenge, we propose the \textbf{T}oken \textbf{Im}balance Adapt\textbf{er} (\textit{TIMER}), aiming to improve generation robustness on infrequent tokens. The model automatically leverages token imbalance by an unlikelihood loss and dynamically optimizes generation processes to augment infrequent tokens. We compare our approach with multiple state-of-the-art methods on the two benchmarks. Experiments demonstrate the effectiveness of our approach in enhancing model robustness overall and infrequent tokens. Our ablation analysis shows that our reinforcement learning method has a major effect in adapting token imbalance for radiology report generation.
Conditional Adapters: Parameter-efficient Transfer Learning with Fast Inference
Apr 11, 2023



We propose Conditional Adapter (CoDA), a parameter-efficient transfer learning method that also improves inference efficiency. CoDA generalizes beyond standard adapter approaches to enable a new way of balancing speed and accuracy using conditional computation. Starting with an existing dense pretrained model, CoDA adds sparse activation together with a small number of new parameters and a light-weight training phase. Our experiments demonstrate that the CoDA approach provides an unexpectedly efficient way to transfer knowledge. Across a variety of language, vision, and speech tasks, CoDA achieves a 2x to 8x inference speed-up compared to the state-of-the-art Adapter approach with moderate to no accuracy loss and the same parameter efficiency.
Unsupervised Reinforcement Adaptation for Class-Imbalanced Text Classification
May 26, 2022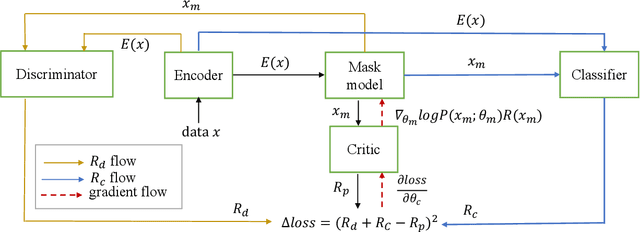
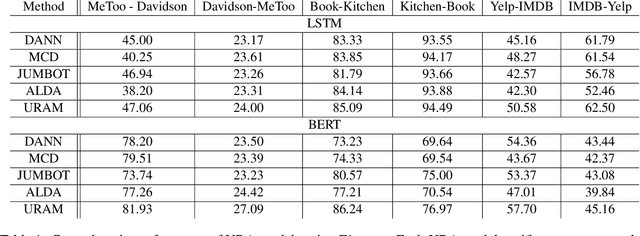
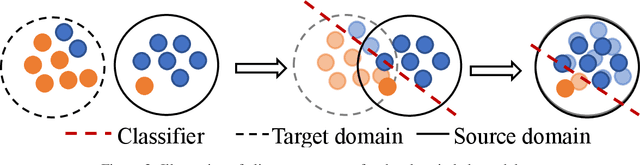
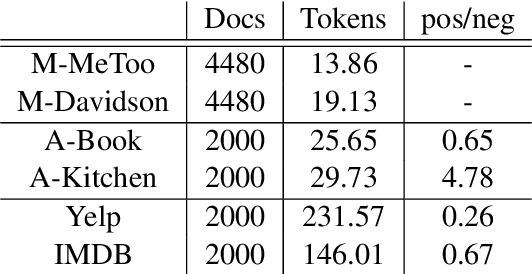
Class imbalance naturally exists when train and test models in different domains. Unsupervised domain adaptation (UDA) augments model performance with only accessible annotations from the source domain and unlabeled data from the target domain. However, existing state-of-the-art UDA models learn domain-invariant representations and evaluate primarily on class-balanced data across domains. In this work, we propose an unsupervised domain adaptation approach via reinforcement learning that jointly leverages feature variants and imbalanced labels across domains. We experiment with the text classification task for its easily accessible datasets and compare the proposed method with five baselines. Experiments on three datasets prove that our proposed method can effectively learn robust domain-invariant representations and successfully adapt text classifiers on imbalanced classes over domains. The code is available at https://github.com/woqingdoua/ImbalanceClass.