 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of retrieval-based QA on QUEST-LOFT
Nov 08, 2025Despite the popularity of retrieval-augmented generation (RAG) as a solution for grounded QA in both academia and industry, current RAG methods struggle with questions where the necessary information is distributed across many documents or where retrieval needs to be combined with complex reasoning. Recently, the LOFT study has shown that this limitation also applies to approaches based on long-context language models, with the QUEST benchmark exhibiting particularly large headroom. In this paper, we provide an in-depth analysis of the factors contributing to the poor performance on QUEST-LOFT, publish updated numbers based on a thorough human evaluation, and demonstrate that RAG can be optimized to significantly outperform long-context approaches when combined with a structured output format containing reasoning and evidence, optionally followed by answer re-verification.
Large Language Models Can Be Easily Distracted by Irrelevant Context
Feb 13, 2023



Large language models have achieved impressive performance on various natural language processing tasks. However, so far they have been evaluated primarily on benchmarks where all information in the input context is relevant for solving the task. In this work, we investigate the distractibility of large language models, i.e., how the model problem-solving accuracy can be influenced by irrelevant context. In particular, we introduce Grade-School Math with Irrelevant Context (GSM-IC), an arithmetic reasoning dataset with irrelevant information in the problem description. We use this benchmark to measure the distractibility of cutting-edge prompting techniques for large language models, and find that the model performance is dramatically decreased when irrelevant information is included. We also identify several approaches for mitigating this deficiency, such as decoding with self-consistency and adding to the prompt an instruction that tells the language model to ignore the irrelevant information.
Large Language Models Encode Clinical Knowledge
Dec 26, 2022Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but the quality bar for medical and clinical applications is high. Today, attempts to assess models' clinical knowledge typically rely on automated evaluations on limited benchmarks. There is no standard to evaluate model predictions and reasoning across a breadth of tasks. To address this, we present MultiMedQA, a benchmark combining six existing open question answering datasets spanning professional medical exams, research, and consumer queries; and HealthSearchQA, a new free-response dataset of medical questions searched online. We propose a framework for human evaluation of model answers along multiple axes including factuality, precision, possible harm, and bias. In addition, we evaluate PaLM (a 540-billion parameter LLM) and its instruction-tuned variant, Flan-PaLM, on MultiMedQA. Using a combination of prompting strategies, Flan-PaLM achieves state-of-the-art accuracy on every MultiMedQA multiple-choice dataset (MedQA, MedMCQA, PubMedQA, MMLU clinical topics), including 67.6% accuracy on MedQA (US Medical License Exam questions), surpassing prior state-of-the-art by over 17%. However, human evaluation reveals key gaps in Flan-PaLM responses. To resolve this we introduce instruction prompt tuning, a parameter-efficient approach for aligning LLMs to new domains using a few exemplars. The resulting model, Med-PaLM, performs encouragingly, but remains inferior to clinicians. We show that comprehension, recall of knowledge, and medical reasoning improve with model scale and instruction prompt tuning, suggesting the potential utility of LLMs in medicine. Our human evaluations reveal important limitations of today's models, reinforcing the importance of both evaluation frameworks and method development in creating safe, helpful LLM models for clinical applications.
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Oct 17, 2022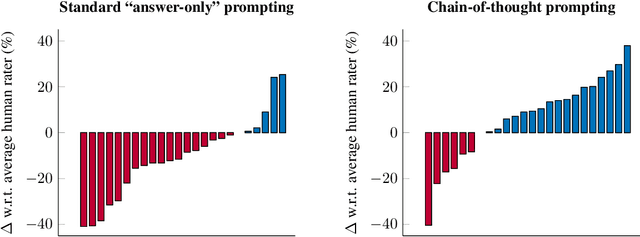

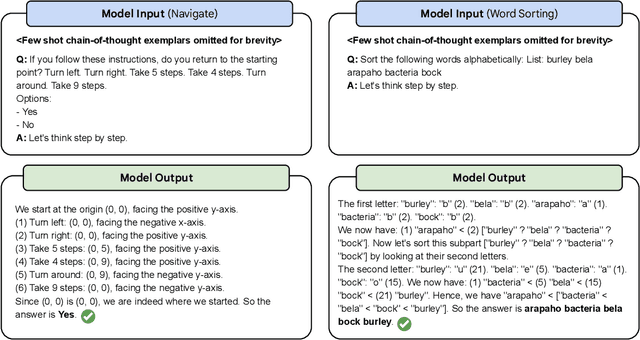
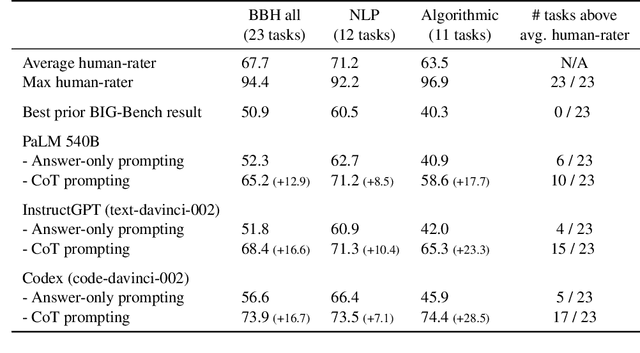
BIG-Bench (Srivastava et al., 2022) is a diverse evaluation suite that focuses on tasks believed to be beyond the capabilities of current language models. Language models have already made good progress on this benchmark, with the best model in the BIG-Bench paper outperforming average reported human-rater results on 65% of the BIG-Bench tasks via few-shot prompting. But on what tasks do language models fall short of average human-rater performance, and are those tasks actually unsolvable by current language models? In this work, we focus on a suite of 23 challenging BIG-Bench tasks which we call BIG-Bench Hard (BBH). These are the task for which prior language model evaluations did not outperform the average human-rater. We find that applying chain-of-thought (CoT) prompting to BBH tasks enables PaLM to surpass the average human-rater performance on 10 of the 23 tasks, and Codex (code-davinci-002) to surpass the average human-rater performance on 17 of the 23 tasks. Since many tasks in BBH require multi-step reasoning, few-shot prompting without CoT, as done in the BIG-Bench evaluations (Srivastava et al., 2022), substantially underestimates the best performance and capabilities of language models, which is better captured via CoT prompting. As further analysis, we explore the interaction between CoT and model scale on BBH, finding that CoT enables emergent task performance on several BBH tasks with otherwise flat scaling curves.
Compositional Semantic Parsing with Large Language Models
Sep 30, 2022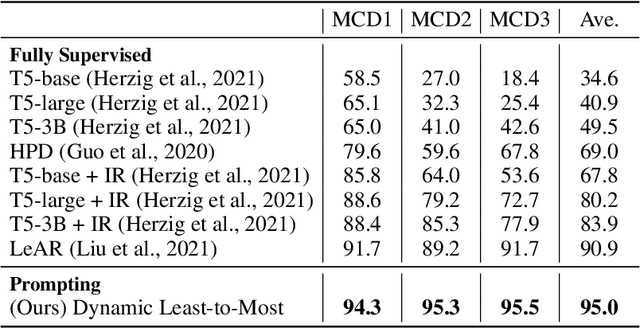
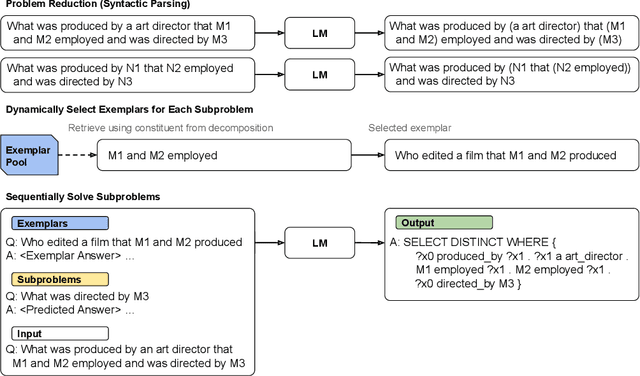
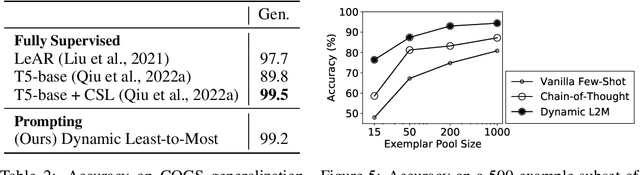
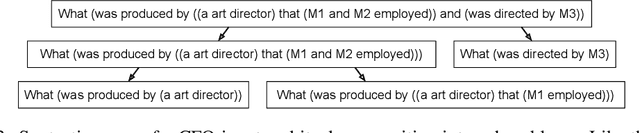
Humans can reason compositionally when presented with new tasks. Previous research shows that appropriate prompting techniques enable large language models (LLMs) to solve artificial compositional generalization tasks such as SCAN. In this work, we identify additional challenges in more realistic semantic parsing tasks with larger vocabulary and refine these prompting techniques to address them. Our best method is based on least-to-most prompting: it decomposes the problem using prompting-based syntactic parsing, then uses this decomposition to select appropriate exemplars and to sequentially generate the semantic parse. This method allows us to set a new state of the art for CFQ while requiring only 1% of the training data used by traditional approaches. Due to the general nature of our approach, we expect similar efforts will lead to new results in other tasks and domains, especially for knowledge-intensive applications.
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
May 21, 2022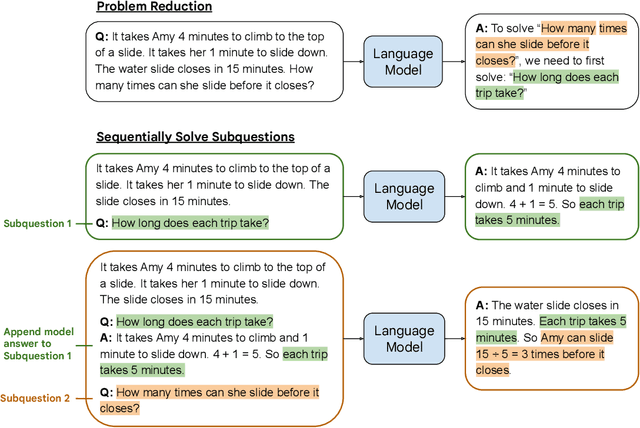



We propose a novel prompting strategy, least-to-most prompting, that enables large language models to better perform multi-step reasoning tasks. Least-to-most prompting first reduces a complex problem into a list of subproblems, and then sequentially solves the subproblems, whereby solving a given subproblem is facilitated by the model's answers to previously solved subproblems. Experiments on symbolic manipulation, compositional generalization and numerical reasoning demonstrate that least-to-most prompting can generalize to examples that are harder than those seen in the prompt context, outperforming other prompting-based approaches by a large margin. A notable empirical result is that the GPT-3 code-davinci-002 model with least-to-most-prompting can solve the SCAN benchmark with an accuracy of 99.7% using 14 examples. As a comparison, the neural-symbolic models in the literature specialized for solving SCAN are trained with the full training set of more than 15,000 examples.
*-CFQ: Analyzing the Scalability of Machine Learning on a Compositional Task
Dec 15, 2020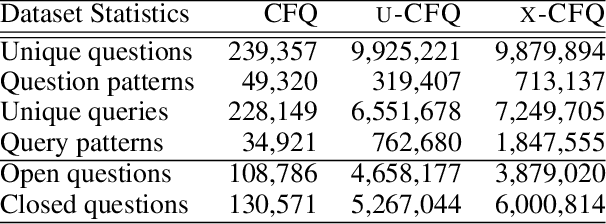
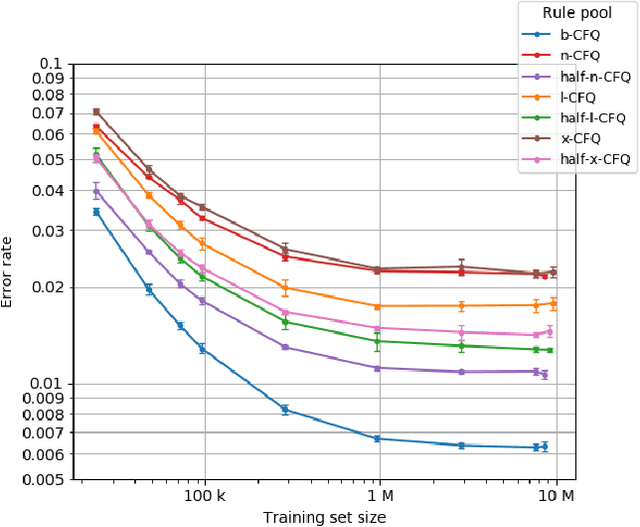

We present *-CFQ ("star-CFQ"): a suite of large-scale datasets of varying scope based on the CFQ semantic parsing benchmark, designed for principled investigation of the scalability of machine learning systems in a realistic compositional task setting. Using this suite, we conduct a series of experiments investigating the ability of Transformers to benefit from increased training size under conditions of fixed computational cost. We show that compositional generalization remains a challenge at all training sizes, and we show that increasing the scope of natural language leads to consistently higher error rates, which are only partially offset by increased training data. We further show that while additional training data from a related domain improves the accuracy in data-starved situations, this improvement is limited and diminishes as the distance from the related domain to the target domain increases.
Compositional Generalization in Semantic Parsing: Pre-training vs. Specialized Architectures
Jul 21, 2020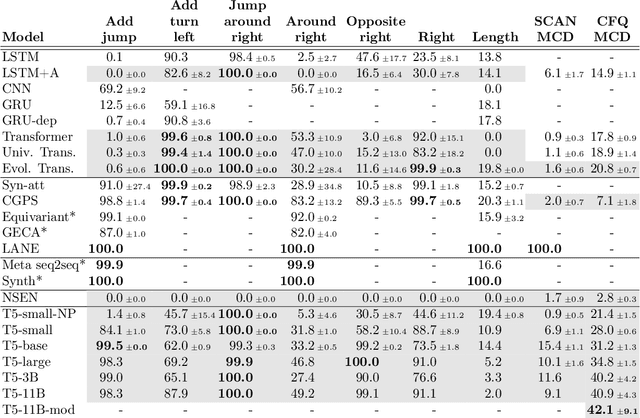
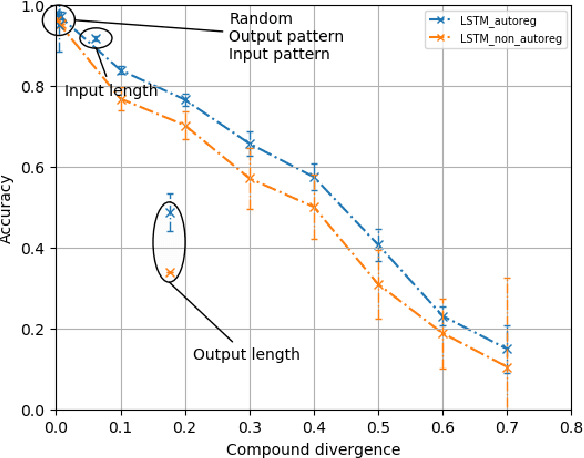
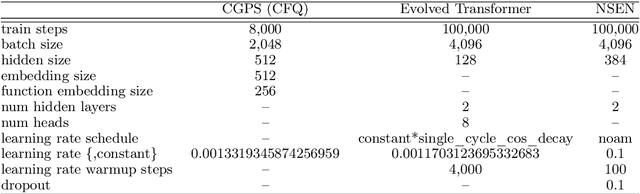
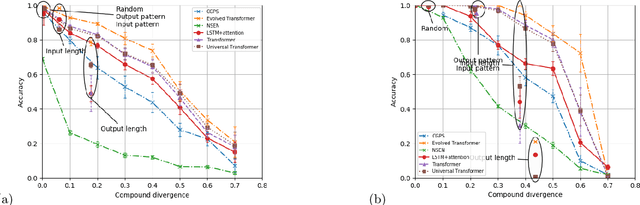
While mainstream machine learning methods are known to have limited ability to compositionally generalize, new architectures and techniques continue to be proposed to address this limitation. We investigate state-of-the-art techniques and architectures in order to assess their effectiveness in improving compositional generalization in semantic parsing tasks based on the SCAN and CFQ datasets. We show that masked language model (MLM) pre-training rivals SCAN-inspired architectures on primitive holdout splits. On a more complex compositional task, we show that pre-training leads to significant improvements in performance vs. comparable non-pre-trained models, whereas architectures proposed to encourage compositional generalization on SCAN or in the area of algorithm learning fail to lead to significant improvements. We establish a new state of the art on the CFQ compositional generalization benchmark using MLM pre-training together with an intermediate representation.
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
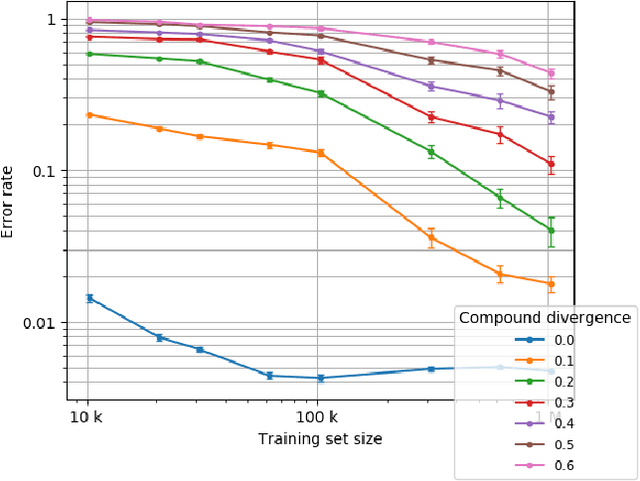
Dec 20, 2019

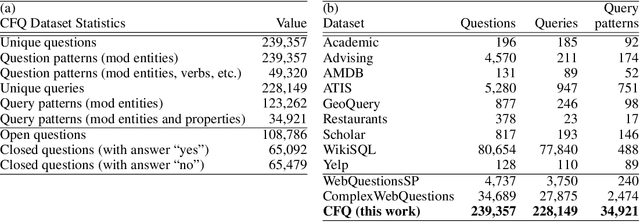
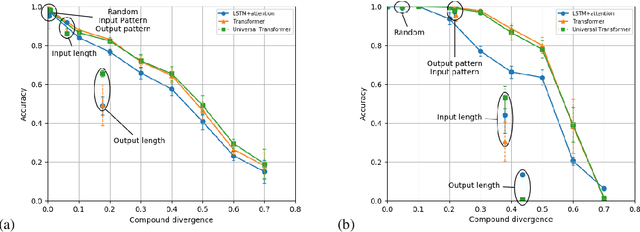
State-of-the-art machine learning methods exhibit limited compositional generalization. At the same time, there is a lack of realistic benchmarks that comprehensively measure this ability, which makes it challenging to find and evaluate improvements. We introduce a novel method to systematically construct such benchmarks by maximizing compound divergence while guaranteeing a small atom divergence between train and test sets, and we quantitatively compare this method to other approaches for creating compositional generalization benchmarks. We present a large and realistic natural language question answering dataset that is constructed according to this method, and we use it to analyze the compositional generalization ability of three machine learning architectures. We find that they fail to generalize compositionally and that there is a surprisingly strong negative correlation between compound divergence and accuracy. We also demonstrate how our method can be used to create new compositionality benchmarks on top of the existing SCAN dataset, which confirms these findings.