 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurst Image Super-Resolution with Mamba
Mar 25, 2025



Burst image super-resolution (BISR) aims to enhance the resolution of a keyframe by leveraging information from multiple low-resolution images captured in quick succession. In the deep learning era, BISR methods have evolved from fully convolutional networks to transformer-based architectures, which, despite their effectiveness, suffer from the quadratic complexity of self-attention. We see Mamba as the next natural step in the evolution of this field, offering a comparable global receptive field and selective information routing with only linear time complexity. In this work, we introduce BurstMamba, a Mamba-based architecture for BISR. Our approach decouples the task into two specialized branches: a spatial module for keyframe super-resolution and a temporal module for subpixel prior extraction, striking a balance between computational efficiency and burst information integration. To further enhance burst processing with Mamba, we propose two novel strategies: (i) optical flow-based serialization, which aligns burst sequences only during state updates to preserve subpixel details, and (ii) a wavelet-based reparameterization of the state-space update rules, prioritizing high-frequency features for improved burst-to-keyframe information passing. Our framework achieves SOTA performance on public benchmarks of SyntheticSR, RealBSR-RGB, and RealBSR-RAW.
Fine-Grained Spatial and Verbal Losses for 3D Visual Grounding
Nov 05, 2024



3D visual grounding consists of identifying the instance in a 3D scene which is referred by an accompanying language description. While several architectures have been proposed within the commonly employed grounding-by-selection framework, the utilized losses are comparatively under-explored. In particular, most methods rely on a basic supervised cross-entropy loss on the predicted distribution over candidate instances, which fails to model both spatial relations between instances and the internal fine-grained word-level structure of the verbal referral. Sparse attempts to additionally supervise verbal embeddings globally by learning the class of the referred instance from the description or employing verbo-visual contrast to better separate instance embeddings do not fundamentally lift the aforementioned limitations. Responding to these shortcomings, we introduce two novel losses for 3D visual grounding: a visual-level offset loss on regressed vector offsets from each instance to the ground-truth referred instance and a language-related span loss on predictions for the word-level span of the referred instance in the description. In addition, we equip the verbo-visual fusion module of our new 3D visual grounding architecture AsphaltNet with a top-down bidirectional attentive fusion block, which enables the supervisory signals from our two losses to propagate to the respective converse branches of the network and thus aid the latter to learn context-aware instance embeddings and grounding-aware verbal embeddings. AsphaltNet proposes novel auxiliary losses to aid 3D visual grounding with competitive results compared to the state-of-the-art on the ReferIt3D benchmark.
Bayesian Self-Training for Semi-Supervised 3D Segmentation
Sep 12, 2024



3D segmentation is a core problem in computer vision and, similarly to many other dense prediction tasks, it requires large amounts of annotated data for adequate training. However, densely labeling 3D point clouds to employ fully-supervised training remains too labor intensive and expensive. Semi-supervised training provides a more practical alternative, where only a small set of labeled data is given, accompanied by a larger unlabeled set. This area thus studies the effective use of unlabeled data to reduce the performance gap that arises due to the lack of annotations. In this work, inspired by Bayesian deep learning, we first propose a Bayesian self-training framework for semi-supervised 3D semantic segmentation. Employing stochastic inference, we generate an initial set of pseudo-labels and then filter these based on estimated point-wise uncertainty. By constructing a heuristic $n$-partite matching algorithm, we extend the method to semi-supervised 3D instance segmentation, and finally, with the same building blocks, to dense 3D visual grounding. We demonstrate state-of-the-art results for our semi-supervised method on SemanticKITTI and ScribbleKITTI for 3D semantic segmentation and on ScanNet and S3DIS for 3D instance segmentation. We further achieve substantial improvements in dense 3D visual grounding over supervised-only baselines on ScanRefer. Our project page is available at ouenal.github.io/bst/.
Scribbles for All: Benchmarking Scribble Supervised Segmentation Across Datasets
Aug 22, 2024



In this work, we introduce Scribbles for All, a label and training data generation algorithm for semantic segmentation trained on scribble labels. Training or fine-tuning semantic segmentation models with weak supervision has become an important topic recently and was subject to significant advances in model quality. In this setting, scribbles are a promising label type to achieve high quality segmentation results while requiring a much lower annotation effort than usual pixel-wise dense semantic segmentation annotations. The main limitation of scribbles as source for weak supervision is the lack of challenging datasets for scribble segmentation, which hinders the development of novel methods and conclusive evaluations. To overcome this limitation, Scribbles for All provides scribble labels for several popular segmentation datasets and provides an algorithm to automatically generate scribble labels for any dataset with dense annotations, paving the way for new insights and model advancements in the field of weakly supervised segmentation. In addition to providing datasets and algorithm, we evaluate state-of-the-art segmentation models on our datasets and show that models trained with our synthetic labels perform competitively with respect to models trained on manual labels. Thus, our datasets enable state-of-the-art research into methods for scribble-labeled semantic segmentation. The datasets, scribble generation algorithm, and baselines are publicly available at https://github.com/wbkit/Scribbles4All
Language-Guided Instance-Aware Domain-Adaptive Panoptic Segmentation
Apr 04, 2024



The increasing relevance of panoptic segmentation is tied to the advancements in autonomous driving and AR/VR applications. However, the deployment of such models has been limited due to the expensive nature of dense data annotation, giving rise to unsupervised domain adaptation (UDA). A key challenge in panoptic UDA is reducing the domain gap between a labeled source and an unlabeled target domain while harmonizing the subtasks of semantic and instance segmentation to limit catastrophic interference. While considerable progress has been achieved, existing approaches mainly focus on the adaptation of semantic segmentation. In this work, we focus on incorporating instance-level adaptation via a novel instance-aware cross-domain mixing strategy IMix. IMix significantly enhances the panoptic quality by improving instance segmentation performance. Specifically, we propose inserting high-confidence predicted instances from the target domain onto source images, retaining the exhaustiveness of the resulting pseudo-labels while reducing the injected confirmation bias. Nevertheless, such an enhancement comes at the cost of degraded semantic performance, attributed to catastrophic forgetting. To mitigate this issue, we regularize our semantic branch by employing CLIP-based domain alignment (CDA), exploiting the domain-robustness of natural language prompts. Finally, we present an end-to-end model incorporating these two mechanisms called LIDAPS, achieving state-of-the-art results on all popular panoptic UDA benchmarks.
2D Feature Distillation for Weakly- and Semi-Supervised 3D Semantic Segmentation
Nov 27, 2023



As 3D perception problems grow in popularity and the need for large-scale labeled datasets for LiDAR semantic segmentation increase, new methods arise that aim to reduce the necessity for dense annotations by employing weakly-supervised training. However these methods continue to show weak boundary estimation and high false negative rates for small objects and distant sparse regions. We argue that such weaknesses can be compensated by using RGB images which provide a denser representation of the scene. We propose an image-guidance network (IGNet) which builds upon the idea of distilling high level feature information from a domain adapted synthetically trained 2D semantic segmentation network. We further utilize a one-way contrastive learning scheme alongside a novel mixing strategy called FOVMix, to combat the horizontal field-of-view mismatch between the two sensors and enhance the effects of image guidance. IGNet achieves state-of-the-art results for weakly-supervised LiDAR semantic segmentation on ScribbleKITTI, boasting up to 98% relative performance to fully supervised training with only 8% labeled points, while introducing no additional annotation burden or computational/memory cost during inference. Furthermore, we show that our contributions also prove effective for semi-supervised training, where IGNet claims state-of-the-art results on both ScribbleKITTI and SemanticKITTI.
Discwise Active Learning for LiDAR Semantic Segmentation
Sep 23, 2023



While LiDAR data acquisition is easy, labeling for semantic segmentation remains highly time consuming and must therefore be done selectively. Active learning (AL) provides a solution that can iteratively and intelligently label a dataset while retaining high performance and a low budget. In this work we explore AL for LiDAR semantic segmentation. As a human expert is a component of the pipeline, a practical framework must consider common labeling techniques such as sequential labeling that drastically improve annotation times. We therefore propose a discwise approach (DiAL), where in each iteration, we query the region a single frame covers on global coordinates, labeling all frames simultaneously. We then tackle the two major challenges that emerge with discwise AL. Firstly we devise a new acquisition function that takes 3D point density changes into consideration which arise due to location changes or ego-vehicle motion. Next we solve a mixed-integer linear program that provides a general solution to the selection of multiple frames while taking into consideration the possibilities of disc intersections. Finally we propose a semi-supervised learning approach to utilize all frames within our dataset and improve performance.
Three Ways to Improve Verbo-visual Fusion for Dense 3D Visual Grounding
Sep 08, 20233D visual grounding is the task of localizing the object in a 3D scene which is referred by a description in natural language. With a wide range of applications ranging from autonomous indoor robotics to AR/VR, the task has recently risen in popularity. A common formulation to tackle 3D visual grounding is grounding-by-detection, where localization is done via bounding boxes. However, for real-life applications that require physical interactions, a bounding box insufficiently describes the geometry of an object. We therefore tackle the problem of dense 3D visual grounding, i.e. referral-based 3D instance segmentation. We propose a dense 3D grounding network ConcreteNet, featuring three novel stand-alone modules which aim to improve grounding performance for challenging repetitive instances, i.e. instances with distractors of the same semantic class. First, we introduce a bottom-up attentive fusion module that aims to disambiguate inter-instance relational cues, next we construct a contrastive training scheme to induce separation in the latent space, and finally we resolve view-dependent utterances via a learned global camera token. ConcreteNet ranks 1st on the challenging ScanRefer online benchmark by a considerable +9.43% accuracy at 50% IoU and has won the ICCV 3rd Workshop on Language for 3D Scenes "3D Object Localization" challenge.
LiDAR Meta Depth Completion
Aug 16, 2023



Depth estimation is one of the essential tasks to be addressed when creating mobile autonomous systems. While monocular depth estimation methods have improved in recent times, depth completion provides more accurate and reliable depth maps by additionally using sparse depth information from other sensors such as LiDAR. However, current methods are specifically trained for a single LiDAR sensor. As the scanning pattern differs between sensors, every new sensor would require re-training a specialized depth completion model, which is computationally inefficient and not flexible. Therefore, we propose to dynamically adapt the depth completion model to the used sensor type enabling LiDAR adaptive depth completion. Specifically, we propose a meta depth completion network that uses data patterns derived from the data to learn a task network to alter weights of the main depth completion network to solve a given depth completion task effectively. The method demonstrates a strong capability to work on multiple LiDAR scanning patterns and can also generalize to scanning patterns that are unseen during training. While using a single model, our method yields significantly better results than a non-adaptive baseline trained on different LiDAR patterns. It outperforms LiDAR-specific expert models for very sparse cases. These advantages allow flexible deployment of a single depth completion model on different sensors, which could also prove valuable to process the input of nascent LiDAR technology with adaptive instead of fixed scanning patterns.
Scribble-Supervised LiDAR Semantic Segmentation
Mar 31, 2022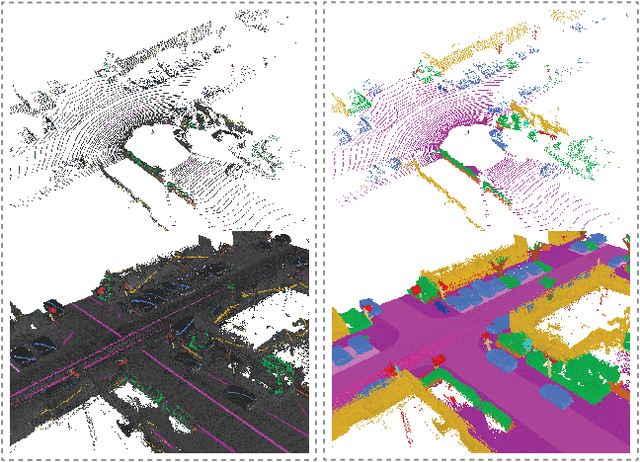
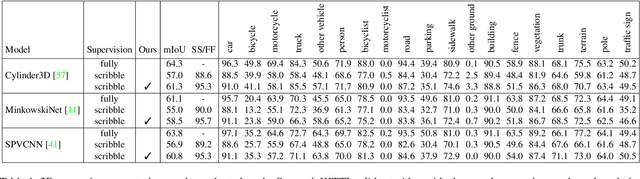
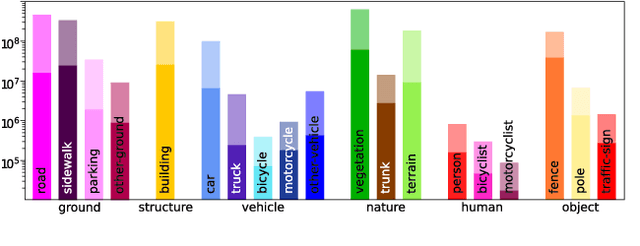
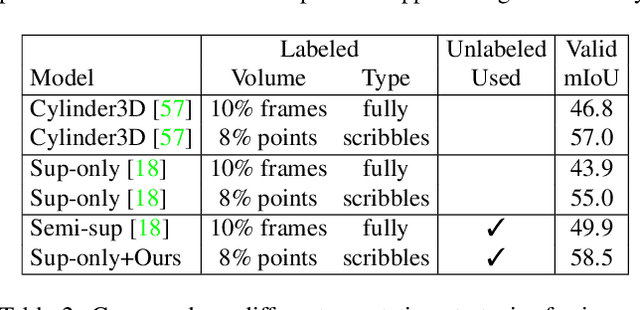
Densely annotating LiDAR point clouds remains too expensive and time-consuming to keep up with the ever growing volume of data. While current literature focuses on fully-supervised performance, developing efficient methods that take advantage of realistic weak supervision have yet to be explored. In this paper, we propose using scribbles to annotate LiDAR point clouds and release ScribbleKITTI, the first scribble-annotated dataset for LiDAR semantic segmentation. Furthermore, we present a pipeline to reduce the performance gap that arises when using such weak annotations. Our pipeline comprises of three stand-alone contributions that can be combined with any LiDAR semantic segmentation model to achieve up to 95.7% of the fully-supervised performance while using only 8% labeled points. Our scribble annotations and code are available at github.com/ouenal/scribblekitti.